
OmniFill: Domain-Agnostic Form Filling Suggestions Using
Multi-Faceted Context
Timothy J. Aveni
tja@berkeley.edu
University of California, Berkeley
Berkeley, California, USA
Armando Fox
fox@berkeley.edu
University of California, Berkeley
Berkeley, California, USA
Björn Hartmann
bjoern@berkeley.edu
University of California, Berkeley
Berkeley, California, USA
Prior examples
Current browsing context
Text field structure
Fill suggestions
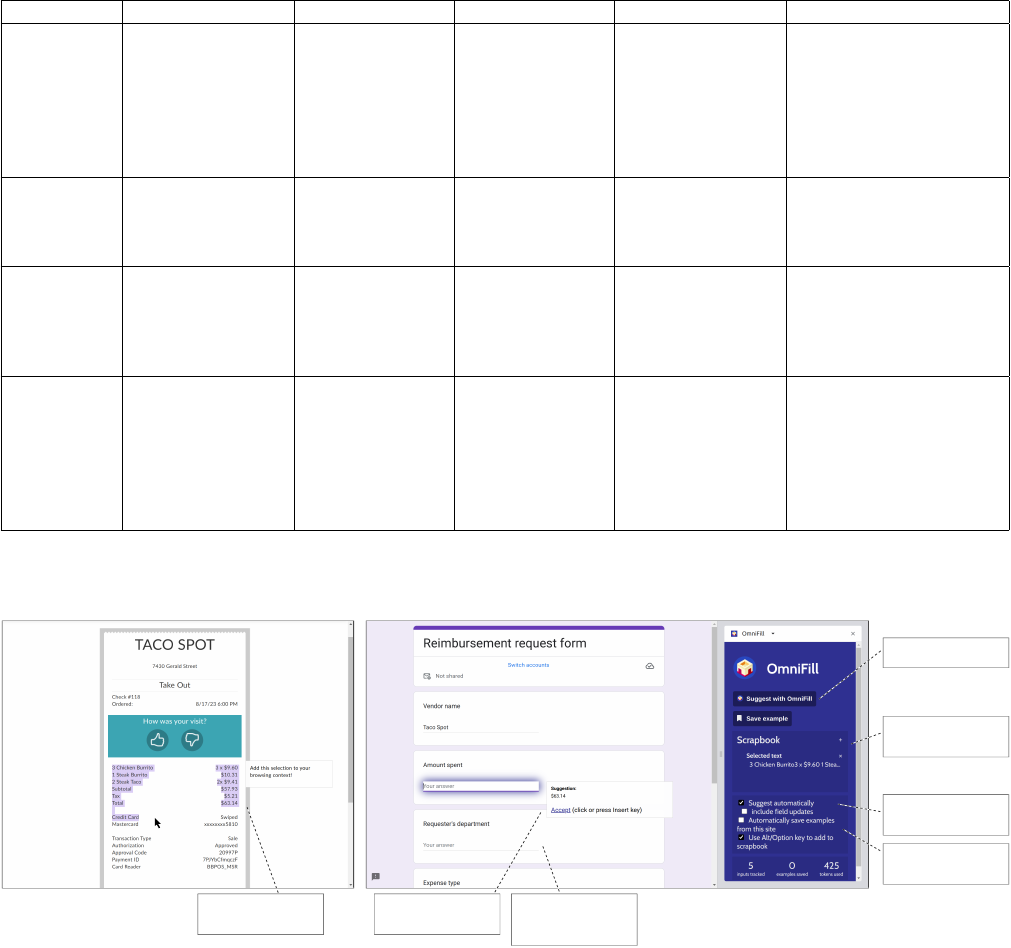
… receipt for your credit card
transaction at TACO SPOT …
purchase total: $64.13 …
Vendor
Department
Amount
Reimbursement Request
Purchase Receipt
Vendor
Department
Amount
Reimbursement Request
CS
Taco Spot
64.13
++
LLM
Prompt
Figure 1: OmniFill oers domain-agnostic suggestions for Web forms using a multi-faceted prompt to a large language model.
ABSTRACT
Predictive suggestion systems oer contextually-relevant text en-
try completions. Existing approaches, like autoll, often excel in
narrowly-dened domains but fail to generalize to arbitrary work-
ows. We introduce a conceptual framework to analyze the com-
pound demands of a particular suggestion context, yielding unique
opportunities for large language models (LLMs) to infer suggestions
for a wide range of domain-agnostic form-lling tasks that were
out of reach with prior approaches. We explore these opportunities
in OmniFill, a prototype that collects multi-faceted context includ-
ing browsing and text entry activity to construct an LLM prompt
that oers suggestions in situ for arbitrary structured text entry
interfaces. Through a user study with 18 participants, we found
that OmniFill oered valuable suggestions and we identied four
themes that characterize users’ behavior and attitudes: an “oppor-
tunistic scrapbooking” approach; a trust placed in the system; value
in partial success; and a need for visibility into prompt context.
CCS CONCEPTS
• Human-centered computing
→
User interface design; Web-
based interaction; Natural language interfaces; Text input.
KEYWORDS
large language models, intelligent user interfaces, form lling,
context-awareness, Web automation
1 INTRODUCTION
A signicant but tedious part of information work consists of taking
textual information from one source, and manually moving it into
arXiv Preprint, October 2023
structured online forms - either through direct copy and paste, or
through reformatting or rewriting. Examples include extracting
information from a purchase receipt into a reimbursement form
(see Figure 1), adding events from the Web to a personal calendar,
or transforming the format of existing form eld values in-place. In
these tasks, users are asked to laboriously serve as human “glue”,
often between dierent siloed systems. Prior research has identied
this problem and proposed several approaches to oer contextually-
relevant form completions [
7
,
19
,
37
,
42
]. One limitation of these
prior approaches is that they often only apply in narrowly dened
domains. In particular, the choice of implementation approach,
e.g., programming-by-demonstration [
28
] or document mining [
9
]
enables some tasks, but precludes others.
In this paper, we rst contribute a framework for characterizing
the form lling task. We describe four major dimensions – infor-
mation demands, operation complexity, structure variability, and
task specication. This analysis yields unique novel opportunities
for LLMs to produce form lling suggestions for a wide range of
tasks that were out of reach with prior approaches. In particular,
we posit that LLMs are suitable for operating on a multi-faceted
“bag of context” that can contain both prior demonstrations (as in
programming by demonstration), as well as explicitly marked con-
tent (text agged by the user as important) and implicitly collected
content (history such as search queries and user behavior in the
form).
We explore this research hypothesis with OmniFill, a new proto-
type system that collects multi-faceted context including browsing
and text entry activity; constructs an LLM prompt with that content;
and then oers suggestions in situ for arbitrary structured form
interfaces. We demonstrate the promise of this approach through
several example applications, and we examine utility through a
study with 18 participants. Through an analysis of users’ behaviors
arXiv:2310.17826v1 [cs.HC] 27 Oct 2023
arXiv Preprint, October 2023 Aveni et al.
and attitudes during the user study tasks, we propose considera-
tions that system designers should keep in mind when building
this type of domain-agnostic suggestion system for use in the real
world.
2 RELATED WORK
The most closely related prior work falls into three areas: 1) au-
tomating interaction with Web pages in general; 2) form-lling
interfaces in particular; and 3) other predictive text tools. In addi-
tion, OmniFill is related to a rapidly growing set of user interfaces
that use LLMs as backends. We discuss each in turn.
2.1 Automating Interactions with Web Pages
Research has investigated several ways for automating tedious or
repetitive interactions in Web pages beyond suggesting or lling
forms.
One line of work uses end-user programming to record demon-
strations of Web page interactions, generalize these demonstrations
into a program in a suitable DSL, and then let others replay this
program later in a related but dierent context. Key tasks enabled
by programming-by-demonstration have been sharing multi-step
processes (e.g., Koala [
28
], later CoScripter [
25
]) and Web scraping
(e.g., Ringer [
5
], Rousillon [
14
]). A source of complexity in these
systems is that Web pages may be interactive, their structure may
be ill-formed, and they may change over time; more recent work has
succeeded in using natural language processing techniques to make
task specications more robust and exible (e.g. DiLogics [35]).
Some other approaches to automation rely on pixel-based reverse
engineering of rendered interfaces (Prefab [
16
], Sikuli [
44
]), apply-
ing computer vision techniques to derive interface structure. The
combination of DOM and visual features can surpass the limitations
of these individual approaches [24].
OmniFill is not addressing general Web automation, focusing
instead only the narrower problem of suggesting text in Web form
elds. However, it can draw on broader context than just prior
demonstrations. While demonstrations are part of the context con-
sidered by OmniFill, the system also takes into account other sources
of context explicitly and implicitly collected (e.g., text identied as
important by the user), and world knowledge (as captured in the
pre-trained LLM).
2.2 Automatic Form Filling
OmniFill is inspired by prior mixed initiave systems such as Look-
Out [
20
] and Citrine [
37
], which also seek to reduce the tedium
of manually completing forms with information that already ex-
ists in some other format. LookOut extracted information from
email to pre-populate calendar events. Citrine parsed users’ copied
text into typed elds using hand-constructed parsers for frequent
content such as addresses, and could then auto-complete dierent
address elds based on recognizing the structure of the form from
prior demonstrations. Related interaction techniques such as Entity
Quick Click also rely on entity recognition in copied text to accel-
erate copy and paste tasks [
8
]. OmniFill extends this work by using
an LLM and multiple sources of context to broaden the applicability
of Citrine’s approach without requiring manually authored parsers
for each type of data.
