
Developer’s Guide
Version 4.8

Version 4.8 PointBase Developer 2
Copyright © 1999-2004, DataMirror Mobile Solutions Inc.
All Rights Reserved
Version 4.8
This product and related documentation are protected by copyright and distributed under
license agreement restricting its use, copying, reproduction, distribution, performance, and
decompilation. No part of this product, or any other product of DataMirror Mobile Solutions,
Inc. or related documentation may be stored, transmitted, reproduced or used in any other
manner in any form by any means without prior written authorization from DataMirror Mobile
Solutions, Inc.
PointBase™ and UniSync™ are trademarks of DataMirror Mobile Solutions, Inc.
Microsoft, Windows, Windows 95, Windows 98, Windows 2000, and Windows NT are
registered trademarks of Microsoft Corporation. Adobe and Acrobat are registered trademarks
of Adobe Systems, Inc. Java™ is a registered trademark of Sun Microsystems, Inc. Other
brands and products are trademarks of their respective holders.
Proprietary and Trademark
Information

Version 4.8 PointBase Developer 3
Table of Contents
Preface 7
Purpose 7
Audience 7
Release Notes 7
Document Feedback 8
Document Conventions Used in This Guide 8
Developer’s Overview 9
JDBC and PointBase 9
SQL and PointBase 10
Your Application and PointBase 11
What’s New With PointBase Embedded 12
PointBase JDBC Basic Tutorial 14
Refreshing the Sample Database 14
Making a Connection to PointBase 15
Creating and Executing Static JDBC Statement 16
Retrieving Row Values From Non-Scrollable Result Sets 18
Closing and Committing Objects 19
PointBase JDBC Advanced Tutorial 20
Creating and Executing a Dynamic JDBC Statement 20
Using Result Sets 22
Flushing the Database Log 30
Performing Batch Operations 30
Retrieving Data From BLOB Columns 31
Retrieving Data From CLOB Columns 31
Creating Functions 32
Creating Stored Procedures 33
Connecting to Multiple Databases 37
Basic SQL Data Objects 38
Data Objects Within PointBase Embedded 38
Database 39
User 40
Schema 41
Table 42

PointBase
Version 4.8 PointBase Developer 4
Derived Table 42
View 43
Temporary Table 43
Column 44
Connection Pools 46
com.pointbase.jdbc.jdbcPooledDatasource 46
JNDI 49
SQL Data Types 52
CHARACTER [(length)] or CHAR [(length)] 53
VARCHAR (length) 53
BOOLEAN 54
SMALLINT 55
INTEGER or INT 55
BIGINT 56
DECIMAL [(p[,s])] or DEC [(p[,s])] 57
NUMERIC [(p[,s])] 57
REAL 58
FLOAT(p) 58
DOUBLE PRECISION 58
DATE 59
TIME 60
TIMESTAMP 60
CLOB [(length)] or CHARACTER LARGE OBJECT [(length)] or CHAR LARGE OB-
JECT [(length)] LONGVARCHAR[(length)] 61
BLOB [(length)] or BINARY LARGE OBJECT [(length)] LONGVARBIN-
NARY[(length)] BINARY[(length)] VARBINARY[(length)] 62
Data Conversions and Assignments 62
SQL Scalar and Aggregate Functions 66
SQL Scalar Numeric Functions 66
SQL Scalar Character String Functions 67
SQL Scalar Date/Time Functions 70
SQL Scalar CAST Function 72
SQL Scalar Routine Invocation 73
SQL Aggregate Functions 73
SQL Special Registers 75
Indexes and Constraints 76
Indexes 76
Keys 77
Constraints 77
Index Organized Tables 79
Search Conditions and Predicates 80
Search Conditions 80
Predicates 82
Transactions and Locks 88

PointBase
Version 4.8 PointBase Developer 5
Transactions 88
Row Level Locking 89
Transaction Isolation Levels 89
Distributed Transactions 91
PointBase’s Role in a DTP Environment 91
Java Transaction API (JTA) 93
JDBC 2.0 Optional Package API 93
Implementing javax.sql.XADataSource 94
Using PointBase in a DTP Environment 96
Mixing Global and Local Transactions 100
Unsupported in PointBase 101
SQL Security and Privileges 102
Predefined Users 103
Granting and Revoking Privileges to Users 104
Predefined Roles 107
Granting and Revoking Privileges to Roles 107
Application Programming
Interface Tools 112
Load and Unload API’s 112
116
Database Compress Tool 116
Appendix A: SQL Reference 117
Conventions 117
Page Format Conventions 117
Syntax Conventions 118
Data Definition Language 118
CREATE SCHEMA 119
CREATE TABLE 120
CREATE VIEW 132
CREATE USER 134
CREATE ROLE 135
CREATE INDEX 136
CREATE FUNCTION 137
CREATE PROCEDURE 141
CREATE TRIGGER 144
ALTER TABLE 151
ALTER USER 153
Dropping SQL Objects 155
DROP INDEX 155
DROP FUNCTION or DROP PROCEDURE 156
DROP SCHEMA 157
DROP TABLE 157
DROP VIEW 158
DROP TRIGGER 159
DROP USER 160
DROP ROLE 160
Data Query Language and
Data Manipulation Language 161