A number of technical approaches have been proposed to ex-
tract information from a larger document or corpus for the purpose
of form lling, e.g. hidden Markov models [
12
], or discriminative
context free grammars [
40
]. Prior work using ML approaches has
constructed direct mappings between observed user context and
form elds using NLP techniques (e.g. [
19
]) or constructed domain-
specic models of form dependencies (e.g. [
7
]). Because foundation
language models, as used in OmniFill, can operate across many
tasks and domains [
10
], they hold the promise of potentially obviat-
ing domain-specic recognizers and expanding task specications
beyond eld-by-eld extractions of suggestions from context.
2.3 Predictive Text Completion
Form lling is a special case of the larger problem of predictive text
completion which seeks to predict, given some context of existing
text, what text a user is likely to enter next.
Predictive Text Completion has existed for a long time in code
editors [
39
], search query interfaces [
6
,
30
], and predictive key-
boards [
23
]. More recently, language models have found widespread
use completion suggestions in email composition [
18
], and for larger
code chunks [
31
]. In addition to research on the underlying tech-
nologies, researchers are also studying the impact of the use of
predictive text interfaces on productivity [
33
,
46
], on the content of
text being produced [
4
], and on users’ perceptions of their tasks [
21
].
While we restrict our focus in this paper to form lling, our con-
ceptual framework and our multi-faceted context structure can
potentially be applicable for analyzing a broader set of predictive
tasks.
2.4 Novel Interfaces Enabled by LLMs
Researchers are increasingly investigating the utility of pre-trained
language models for enabling new interactions. One key distinction
is between systems that use LLMs to enable natural language based
input on one hand; and systems that use LLMs as an enabling
implementation technology for novel direct manipulation or other
types of interactions.
As examples of the rst category, Wang et al. show that LLMs are
promising for enabling conversational interactions with mobile user
interfaces [
41
], such as screen summarization and screen question
asking. Stylette [
22
] enables re-design of Web pages through natural
language commands. In the second category, user interactions are
translated into appropriate prompts to a language model “behind
the scenes” to oer better performance or novel capabilities beyond
previous algorithmic approaches. Examples are TaleBrush [
15
],
which allows users to sketch story arcs to condition the co-creation
of stories with LLMs, and SayCan [
3
], which uses LLMs to map
real-world robot aordances to relevant situations.
OmniFill does not directly expose text interactions with the un-
derlying LLM, instead oering a user-facing interaction closer to
traditional brower autoll. Still, the use of an LLM as implemen-
tation technology enables the system to perform many natural
language tasks that are implicitly used in form lling, such as ex-
tracting entities from context and making use of form eld labels.
OmniFill: Domain-Agnostic Form Filling Suggestions Using Multi-Faceted Context arXiv Preprint, October 2023
3 TASK DIMENSIONS
A form-lling task is a related series of operations intended to
gather, process, and enter information into a form. Form-lling
tasks can manifest in many shapes, and each task has its own
multidimensional requirements necessary of a system that is able
to automatically suggest or complete eld values for the task.
To assist in articulating the space of tasks that may be handled
eectively by an LLM-backed system, we consider four relevant
dimensions to describe form-lling tasks: information demands,
operation complexity, structure variability, and task specication.
3.1 Information demands
What information is being placed into the form? Where does it come
from? In a predictive system, what information may be transcribed,
transformed, or used as a retrieval key for the system’s current
suggestion or completion?
We identify six broad classes of such information.
Historical user behavior
What information has the user en-
tered into the form or similar forms in the past? Example:
browsers oer dropdown suggestions for recognized elds,
even in previously-unseen forms.
Explicitly-foregrounded information
Users may explicitly
call attention to information outside the target form interface.
Example: importing a CSV into a system, or the “select, then
copy” operation of a clipboard.
Implicit browsing context
User activity may provide addi-
tional context relevant to the task even if not explicitly fore-
grounded. Example: scrolling through the subject lines of an
email inbox.
Current form state
Some form lling operations make use of
information already present in the form. Example: creating
a username based on the values of a “First name” and “Last
name” eld.
External general knowledge or language knowledge
Some
information inserted into forms comes from the surround-
ing world, especially in combination with other information
sources. Example: after typing “Paris” in a “City” eld, a
system may oer “France” for the “Country” eld.
User-specic external knowledge
User-specic information
may come from sources other than form-lling activity or
recent browsing context. Example: a system may oer com-
pletions based on the data from the user’s phone contacts.
3.2 Operation complexity
What transformations must be applied to inputted information by
either the user or a predictive system making eld suggestions?
Exact transcription
An entire input is transcribed verbatim
into the output eld. Example: a user copies a URL into their
clipboard, and their mobile browser address bar oers to
“paste” that full URL.
Literal extraction
Information (in any of the forms described
in Section 3.1) is transcribed verbatim into the target form
but must rst be extracted from some larger source.
Format transformation
Information must be transformed
into a dierent format. Example: a task requires a name
to be converted from all-caps (as it appears in the source) to
title case (as required by the target form).
Quantitative transformation
The task demands arithmetic
operations to be performed on available information before
inserting into the target form.
Semantic transformation
The task requires a transforma-
tion of the available information that produces an output
that is syntactically and structurally distinct from the input
information but still semantically related. Example: upon
viewing an email reading, “I don’t eat meat, but I can eat
animal products like cheese”, the user might write “Vegetar-
ian” into the target form to match the format of other form
responses.
3.3 Structure variability
When the task consists of multiple instances of a form being lled,
how does the task vary between form lls? Once the task is well-
specied, how exible does that specication need to be to handle
the source and target structures?
Fixed source structure
Does information used to derive eld
values come from the same place, in the same format, from
case to case? An example of a task with xed information
source structure is one in which information is sourced from
a spreadsheet and each row of the sheet is used to construct
a submission in the target form.
Varied source structure
An example task with varied infor-
mation source structure is the information-gathering task
from our user study, in which users repeatedly ll the same
form but with information from a dierently-structured web-
site for each submission of the target form.
Fixed target structure
Is information always inserted into
the same eld of the same form, or can each submission
to a form take a dierent structure? Any task involving
repeated submissions to the same form has a xed target
eld structure.
Varied target structure
An example of a task with varied tar-
get eld structure is lling out many distinct job applications;
although the information being lled is mostly the same from
submission to submission, the form structure (and in some
cases, the demanded information format) changes each time
a form is lled.
3.4 Task specication
What information is available that species the process of com-
pleting the task? If a user is completing the task manually, how
much understanding of the task might be gleaned by someone
looking over their shoulder? These specications are distinct from
the information demands described in Section 3.1, which refers to
information that may be actually entered into the form (potentially
after a transformation) or used to reference other information to
be entered into the form.
Implicit specication
Task specications may be implied by
the structure of collected context or target form. For exam-
ple, a user who copies an address and visits a form with an
address eld likely intends to insert that address into the

arXiv Preprint, October 2023 Aveni et al.
Task context Form field Expected field value
Exact transcription
$63.14
Total price: Total price:
$63.14
Literal extraction
...Subtotal: $57.93\nTotal:
$63.14\nThank you for shoppi...
Total price: Total price:
$63.14
Format transformation
TACO SPOT
Vendor: Vendor:
Taco Spot
antitative transformation
4x burrito, 2x taco
Purchase quantity: Purchase quantity:
6
Semantic transformation
4x burrito, 2x taco
Expense type: Expense type:
food
Figure 2: Illustrations of various categories along the operation complexity dimension.
target form. This structural information may take a machine-
readable form (as with the
autocomplete
attribute in HTML)
or natural language forms (as with text description labels on
elds).
Instructions
Tasks can be specied with form-lling instruc-
tions, present in, for example, the form or browsing context.
Instructions may be precise and machine-readable, as with
tasks specied using code or macro software. They may also
come in the form of natural language, which may leave gaps
in the specication.
Examples
Many tasks can be approximately specied using a
number of examples, as demonstrated in the programming-
by-example literature. When prior examples of user behavior
are available, approximate task specications can be inferred
and realized in synthesized code. Examples may also help to
clarify ambiguities in vague instruction-based specications.
3.4.1 Specification visibility and mutability. In a predictive system
oering form-lling suggestions, allowing the user to see and ma-
nipulate the specication can enable renement to improve future
suggestions. This can happen by manually constructing or deleting
examples, or by modifying instructions, when they are present
and in a form that the user is comfortable manipulating. Many
programming-by-example techniques produce a readable or ma-
nipulable code specication as an artifact, rather than keeping the
specication as a hidden implementation detail [13, 14].
Specication renement need not be driven by the user complet-
ing the task. If predictive systems can detect incomplete specica-
tions or present the user with anomalous saved examples, they can
take initiative in asking the user to clarify the task specication
(as discussed in [
20
,
29
]), just as another person looking over the
user’s shoulder might.
4 TOOL CAPABILITIES
To situate OmniFill among prior form-lling tools, we analyze the
capabilities of existing tools with respect to the space of tasks they
are capable of handling, as shown in Figure 3.
First, we consider typical Web browser autoll behavior, which
matches form elds to prior values entered into similar elds by
the user. Then, we compare to LookOut [
20
], a tool for Microsoft
Outlook that oers automated scheduling services based on the
contents of users’ emails. By comparing Citrine, an “intelligent copy-
and-paste” tool [
37
], we introduce a tool that can detect information
from certain known schemas in exible information sources. Then
we consider DiLogics [
35
], a programming-by-demonstration tool
that enables automated form lling from an imported CSV and
synthesizes an explicit specication from existing examples.
Implementation approaches in this prior work constrain the
types of task that can be performed. First, each approach oers a
structure that privileges some forms of information over others,
rather than allowing information sources to vary based on the
task demand. Second, prior approaches cannot perform semantic
transformations without domain-specic processors in place. Many
prior systems are also locked to repeating source or target struc-
tures, rather than supporting tasks with exible needs. Systems that
require heavy specication, though valuable for full automation,
cannot quickly make lightweight inferences of approximate details
or implicit specications in exible contexts.
Pre-trained foundation language models may be uniquely suit-
able to address these shortcomings: as long as relevant context
information can be brought into the system as text, dierent types
of information can be mixed in a single prompt. LLMs also oer
semantic transformation capabilities, and the world knowledge cap-
tured by models during their pre-training may give them the power
to adapt to arbitrary tasks seen by users. We therefore built OmniFill
with an LLM backend, seeking to cover many possible information
demands, a range of operation complexity types, exible source
and target structure, and exibly-dened task specications. Not
every task is well-suited to LLMs (e.g. because of limited context
window size or poor arithmetic skills), but even these shortcomings
may be ameliorated using targeted techniques developed by AI
researchers [27, 36, 43].
OmniFill: Domain-Agnostic Form Filling Suggestions Using Multi-Faceted Context arXiv Preprint, October 2023
Browser autoll LookOut Citrine DiLogics OmniFill
Information
demands
Historical user
behavior, Current
form state
Implicit browsing
context
Explicitly-
foregrounded
information
Historical user
behavior, Explicitly-
foregrounded
information
Historical user behavior,
Explicitly-foregrounded
information, Implicit
browsing context, Current
form state, External general
knowledge or language
knowledge
Operation
complexity
Exact transcription
Exact transcription,
Literal extraction,
Format
transformation
Exact transcription,
Literal extraction,
Format
transformation
Exact transcription,
Literal extraction,
Format
transformation
Exact transcription, Literal
extraction, Format
transformation, Semantic
transformation
Structure
variability
Fixed source
structure, varied
target structure
Fixed source
structure, xed
target structure
Varied source
structure (only in
known schemas),
varied target
structure
Fixed source
structure (data
import), varied
target structure
Varied source structure,
varied target structure
Task speci-
cation
N/A (xed to tasks
handled by the
system)
N/A (xed to tasks
handled by the
system)
N/A (xed to tasks
handled by the
system)
Instructions (natural
language),
Synthesized
instructions (code),
Examples,
Visible/mutable
specication
Implicit specication
(natural language),
Instructions (natural
language), Examples
Figure 3: Task requirements supported by browser autoll, LookOut, Citrine, DiLogics, and OmniFill.
Collect context
Accept suggestions
Users can manually invoke
OmniFill for a particular form.
The Scrapbook lets users see
which context has been
collected for this form fill.
Users may also configure
OmniFill to be automatically
invoked for the active form.
OmniFill can be configured to
save examples automatically
when the form is submied.
By holding Alt and selecting
text, users can add context to
their scrapbook.
Upon invocation, OmniFill
generates suggestions for
fields in the web form.
OmniFill sometimes won't
make a suggestion for every
field, depending on what's in
the bag of context.
Figure 4: OmniFill’s browser extension. Users can select text on the Web to add to their scrapbook, then invoke the system to
obtain suggestions for any Web form. A sidebar on the right of the browser controls the scrapbook, invocation, and conguration.
5 INTERACTION DESIGN AND
IMPLEMENTATION
5.1 System architecture
OmniFill consists of two local components, a browser extension
and local server both implemented in TypeScript, and a connection
to a remote LLM server with a “chat completion” generation API.
Together, these components enable a streamlined interaction
ow, depicted in the system screenshots in Figure 4, oering users
low-friction interactions to foreground relevant context, invoke
OmniFill’s backend to oer completion suggestions, and show the
system examples of the form-lling task. This all occurs in situ,
requiring no task-specic conguration and minimal interaction
outside the context sources and target form already in use.
5.1.1 Browser extension. OmniFill includes a sidebar as part of its
Web browser extension, which contains a preview of the contents

arXiv Preprint, October 2023 Aveni et al.
Browser extension
Sidebar
▪ Scrapbook view
▪ Action buons
▪ Configuration
options
Content script
▪ Form field detection
▪ Google search detection
▪ Context selection
▪ Suggestion presentation
▪ ‘Auto-save examples’ detection
Background script
Local server
▪ Source of truth for bag of context
▪ Persistence
▪ Operating system text entry bridge
▪ LLM prompt generation
Request cache
LLM API server
Remote gpt-3.5-turbo host
Figure 5: OmniFill’s underlying architecture, including the
browser extension, local server, and remote API server.
of the “scrapbook.” The scrapbook contains browsing context ob-
served by OmniFill, including Google searches, text from Web pages
added to the scrapbook, and any text manually added through the
sidebar’s add-to-scrapbook button (which presents a free-form text
eld that users can paste or type text into). Users can delete indi-
vidual scrapbook entries from the scrapbook but not view the full
scrapbook contents or make in-place updates to collected context.
The sidebar also includes two action buttons: “Suggest with
OmniFill”, which invokes the LLM to make predictive suggestions
for the currently-focused Web page, and “Save example”, which
captures the current scrapbook contents as well as the current
page’s form structure to save into the “Prior examples” section of
OmniFill’s bag of context, then clears the scrapbook in preparation
for the next form-lling example.
The sidebar also contains conguration options such as Om-
niFill’s automatic invocation mode (which can update suggestions
when the scrapbook changes or form elds are modied) and its
automatic example-saving feature, which attempts to detect form
submissions and saves examples automatically.
OmniFill’s browser extension also injects JavaScript into each
visited Web page, responsible for collecting context from the Web
and from user activity. Users may select text while holding the Alt
(or Option) key on their keyboard, which adds the selected text
to OmniFill’s bag of context. In addition, Google search queries
are automatically added to the context. The injected script also
synchronizes the current page’s form eld structure, including
initial eld values and updates made by the user to the elds, to the
rest of the system. Form elds have their names inferred through
a variety of methods; rst, OmniFill attempts to read the elds’
accessible names (e.g.
aria-label
s), falling back to nearby visible
text if necessary. If the automatic example-saving feature is enabled
for a particular site, this injected script listens for form submissions
or clicks on buttons labeled “Save” or “Submit” and invokes the
example-saving routine. This technique may not generalize to all
websites, so users may need to click the “Save example” button
manually before making form submissions; in our user study, this
technique was sucient to save examples automatically.
When OmniFill has suggestions for the user, the injected script
seeks out the associated form elds in the page by their inferred
name, highlights them with a purple outline, and oers a small
suggestion box when focusing elds whose suggested value diers
from the current value.
5.1.2 Local server. OmniFill’s browser extension coordinates with
a local server program running on the computer. This separate
server simulates key presses when OmniFill needs to type into a
text eld. In addition, this server acts as the single source of truth
for OmniFill’s current bag of context, and this is persisted to the
user’s computer in case the browser or server is closed. When
OmniFill is ready to make a request to the LLM, this local server
generates a prompt, computing the number of tokens used by the
prompt and pruning examples and scrapbook contents if necessary
until the prompt is suciently short to t in the model’s context
window. Responses are cached by the local server so that only
unique requests are made to the LLM API.
5.1.3 LLM API. OmniFill makes requests to OpenAI’s
gpt-3.5-turbo-0613
model, choosing between the 4,096-
token context length model and the 16,384-token model based
on the size of the prompt. The model is queried at temperature
0, oering nearly deterministic results for a particular prompt.
Responses are piped from the local server back to the browser
extension, which presents any suggestions back to the user.
5.2
Serializing the “bag of context” into an LLM
prompt
To allow the system to make useful inferences in varied situations,
OmniFill constructs a prompt containing three main facets of task
context (visualized in Figure 6):
•
Current browsing context, representing context explicitly
inserted into OmniFill’s scrapbook by the user as well as
implicitly-observed Google searches.
•
Form structure state, including the inferred name for each
form eld, the initial value of each form eld, and any edits
made by the user to each form eld’s value.
•
Prior examples saved by the user, each including browsing
context, form structure, and the intended nal form state
before saving the form.
This prompt structure is designed to support many broad tasks
without requiring task-specic conguration. Some tasks may pri-
marily use only one or two of these context facets, and others may
combine information from all three. Depending on the task, these
context facets may all contain information demands of the task,
and they may all contain information that helps OmniFill infer and
carry out a task specication, so all three facets are included in each
prompt to the LLM.
5.2.1 Current browsing context. All information present in the
“scrapbook” in OmniFill’s sidebar will be included in this section of
the prompt, referred to internally as
"user action context"
. This

OmniFill: Domain-Agnostic Form Filling Suggestions Using Multi-Faceted Context arXiv Preprint, October 2023
Assistant messages User messages
{
"user action context": [ ... ],
"template with initial values": { ... },
"changes made by user so far": { ... }
}
Fill in the template JSON, using...
{ ... }
{ ... }
{
"user action context": [ ... ],
"template with initial values": { ... },
"changes made by user so far": { ... }
}
Fill in the template JSON, using...
{ ... }
{
"Vendor name": "Hawaiian Airlines",
"Amount spent": "$401.13",
"Requester's department": "CS",
"Expense type": "travel",
"Total purchase quantity": "1"
}
Prior examples
{
"user action context": [
{
"type": "text selection",
"page title": "Your Receipt for TACO SPOT",
"before": "...Subtotal$57.93\nTa",
"selection": "x$5.21\nTotal$63.14\n\nCre",
"after": "dit Card..."
}
],
"template with initial values": {
"Vendor name": "",
"Amount spent": "",
"Requester's department": "",
"Expense type": "",
"Total purchase quantity": ""
},
"changes made by user so far": {
"Vendor name": "Taco Spot",
}
}
Fill in the template JSON, using the provided context as
appropriate. Return a JSON object with every key from the
template. If a field should be updated, include a string
with the new value. Otherwise, include the boolean false
value. The blank template is as follows:
{
"Vendor name": "",
"Amount spent": "",
"Requester's department": "",
"Expense type": "",
"Total purchase quantity": ""
}
Current form fill context
{
...
}
Model
response
Figure 6: The structure of the prompt generated by a sin-
gle invocation of OmniFill for
gpt-3.5-turbo
. Some details
are omitted from prior examples. In addition, OmniFill ex-
pands selection context by 500 characters in each direction.
Highlighted in purple are details about the browsing context
(Section 5.2.1); in green is form structure state (Section 5.2.2),
and in orange is the output format (Section 5.2.4).
includes a description of Google searches made by the user, context
added manually through the sidebar’s “add context” button, and
context added by selecting text on Web pages. When text is selected
on Web pages, 500 characters before and after the user’s selection
are also included in the prompt (separated, so that the prompt
includes information about which text was actually selected). In
addition, the page’s title (as shown in the browser tab header) is
included.
5.2.2 Form structure state. For the LLM to return results in a usable
format, the prompt needs to contain a full list of the text elds on
the target Web page. The prompt also includes the initial value
of each eld and a list of the eld updates that the user has made
since those initial values were retrieved; this provides context on
how the user has engaged with the form so far, which can, for
example, allow the system to make suggestions for the second half
of a form after the user has given the system indications of their
intent through edits made to the rst half of the form. The “initial”
value of each eld is computed either at page load time or the time
the form structure last changed, whichever came later – this enables
the prompt to “start fresh” in situations where form submission
does not reload the page but instead adds new elds to the page
(e.g. when clicking a button to add a new row to a spreadsheet-style
form).
In practice, we discovered that, if some elds had already been
updated by the user, the system sometimes would not oer sugges-
tions for the remainder of the form, instead making only suggestions
that armed what the user had already input. In the OmniFill pro-
totype, we make two parallel requests to the model: one request as
described in this section, and a secondary request with any current
user edits suppressed (but the initial eld values still present), using
responses from the second prompt only as a fallback when a eld
did not have a suggestion from the rst prompt. In the information-
gathering task of our user study (described in section 6.1), 38 of 418
(= 9%) of model completions had at least one eld suggestion made
by this metric that would have been left blank or unchanged if not
for this secondary parallel request.
5.2.3 Prior examples. Because
gpt-3.5-turbo
is a “chat comple-
tion” model, we can model prior examples as previous “exchanges”
with the model by including past prompts (as described in the prior
two subsections) as a “user message” and the desired output of the
LLM (the example’s nal form state, as saved by the user) as an
“assistant response”, including nal values for each eld in the re-
sponse. The prompt does not include actual prior model responses
for previous requests, only the nal eld values saved by the user in
the “assistant response”. By saving examples, especially when lling
the same form repeatedly, users can demonstrate their process to
OmniFill. Even when OmniFill does not successfully extract mean-
ingful names from the elds in the target form, we have observed
that a small number of examples can suce to begin specifying the
form-lling task.
5.2.4 Output format. A simple structure for the requested output
format (which is duplicated in the prompt’s “assistant message”
for each example) is a JSON object with a key for every eld in
the target Web form and a value equaling the system’s suggestion
for that eld. By requesting suggestions for the entire form in one
query (rather than requesting each eld’s suggestion separately, in
parallel), the system can produce internally-consistent suggestions,
which may be valuable in some tasks where there are multiple
reasonable completions for the full form.
After some experimentation, we settled on an output format
that asks the model to respond with a JSON object that includes
every key, but to include string values only for the elds that should
have their values updated from their current values. Otherwise,
the JSON value for this eld should be a
false
Boolean value.

arXiv Preprint, October 2023 Aveni et al.
Figure 7: In the information-gathering task, information
from school websites is inserted into the target form in the
information-gathering task, including elds for: school and
district name, principal name, grade levels ser ved (e.g. 9-12),
total enrollment count, address, and phone number.
By keeping each key in the JSON object (as opposed to asking
the model to return only the keys needed), we observed a lower
risk of the model prematurely closing the JSON object in tasks
where the model needed to make many suggestions; this serves as
a rudimentary “chain-of-thought” prompt [
43
], considering each
key individually before making a decision to nish the response.
By removing the requirement to transcribe many elds exactly, we
prevent a distracting, noisy set of output examples from obfuscating
the true task being demonstrated in those examples.
We have found that, given the prompt as described in this section,
OmniFill rarely suggests overeager lls for form elds that (given
the bag of context) don’t need to be updated in the tasks for which
we have tried the system. In our user study’s information-gathering
task, for example, OmniFill rarely provided a suggestion for a eld
whose value was not discernible from browsing context, and in the
data-formatting task, OmniFill typically only oered suggestions
for the elds that the task asked users to update. The extent to
which OmniFill is conservative this way is highly dependent on
the prompt; for example, altering the prompt in Figure 6 to include
the sentence, “You must provide a useful suggestion for every eld,
even if you aren’t sure.” causes the model to oer a suggestion for
every eld.
We believe that, although LLMs can be powerful engines for
solving tasks in a domain-agnostic way, tuning prompts to improve
performance on some tasks without hindering performance on
other tasks requires careful planning. To better manage the uncer-
tainty of “herding AI cats” [
45
], practitioners should regression-test
changes to systems’ prompt structures on a wide range of sam-
ple tasks that require capabilities across all task dimensions (as
described in Section 3) and context facets.
6 USER STUDY
We conducted one-hour sessions with 18 participants to judge im-
pressions of OmniFill. Participants, aged 21-30 (mean 24), spoke
English and were located in the United States. Four participants
identied as female, twelve identied as male, and two did not
disclose their gender. Participants completed a consent form and
were compensated with a $20 gift card for their time.
Phone number formats
(###) ###-####
##########
###-###-####
### #######
### ### ####
+1 (###) ###-####
+1##########
+1 ### ### ####
1-(###)###-####
+1-###-###-####
(###) ###-####
T-Shirt size formats
S
xs
3XL
med
LARGE
lrg
ex small
…
XS
S
M
L
XL
XXL
XXXL
Figure 8: The form and required transformations for the
data-formatting task.
6.1 Information-gathering task
Participants joined a Zoom call and completed two distinct tasks
with OmniFill through a remote virtual desktop, with a demon-
stration of the system incorporated into the rst task. In the rst
task, participants were instructed to “forage” information [
34
] from
websites of schools, inputting that information into a structured
form (an instance of EspoCRM [
2
]), shown in Figure 7. First, par-
ticipants were directed to the website of a public high school and
asked to spend a few minutes to ll the form manually, without
using OmniFill. For this test website, participants who took longer
than a few minutes were oered assistance locating the form data.
Then, participants were shown a demonstration on a dierent
school’s website, using OmniFill to ll the same form. In this demo,
participants were shown how to use the Alt+select interaction
to add context to their scrapbook, then shown how to generate
and accept suggestions for the form. Participants were shown that
selections can be made approximately, and that it was possible (but
not necessary) to make multiple distinct selections before returning
to the target form. Participants were shown how to add context
to the scrapbook manually, for situations where the Alt+select
interaction failed (e.g. when viewing PDFs). In the demonstration,
participants were shown and reminded that form inputs may be
typed manually and need not come from OmniFill suggestions. We
also checked OmniFill’s “Automatically save examples for this site”
checkbox so that the form’s “Save” button would trigger the current
form inputs to be saved as an example.
After the demonstration, participants were asked to practice us-
ing the system by again lling the form with data from the website
they had already manually collected information from. Then, par-
ticipants were given approximately 15 minutes to perform the task
freeform, nding websites for other schools and lling out the form,
one school at a time. To encourage participants to nd websites
with varying structures, we asked them to research schools from
dierent school districts. We also asked participants not to spend
more than a few minutes on any one website and indicated that it
was okay to leave some elds blank if they didn’t think they would
nd the information.
OmniFill: Domain-Agnostic Form Filling Suggestions Using Multi-Faceted Context arXiv Preprint, October 2023
6.2 Data formatting task
The data-formatting task required OmniFill to recognize patterns
when editing forms with prepopulated data.
Participants were shown a mock “human resources” website (an
instance of Admidio [
1
]), pre-lled with fake company membership
data. We prepopulated every user prole with a T-shirt size, most
proles (45 of 51) contained a mobile number, and some (14 of 51)
contained a home phone number. The string format of the shirt
size and phone number were randomly chosen for each member
prole, as depicted in Figure 8. Each participant received the same
mock company data, but the order of the data was randomized so
that OmniFill would behave dierently for each participant. No
participant saw more than 28 of the 51 total member proles during
the ten minutes allotted to perform the task.
Participants were shown a series of instructions for their task,
asking them to update each phone number in the member prole
(if present) to a xed format and to update each T-shirt size to
one of a few xed options (depicted in Figure 8). These instruc-
tions were shown in a screenshot so that participants could not
Alt+select them, since we wanted to investigate OmniFill’s pat-
tern recognition; although participants could have manually typed
the instructions into the scrapbook, none did. Then, we instructed
participants to visit each member prole in order, updating the
phone number and T-shirt elds following these instructions, with
OmniFill automatically saving examples each time the form was
saved. We also instructed participants to click the “Suggest with
OmniFill” button in the extension sidebar and wait for its response
on each prole before making any edits, testing the system’s ability
to recognize the task specication and oer the correct edits as
suggestions. We advised participants that they were not required
to accept OmniFill’s suggestions or use its suggestions unchanged.
6.3 Interview
After completing both tasks, participants were asked briey about
their experience in a conversational interview, including questions
about OmniFill’s perceived utility, concerns about real-world use,
condence in the system’s accuracy, and condence that they would
notice OmniFill’s mistakes.
7 STUDY RESULTS
We rst discuss high-level impressions for the two tasks, then in-
troduce four important lenses through which we consider users’
behavior; opportunistic scrapbooking, trust in OmniFill’s sugges-
tions, value in partial success, and a need for visibility into prompt
context.
7.1 Impressions
Participants readily used OmniFill in the information-gathering
task, accepting OmniFill’s suggestions for almost all form elds
in each school contact they saved; seventeen participants, when
asked, said they would likely use OmniFill if they had to perform
the information-gathering task in real life. Although suggestions
for this task largely used information from the current browsing
context portion of the prompt, even this task was able to benet from
OmniFill’s multi-faceted prompt. For example, participants who
typed schools’ country name as “United States” tended to receive
this as a suggestion, where participants who preferred “USA” often
received the suggestion in this format, indicating that OmniFill was
making use of prior examples in its prompt.
In the data-formatting task, OmniFill proved more successful
for some participants than for others, and when the system did
eventually succeed more consistently, many examples were often
required for this to settle. Figure 9 visualizes OmniFill’s success
suggesting values for the phone number elds in particular. Each
row represents a participant, and each box represents a completion
request sent through the system. Only the rst request is shown
per member prole, even if participants invoked the system more
than once, and we do not show requests for proles where no
phone number change needed to be made. In this gure, the box is
shown in green only when both phone number elds are suggested
correctly (although in many cases there was only one phone number,
so only one change needed to be made). Cases where users accepted
an incorrect suggestion or rejected a correct suggestion (choosing
instead to type the phone number manually) are also shown.
After conducting the study, we also called the GPT-4 API [
32
]
using the same prompts as those used in the study to observe system
performance with the more powerful model, shown on the right
side of Figure 9. Because GPT-4 has a smaller context window (8,192
tokens) than
gpt-3.5-turbo-16k
, some prompts could not be run
for this analysis; those are depicted with gray stripes. In addition to
the context window size, real-world trade-os of using GPT-4 for
OmniFill include cost and latency; for these reasons and to better
understand users’ behavior with a less-eective model, we used
GPT-3.5 for our studies.
7.2 Opportunistic scrapbooking
Compared to the meticulous copying-and-pasting (or memorizing-
then-typing) strategy participants employed to ll out the information-
gathering task’s contact form before being introduced to OmniFill,
participants’ information-foraging behavior during the free-form
component of this task was approximate and opportunistic. We
observed participants collecting information for OmniFill’s bag of
context quickly and even haphazardly, as one participant put it,
often with little regard for the later extraction step.
7.2.1 “Collect-then-fill” strategy. In the manual portion of the
information-gathering task, participants all alternated frequently
between the information source website and the target interface
(the contact form), copying or transcribing information in small
increments. Because the contact form’s “address” eld was split
into ve text elds (“Address”, “City”, “State”, “Postal Code”, and
“Country”), two participants constructed an ad hoc “scrapbook”
inside the “Address” eld, pasting a full line (address, city, state,
and postal code) into the interface and then manually organizing
it piece-by-piece into the appropriate elds. Still, all participants
were able to search only for small portions of the total information
demand at a time before needing to insert the collected data into
the contact form.
However, in the second phase of the information-gathering task,
during which participants were equipped with OmniFill’s scrap-
book, all but one participant eventually transitioned to a “collect-
then-ll” strategy, in which multiple information demands were
collected into the scrapbook without returning to the contact form

arXiv Preprint, October 2023 Aveni et al.
Figure 9: OmniFill’s success in suggesting phone number formats in the data-formatting task, compared to those same prompts
run against the GPT-4 API. Prompts that could not be run with GPT-4 due to context window restrictions are shown as “invalid”.
Each row represents one participant’s experience in the task, showing suggestions left-to-right as the task progressed.
Multi-value collection
Approximate targeting
Overcollection
extract
transform
School:
Midtown High School
Principal:
Jordan Green
Phone:
650-555-1130
Street:
114 Summer Street
Grade levels:
9-12
Enrollment:
1,139
Principal: Jordan Green
Phone: 650-555-1148
Address: 114 Summer Street
…a long history of welcoming a diverse body of students
grades 9-12, and this year is no exception. We are proud to
welcome 1,139 students and offer a wide range…
Midtown High School
Address: 114 Summer Street
Main Office Phone: 650-555-1130
Figure 10: Opportunistic scrapbooking involves the collection of many values at once, approximate relevance judgments, and
overcollection. OmniFill often extracts appropriate information even from opportunistically-built scrapbooks.
in between. This was true both of information that could be col-
lected in a single selection (e.g. an entire address and phone number
from one selection on a “Contact Us” page) and information from
dierent pages, which was collected in multiple text selections
often without returning to the contact form in between. In most
cases, participants did revisit the contact form before collecting all
of the demanded information, but after collecting multiple pieces of
“low-hanging fruit”. Often, the last few straggling pieces of missing
information were entered in smaller increments as the participants
hunted them down.
Participants often lost track of which information they had col-
lected already, and in some cases even expressed surprise when
they saw how much information OmniFill had extracted – “wow,
that already knocks out a lot.”
7.2.2 Overcollection. Since it is OmniFill, and not the user, who
needs to “read through” context in the scrapbook and extract rele-
vant information, the main cost of adding new information to the
bag of context occurs at the time of collection, and additional cost
is largely not incurred even if the user’s judgment of relevance
turns out to be a false positive. This distinguishes OmniFill from
simple “multiple copy-and-paste” tools, which still require precision
in foraging to prevent an overload of information to parse. Partici-
pants frequently collected context with imprecise text selections
(compared to the exact selection required for a copy-and-paste) or
occasional duplicate information from dierent sources (e.g. col-
lecting the phone number from the “Contact Us” page and from the
website’s footer). Some participants suggested obviating manual
collection entirely, but our own early prototype testing showed that
OmniFill’s success was signicantly diminished when collecting all
browsing context indiscriminately, without manual foregrounding
of information the user nds relevant.
By lowering the barriers for participants to “overcollect” infor-
mation, the system was able in some cases to correct errors, even
transparently. For example, one participant collected the wrong
phone number for the school (collecting instead the phone number
OmniFill: Domain-Agnostic Form Filling Suggestions Using Multi-Faceted Context arXiv Preprint, October 2023
of the school’s Title IX coordinator), and OmniFill generated a sug-
gestion with this phone number. Before this participant returned
back to the contact form, they found another page that contained
additional information they were looking for, alongside the correct
phone number for the school. When the participant quickly selected
the entire information block – including the correct phone number
– OmniFill corrected its phone number suggestion, now that there
were two phone numbers to choose from (and sucient natural
language information in its bag of context to determine which of
the two was more appropriate), without the participant ever even
seeing the incorrect suggestion.
Overcollection may also help when OmniFill makes an incorrect
inference based on information not in the context, e.g. when in-
correctly assuming a particular elementary school’s served grade
levels are K-5 or a high school’s are 9-12. One participant accepted
one such incorrect suggestion and, upon later nding the school’s
enrollment total on a “school prole”, collected the entire paragraph
as context; since the school prole also included the true “grade
levels served” eld value “K-6”, OmniFill updated its suggestion.
This was not a transparent correction, since the participant had
already accepted the “K-5” suggestion, but after noticing the change,
they updated the information in the contact form.
7.3 Trust in OmniFill’s suggestions
Because OmniFill assumes the role of locating relevant information
in its bag of context during the information-gathering task, users
who want to collect context opportunistically and avoid keeping
track of the bag of context must place trust in OmniFill’s inferences.
We observed that users often trusted OmniFill’s suggestions, even
when that trust may have been unfounded.
The contact form contained a “grade levels served” eld, which
should be lled with e.g. “9-12” for a typical American high school.
When websites did not explicitly include this information, some
participants were reluctant to make assumptions for the value of
this eld. Although OmniFill often withheld suggestions unless the
relevant information was explicitly present in its bag of context (for
example, we never observed the street address eld being incor-
rectly populated), the model did often return with a suggestion for
the grade level eld without the context including this information;
this happened at least once for 15 of 18 participants.
It was rare, however, for participants to question this information
when OmniFill suggested it; only one participant did explicitly
reject this overeager grade level completion, and that participant
had selected only a very small amount of text that they could
immediately observe did not contain the grade level information.
In a ipped example, one participant, who had lled out most of
the contact form, was struggling to nd the name of the school’s
principal. They chose to select the name of an assistant principal for
their scrapbook. Only after heading back to the contact form and
observing that OmniFill did not oer a suggestion for the “Principal”
eld did the participant give up on nding the information and
move onto the next school.
Although the data-formatting task contained fewer opportunities
for participants to rely on OmniFill to make “judgment calls”, we
still observed two instances of participants accepting and saving
OmniFill’s incorrect suggestion. For each of these two participants,
OmniFill made the strange suggestion in one case to duplicate a
correctly-formatted phone number into a blank phone number eld.
Although both participants had already correctly handled this case
in the past, they chose to accept this suggestion from OmniFill; one
said aloud, “Oh, yeah, sure. Why not?” as they did this, indicating
a willingness to allow OmniFill to take the reins in deciding and
carrying out the task specication.
7.4 Partial success
OmniFill was not perfect, occasionally visibly failing to extract
explicitly-foregrounded information in the information-gathering
task or oering incorrect suggestions (or no suggestions at all) for
the data-formatting task.
Still, this partial success oered a value-add in both tasks. In
the information-gathering task, participants could always fall back
to traditional information-foraging techniques to nd data that
OmniFill failed to extract. In the data-formatting task, OmniFill’s
success rate on oering correct T-Shirt sizes was high (across the 18
participants, OmniFill oered a correct suggestion in 306 of the 347
cases (= 88%) where the T-Shirt size needed to be updated), so par-
ticipants were often presented with at least one correct suggestion
even when the system couldn’t get every eld right.
Even when the phone number suggestion was incorrect, we
found that participants often accepted the incorrect suggestion and
then made changes to the eld, rather than editing the original
text eld value. Of the 16 participants who received a suggestion
to change a phone number from one incorrect format into another
incorrect format, 15 accepted one of these suggestions at least once
(and 9 did this multiple times); Figure 9 indicates incorrect sugges-
tions which were accepted by the user. For example, a common
failure mode for this task was for OmniFill to format the phone
number correctly but without removing the country code (i.e.
+1
(###) ###-####
) or to hyphenate a ten-digit number (transform-
ing
##########
to
###-###-####
). By accepting these suggestions,
participants allowed OmniFill to get them closer to their desired
result for the form eld.
Many participants noted that partial failure may not be harm-
less, however. Ten participants, when asked about concerns using
OmniFill in the real world, cited accuracy considerations. Many
noted, either during the interview or while completing the tasks,
that although they may notice “obvious” errors or those that don’t
conform to the task specication, they might not notice if Om-
niFill inserted incorrect information in the information-gathering
task or changed phone numbers in the data-formatting task. Four
participants, including some concerned about OmniFill’s accuracy,
still suggested that the potential for human error in a task like
phone number formatting was high, and that they had more trust
in OmniFill to be correct.
7.5 Context visibility
7.5.1 Verifying suggestions. LLMs, especially when asked to supply
information not in their prompt context, can “hallucinate” incorrect
information [
17
]. Although OmniFill can in some cases oer value
to users by suggesting general world or language knowledge not
present in the model’s context window (as with its school grade
level suggestions, which were largely correct), we anticipate that,
arXiv Preprint, October 2023 Aveni et al.
in many situations where OmniFill oers a value-add, the infor-
mation present in the suggestion is present in the bag of context
(either literally or in some pre-transformation state). Since sugges-
tion accuracy was often a concern for participants, oering better
visibility into where information is coming from may help.
7.5.2 Incorrect prior examples. Because OmniFill observes much
of the user’s behavior passively and has a largely immutable bag
of context, there is a risk that participants will accidentally teach
the system incorrectly, saving an example that causes problems
in the future (such as suggestions of incorrect information from
prior examples or inferences of an incorrect task specication). We
did not provide users with a mechanism for deleting incorrectly-
saved examples, and 9 of 18 participants saved at least one incorrect
example during the data-formatting task; even those who corrected
their errors were not able to delete the mistakenly-saved examples.
In two cases in the data-formatting task, we observed partic-
ipants making a mistake that was later reected in the model’s
output, both related to formatting phone numbers when two were
present in the eld. Neither mistake was caused by the participant
accepting a suggestion from OmniFill, but in both cases, when pre-
sented with a similar prole later in the task, OmniFill made the
same error.
When we later called the GPT-4 API with the prompts from the
data-formatting task, despite GPT-4’s much higher general success
rate on this task (depicted in Figure 9), both of these later errors
still manifested. Although a more powerful LLM may be able to
learn patterns and infer a task specication with few examples, this
suggests that incorrect examples of prior user behavior can still be
a critical source of ultimately incorrect predictions by the system.
8 DISCUSSION
LLM-backed systems like OmniFill can oer convenient form-lling
suggestions in a single, domain-agnostic package without requiring
signicant task-specic conguration. Because of this general ap-
plicability, we anticipate that, despite lower-precision task specica-
tions and the risk of dicult-to-notice errors, this type of predictive
system will become increasingly integrated into daily computing,
just as search result ranking and mobile predictive keyboards have.
System designers must understand both the limitations of LLM-
backed approaches and the character of users’ interactions with
such systems. In this section, we discuss implications for privacy
and accuracy, especially through the lens of potential future direc-
tions of this work.
8.1 Privacy and security
When explicitly asked about real-world concerns about using Om-
niFill, only six of 18 participants mentioned privacy or information
security as a consideration, even though the data-formatting task
involved working with simulated personal information. We did not
explain to participants upfront that OmniFill does not run entirely
on the user’s local computer, but even users who know they are
interacting with an online system may not consistently protect the
privacy of their information [
38
]. Systems that allow users to ingest
other peoples’ personal information must be considered even more
strictly. A system like OmniFill benets from passively observing
the user’s behavior or collecting implicit context (e.g. bringing in
text immediately before and after a user’s text selection in case their
mouse cursor “aim” was imperfect), but this requires trust in the
remote LLM API used by the system. Because OmniFill is designed
to interoperate between siloed ecosystems, privacy concerns persist
even outside of systems that are known to track user behavior.
Running general suggestion systems locally on the user’s com-
puter may become feasible as model architectures grow more e-
cient and computers become more powerful, keeping model queries
private. Still, future work may choose to store many prior user ex-
amples (more than what can t into a single LLM prompt) for later
retrieval during prompt construction (as in [
26
]). System designers
should be careful when collecting and opaquely storing browsing
context long-term, even locally, since this practice can increase the
consequences of a system breach.
8.2 Accuracy
Even after the system appears to have “learned” a task, the lack of
a rigorous task specication can cause occasional errors (as Fig-
ure 9 demonstrates in the GPT-4 section). OmniFill is designed to
assist users in their manual tasks, not construct reliable automa-
tions. However, “automation bias” is known to result in uncertainty
among users of automated systems [
11
], and a “good-enough” au-
tomation of menial tasks may cause the user to “check out” and
stop manually verifying the results of suggestions, as reported by
some participants after completing our data-formatting task. As
Figure 9 illustrates, success can be highly dependent on choice of
model, depending on the task at hand. This suggests challenges
for developers building systems that are not entirely under their
control.
Since users cannot inspect the LLM’s workings, it is dicult to
form a mental model of which types of errors the LLM is likely to
make, meaning even partial success of the system may have variable
utility. We observed users accepting OmniFill’s “judgment calls”
even though the system had never been told how it should make
these judgments; the “authority” of the system seemed persuasive
even in those very situations where an automated system cannot
know how to behave.
Future improvements to such systems may further reduce the
cognitive load demanded of users during certain tasks (e.g. by im-
proving implicit context collection so that less information needs
to be explicitly foregrounded), but these exact improvements may
cause users to be less likely to notice when the model makes an
error. Our results from the information-gathering task demonstrate
that the system is already powerful enough to permit users to col-
lect and use information without noticing that they had collected
it. How, then, would a user in this situation notice if the suggestion
is incorrect?
Context visibility may play a key role. Because the “collect-then-
ll” strategy recruits OmniFill’s bag of context as an auxiliary
“memory” for the user, future work in constructing interface fea-
tures could allow users to peer into the bag of context and view
context sources in situ. Since information used in suggestions is
often present in the bag of context, either in some literal or pre-
transformation form, these features could surface just the context
that matches with OmniFill’s suggestions. Although a literal search
for each suggestion in the bag of context may not yield results when
OmniFill: Domain-Agnostic Form Filling Suggestions Using Multi-Faceted Context arXiv Preprint, October 2023
the task involves transformation operations, additional prompts to
a lighter-weight LLM (or a semantic search using an embedding
model) could be used to handle many simpler cases. OmniFill’s full
LLM prompt would still be responsible for producing the actual sug-
gestions, since the full bag of context may be valuable for making
high-quality predictions (e.g. if the form structure is poorly-labeled
but can be learned through prior form-lling examples), but post
hoc “attribution” may be achieved through an auxiliary system.
Although in situ training of the system can be a low-friction
way to oer predictive suggestions, systems should provide users
with the ability to view and rene their task specications, e.g. by
curating their set of examples to maximize system accuracy. Future
work could assist users in this process by detecting and surfacing
potentially anomalous prior examples or by engaging the user in a
dialogue to dene and ne-tune task specications as the system is
used over time.
9 CONCLUSION
Not every task calls for full automation or an elaborate specica-
tion. Even when task denitions are fuzzy, partial automation of
the simpler tedious components of form lling tasks can prove
valuable, and LLM-backed systems like OmniFill can serve as a
“glue” between arbitrary context sources and target forms without
heavy conguration. We demonstrate opportunities of LLM-backed
systems to assist in a unique subspace of form lling tasks, then
describe our observations of users trying the prototype. We believe
this is a rich space for future system designers to explore, but care
must be taken to understand how people perceive and use such
systems, especially in a landscape of rapidly-expanding capabilities
and expectations for articial intelligence tools.
DISCLOSURE
The authors used GitHub Copilot v1.111.404 for code prediction in
the preparation of gure source code.
ACKNOWLEDGMENTS
We would like to thank Shm Garanganao Almeda, James Smith,
and Matthew Beaudouin-Lafon for their valuable insights that con-
tributed to the framing of this work.
REFERENCES
[1]
2023. Admidio – Free online membership management software. https://www.
admidio.org/. Accessed: 2023-09-14.
[2]
2023. EspoCRM.com: Free Self Hosted & Cloud CRM software. https://www.
espocrm.com/. Accessed: 2023-09-14.
[3]
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes,
Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Haus-
man, Alex Herzog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan,
Eric Jang, Rosario Jauregui Ruano, Kyle Jerey, Sally Jesmonth, Nikhil Joshi, Ryan
Julian, Dmitry Kalashnikov, Yuheng Kuang, Kuang-Huei Lee, Sergey Levine, Yao
Lu, Linda Luu, Carolina Parada, Peter Pastor, Jornell Quiambao, Kanishka Rao,
Jarek Rettinghouse, Diego Reyes, Pierre Sermanet, Nicolas Sievers, Clayton Tan,
Alexander Toshev, Vincent Vanhoucke, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu,
Mengyuan Yan, and Andy Zeng. 2022. Do As I Can and Not As I Say: Grounding
Language in Robotic Aordances. In arXiv preprint arXiv:2204.01691.
[4]
Kenneth C Arnold, Krysta Chauncey, and Krzysztof Z Gajos. 2020. Predictive text
encourages predictable writing. In Proceedings of the 25th International Conference
on Intelligent User Interfaces. 128–138.
[5]
Shaon Barman, Sarah Chasins, Rastislav Bodik, and Sumit Gulwani. 2016. Ringer:
Web Automation by Demonstration. In Proceedings of the 2016 ACM SIGPLAN In-
ternational Conference on Object-Oriented Programming, Systems, Languages, and
Applications (Amsterdam, Netherlands) (OOPSLA 2016). Association for Comput-
ing Machinery, New York, NY, USA, 748–764. https://doi.org/10.1145/2983990.
2984020
[6]
Holger Bast and Ingmar Weber. 2006. Type Less, Find More: Fast Autocompletion
Search with a Succinct Index. In Proceedings of the 29th Annual International ACM
SIGIR Conference on Research and Development in Information Retrieval (Seattle,
Washington, USA) (SIGIR ’06). Association for Computing Machinery, New York,
NY, USA, 364–371. https://doi.org/10.1145/1148170.1148234
[7]
Hichem Belgacem, Xiaochen Li, Domenico Bianculli, and Lionel Briand. 2023.
A Machine Learning Approach for Automated Filling of Categorical Fields in
Data Entry Forms. ACM Trans. Softw. Eng. Methodol. 32, 2, Article 47 (apr 2023),
40 pages. https://doi.org/10.1145/3533021
[8]
Eric A Bier, Edward W Ishak, and Ed Chi. 2006. Entity quick click: rapid text
copying based on automatic entity extraction. In CHI’06 Extended Abstracts on
Human Factors in Computing Systems. 562–567.
[9]
Vishwanath Bijalwan, Vinay Kumar, Pinki Kumari, and Jordan Pascual. 2014. KNN
based machine learning approach for text and document mining. International
Journal of Database Theory and Application 7, 1 (2014), 61–70.
[10]
Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora,
Sydney von Arx, Michael S. Bernstein, Jeannette Bohg, Antoine Bosselut, Emma
Brunskill, Erik Brynjolfsson, Shyamal Buch, Dallas Card, Rodrigo Castellon,
Niladri Chatterji, Annie Chen, Kathleen Creel, Jared Quincy Davis, Dora Dem-
szky, Chris Donahue, Moussa Doumbouya, Esin Durmus, Stefano Ermon, John
Etchemendy, Kawin Ethayarajh, Li Fei-Fei, Chelsea Finn, Trevor Gale, Lauren
Gillespie, Karan Goel, Noah Goodman, Shelby Grossman, Neel Guha, Tatsunori
Hashimoto, Peter Henderson, John Hewitt, Daniel E. Ho, Jenny Hong, Kyle Hsu,
Jing Huang, Thomas Icard, Saahil Jain, Dan Jurafsky, Pratyusha Kalluri, Siddharth
Karamcheti, Geo Keeling, Fereshte Khani, Omar Khattab, Pang Wei Koh, Mark
Krass, Ranjay Krishna, Rohith Kuditipudi, Ananya Kumar, Faisal Ladhak, Mina
Lee, Tony Lee, Jure Leskovec, Isabelle Levent, Xiang Lisa Li, Xuechen Li, Tengyu
Ma, Ali Malik, Christopher D. Manning, Suvir Mirchandani, Eric Mitchell, Zanele
Munyikwa, Suraj Nair, Avanika Narayan, Deepak Narayanan, Ben Newman,
Allen Nie, Juan Carlos Niebles, Hamed Nilforoshan, Julian Nyarko, Giray Ogut,
Laurel Orr, Isabel Papadimitriou, Joon Sung Park, Chris Piech, Eva Portelance,
Christopher Potts, Aditi Raghunathan, Rob Reich, Hongyu Ren, Frieda Rong,
Yusuf Roohani, Camilo Ruiz, Jack Ryan, Christopher Ré, Dorsa Sadigh, Shiori
Sagawa, Keshav Santhanam, Andy Shih, Krishnan Srinivasan, Alex Tamkin, Ro-
han Taori, Armin W. Thomas, Florian Tramèr, Rose E. Wang, William Wang,
Bohan Wu, Jiajun Wu, Yuhuai Wu, Sang Michael Xie, Michihiro Yasunaga, Ji-
axuan You, Matei Zaharia, Michael Zhang, Tianyi Zhang, Xikun Zhang, Yuhui
Zhang, Lucia Zheng, Kaitlyn Zhou, and Percy Liang. 2022. On the Opportunities
and Risks of Foundation Models. arXiv:2108.07258 [cs.LG]
[11]
Raymond R. Bond, Tomas Novotny, Irena Andrsova, Lumir Koc, Martina Sisakova,
Dewar Finlay, Daniel Guldenring, James McLaughlin, Aaron Peace, Victoria
McGilligan, Stephen J. Leslie, Hui Wang, and Marek Malik. 2018. Automation
bias in medicine: The inuence of automated diagnoses on interpreter accuracy
and uncertainty when reading electrocardiograms. Journal of Electrocardiology 51,
6, Supplement (2018), S6–S11. https://doi.org/10.1016/j.jelectrocard.2018.08.007
[12]
Vinayak R. Borkar, Kaustubh Deshmukh, and Sunita Sarawagi. 2000. Automat-
ically extracting structure from free text addresses. IEEE Data Eng. Bull. 23, 4
(2000), 27–32.
[13]
José Cambronero, Sumit Gulwani, Vu Le, Daniel Perelman, Arjun Radhakrishna,
Clint Simon, and Ashish Tiwari. 2023. FlashFill++: Scaling Programming by Ex-
ample by Cutting to the Chase. In Principles of Programming Languages. ACM SIG-
PLAN, ACM. https://www.microsoft.com/en-us/research/publication/ashll-
scaling-programming-by-example-by-cutting-to-the-chase/
[14]
Sarah E. Chasins, Maria Mueller, and Rastislav Bodik. 2018. Rousillon: Scrap-
ing Distributed Hierarchical Web Data. In Proceedings of the 31st Annual ACM
Symposium on User Interface Software and Tec hnology (Berlin, Germany) (UIST
’18). Association for Computing Machinery, New York, NY, USA, 963–975.
https://doi.org/10.1145/3242587.3242661
[15]
John Joon Young Chung, Wooseok Kim, Kang Min Yoo, Hwaran Lee, Eytan Adar,
and Minsuk Chang. 2022. TaleBrush: Visual Sketching of Story Generation with
Pretrained Language Models. In Extended Abstracts of the 2022 CHI Conference
on Human Factors in Computing Systems (New Orleans, LA, USA) (CHI EA ’22).
Association for Computing Machinery, New York, NY, USA, Article 172, 4 pages.
https://doi.org/10.1145/3491101.3519873
[16]
Morgan Dixon and James Fogarty. 2010. Prefab: implementing advanced behav-
iors using pixel-based reverse engineering of interface structure. In Proceedings
of the SIGCHI Conference on Human Factors in Computing Systems. 1525–1534.
[17]
Nouha Dziri, Sivan Milton, Mo Yu, Osmar Zaiane, and Siva Reddy. 2022. On
the Origin of Hallucinations in Conversational Models: Is it the Datasets or the
Models?. In Proceedings of the 2022 Conference of the North American Chapter
of the Association for Computational Linguistics: Human Language Technologies.
Association for Computational Linguistics, Seattle, United States, 5271–5285.
https://doi.org/10.18653/v1/2022.naacl-main.387
[18]
Steven M. Goodman, Erin Buehler, Patrick Clary, Andy Coenen, Aaron Donsbach,
Tianie N. Horne, Michal Lahav, Robert MacDonald, Rain Breaw Michaels, Ajit
arXiv Preprint, October 2023 Aveni et al.
Narayanan, Mahima Pushkarna, Joel Riley, Alex Santana, Lei Shi, Rachel Sweeney,
Phil Weaver, Ann Yuan, and Meredith Ringel Morris. 2022. LaMPost: Design and
Evaluation of an AI-Assisted Email Writing Prototype for Adults with Dyslexia.
In Proceedings of the 24th International ACM SIGACCESS Conference on Computers
and Accessibility (Athens, Greece) (ASSETS ’22). Association for Computing
Machinery, New York, NY, USA, Article 24, 18 pages. https://doi.org/10.1145/
3517428.3544819
[19]
Melanie Hartmann and Max Muhlhauser. 2009. Context-Aware Form Filling for
Web Applications. In 2009 IEEE International Conference on Semantic Computing.
221–228. https://doi.org/10.1109/ICSC.2009.83
[20]
Eric Horvitz. 1999. Principles of mixed-initiative user interfaces. In Proceedings
of the SIGCHI conference on Human Factors in Computing Systems. 159–166.
[21]
Maurice Jakesch, Advait Bhat, Daniel Buschek, Lior Zalmanson, and Mor Naaman.
2023. Co-writing with opinionated language models aects users’ views. In
Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems.
1–15.
[22]
Tae Soo Kim, DaEun Choi, Yoonseo Choi, and Juho Kim. 2022. Stylette: Styling the
Web with Natural Language. In Proceedings of the 2022 CHI Conference on Human
Factors in Computing Systems (New Orleans, LA, USA) (CHI ’22). Association
for Computing Machinery, New York, NY, USA, Article 5, 17 pages. https:
//doi.org/10.1145/3491102.3501931
[23]
Heidi Horstmann Koester and Simon P Levine. 1994. Modeling the speed of
text entry with a word prediction interface. IEEE transactions on rehabilitation
engineering 2, 3 (1994), 177–187.
[24]
Ranjitha Kumar, Arvind Satyanarayan, Cesar Torres, Maxine Lim, Salman Ahmad,
Scott R. Klemmer, and Jerry O. Talton. 2013. Webzeitgeist: Design Mining the
Web. In ACM Human Factors in Computing Systems (CHI). https://doi.org/10.
1145/2470654.2466420
[25]
Gilly Leshed, Eben M. Haber, Tara Matthews, and Tessa Lau. 2008. CoScripter:
Automating & Sharing How-to Knowledge in the Enterprise. In Proceedings of
the SIGCHI Conference on Human Factors in Computing Systems (Florence, Italy)
(CHI ’08). Association for Computing Machinery, New York, NY, USA, 1719–1728.
https://doi.org/10.1145/1357054.1357323
[26]
Itay Levy, Ben Bogin, and Jonathan Berant. 2023. Diverse Demonstrations Im-
prove In-context Compositional Generalization. arXiv:2212.06800 [cs.CL]
[27]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin,
Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel,
Sebastian Riedel, and Douwe Kiela. 2021. Retrieval-Augmented Generation for
Knowledge-Intensive NLP Tasks. arXiv:2005.11401 [cs.CL]
[28]
Greg Little, Tessa A Lau, Allen Cypher, James Lin, Eben M Haber, and Eser
Kandogan. 2007. Koala: capture, share, automate, personalize business processes
on the web. In Proceedings of the SIGCHI conference on Human factors in computing
systems. 943–946.
[29]
Mikaël Mayer, Gustavo Soares, Maxim Grechkin, Vu Le, Mark Marron, Oleksandr
Polozov, Rishabh Singh, Benjamin Zorn, and Sumit Gulwani. 2015. User Inter-
action Models for Disambiguation in Programming by Example. In Proceedings
of the 28th Annual ACM Symposium on User Interface Software & Technology
(Charlotte, NC, USA) (UIST ’15). Association for Computing Machinery, New
York, NY, USA, 291–301. https://doi.org/10.1145/2807442.2807459
[30]
Arnab Nandi and HV Jagadish. 2007. Assisted querying using instant-response
interfaces. In Proceedings of the 2007 ACM SIGMOD international conference on
Management of data. 1156–1158.
[31]
Nhan Nguyen and Sarah Nadi. 2022. An empirical evaluation of GitHub copilot’s
code suggestions. In Proceedings of the 19th International Conference on Mining
Software Repositories. 1–5.
[32] OpenAI. 2023. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL]
[33]
Kseniia Palin, Anna Maria Feit, Sunjun Kim, Per Ola Kristensson, and Antti
Oulasvirta. 2019. How do people type on mobile devices? Observations from a
study with 37,000 volunteers. In Proceedings of the 21st International Conference
on Human-Computer Interaction with Mobile Devices and Services. 1–12.
[34]
Peter Pirolli and Stuart Card. 1999. Information foraging. Psychological review
106, 4 (1999), 643.
[35]
Kevin Pu, Jim Yang, Angel Yuan, Minyi Ma, Rui Dong, Xinyu Wang, Yan Chen,
and Tovi Grossman. 2023. DiLogics: Creating Web Automation Programs With
Diverse Logics. arXiv preprint arXiv:2308.05828. To appear: UIST 2023 (2023).
[36]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli,
Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer:
Language Models Can Teach Themselves to Use Tools. arXiv:2302.04761 [cs.CL]
[37]
Jerey Stylos, Brad A. Myers, and Andrew Faulring. 2004. Citrine: Providing
Intelligent Copy-and-Paste. In Proceedings of the 17th Annual ACM Symposium on
User Interface Software and Technology (Santa Fe, NM, USA) (UIST ’04). Association
for Computing Machinery, New York, NY, USA, 185–188. https://doi.org/10.
1145/1029632.1029665
[38]
S. Shyam Sundar, Hyunjin Kang, Mu Wu, Eun Go, and Bo Zhang. 2013. Unlocking
the Privacy Paradox: Do Cognitive Heuristics Hold the Key?. In CHI ’13 Extended
Abstracts on Human Factors in Computing Systems (Paris, France) (CHI EA ’13).
Association for Computing Machinery, New York, NY, USA, 811–816. https:
//doi.org/10.1145/2468356.2468501
[39]
Tim Teitelbaum and Thomas Reps. 1981. The Cornell Program Synthesizer: A
Syntax-Directed Programming Environment. Commun. ACM 24, 9 (sep 1981),
563–573. https://doi.org/10.1145/358746.358755
[40]
Paul Viola and Mukund Narasimhan. 2005. Learning to Extract Information
from Semi-Structured Text Using a Discriminative Context Free Grammar. In
Proceedings of the 28th Annual International ACM SIGIR Conference on Research and
Development in Information Retrieval (Salvador, Brazil) (SIGIR ’05). Association
for Computing Machinery, New York, NY, USA, 330–337. https://doi.org/10.
1145/1076034.1076091
[41]
Bryan Wang, Gang Li, and Yang Li. 2023. Enabling conversational interaction with
mobile ui using large language models. In Proceedings of the 2023 CHI Conference
on Human Factors in Computing Systems. 1–17.
[42]
Shaohua Wang, Ying Zou, Bipin Upadhyaya, and Joanna Ng. 2013. An Intelligent
Framework for Auto-lling Web Forms from Dierent Web Applications. In
2013 IEEE Ninth World Congress on Ser vices. 175–179. https://doi.org/10.1109/
SERVICES.2013.19
[43]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia,
Ed Chi, Quoc Le, and Denny Zhou. 2023. Chain-of-Thought Prompting Elicits
Reasoning in Large Language Models. arXiv:2201.11903 [cs.CL]
[44]
Tom Yeh, Tsung-Hsiang Chang, and Robert C. Miller. 2009. Sikuli: Using GUI
Screenshots for Search and Automation. In Proceedings of the 22nd Annual ACM
Symposium on User Interface Software and Technology (Victoria, BC, Canada)
(UIST ’09). Association for Computing Machinery, New York, NY, USA, 183–192.
https://doi.org/10.1145/1622176.1622213
[45]
J.D. Zamrescu-Pereira, Heather Wei, Amy Xiao, Kitty Gu, Grace Jung, Matthew G
Lee, Bjoern Hartmann, and Qian Yang. 2023. Herding AI Cats: Lessons from
Designing a Chatbot by Prompting GPT-3. In Proceedings of the 2023 ACM
Designing Interactive Systems Conference (Pittsburgh, PA, USA) (DIS ’23). As-
sociation for Computing Machinery, New York, NY, USA, 2206–2220. https:
//doi.org/10.1145/3563657.3596138
[46]
Albert Ziegler, Eirini Kalliamvakou, X. Alice Li, Andrew Rice, Devon Rifkin,
Shawn Simister, Ganesh Sittampalam, and Edward Aftandilian. 2022. Productivity
Assessment of Neural Code Completion. In Proceedings of the 6th ACM SIGPLAN
International Symposium on Machine Programming (San Diego, CA, USA) (MAPS
2022). Association for Computing Machinery, New York, NY, USA, 21–29. https:
//doi.org/10.1145/3520312.3534864