PointBase
Version 4.8 PointBase Developer 6
SELECT 162
INSERT 176
UPDATE 179
DELETE 181
Data Control Language 182
CALL 182
RETURN 183
SET assignment 184
SET PATH 185
SIGNAL 186
VALUES 187
SET CONSTRAINTS 187
Transaction Control 189
SAVEPOINT 189
COMMIT 190
RELEASE SAVEPOINT 191
ROLLBACK 192
SET DATALOG 193
START TRANSACTION ISOLATION LEVEL 194
PointBase-Specific SQL 196
SHUTDOWN 196
BACKUP 196
200
BACKUP TABLE 200
RESTORE TABLE 201
BACKUP/RESTORE TABLE API 202
BACKUP LOG 204
SET ROLLFORWARD 204
205
ROLLFORWARD RESTORE UTILITY 205
Appendix B: Unsupported JDBC Methods in PointBase 207
Appendix C: Reserved Words 209
Appendix D: SQL Data Type Code 216

Version 4.8 PointBase Developer 7
Preface
Thank you for your interest in Version 4.8 of the PointBase product line.
Purpose
This guide describes how to develop applications using PointBase Embedded and Embedded -
Server Option. The following is a list of some things you can expect from this guide.
• PointBase JDBC Tutorials
• Supported SQL Standards and Syntax
• PointBase Database Concepts and Techniques
Audience
This guide is geared towards the Java development community. Because PointBase is the
100% Pure Java Application Database, this guide assumes that you know the following
concepts:
• Have basic knowledge of the Standard Query Language (SQL).
• Have basic knowledge of the Java programming language.
• Have basic knowledge of Java Database Connectivity (JDBC).
• Understand basic database concepts.
• Have knowledge of your operating system and server and client concepts.
Release Notes
The following link displays the most up-to-date information on PointBase products.
www.pointbase.com/support/releasenotes.html

PointBase
Version 4.8 PointBase Developer 8
Document Feedback
Please send comments or suggestions for all PointBase documentation to the following email
address.
pbdocfeedb[email protected]
Document Conventions Used in This Guide
Convention Identifies Examples
ALL
UPPERCASE
LETTERS
• Environment variables
• Database table names
• SQL Keywords
•PATH
• S_LST_OF_VAL
• CREATE TABLE
Courier
New font
• Directory, file, folder, and path
names
•Code
• Data you need to type
• c:\pointbase\img.bmp
• Set PointBase =
• Type Your Company
Name Here
Initial
Uppercase
Letters
PointBase names, objects, properties,
windows, screens, dialog boxes,
menus, buttons, tabs, applets, fields,
and icons
PointBase Embedded,
Business Component object,
List Editor window, Main
menu, and Cancel button
Italics • Book titles
• Cross references in an index or
glossary
• Variables
• Arguments to statements of
functions
• First appearance of a new word or
phrase
•Emphasis
• User’s Guide
• see also or see
• APPSRVR_4X_ROOT
• variable, rate, prompt$
• new word or phrase
• Do not do this before you
do that.
[ ] Optional italicized arguments or
characters inside angle brackets
[caption$]
{ | } Choice from listed arguments; use OR
operator (|) to separate
{Goto label | Resume Next |
Goto 0}

Version 4.8 PointBase Developer 9
Developer’s Overview
This chapter outlines the PointBase Relational Database Management System (RDBMS),
referring to PointBase Embedded and Server Option. It describes the JDBC driver, the JDBC
API, and the SQL standards supported by PointBase. This chapter also describes new features
and changes with PointBase Embedded Version 4.8.
JDBC and PointBase
The core JDBC Application Program Interface (API) consists of a set of call level interfaces
found in the java.sql package. The JDBC API is used by Java applications to access and
manipulate the data stored in a database by invoking SQL commands. For more details on the
JDBC API refer to the Sun Microsystems Inc.’s website: http://java.sun.com/ or the Sun
Microsystems JDBC manual.
PointBase fully supports JDBC 1.x, a subset of JDBC 2.0 API, a subset of JDBC 2.0 Extension
Interfaces, and a subset JDBC 3.0 which Table 1 describes. PointBase also supports additional
JDBC 2.0 Extension Interfaces for “distributed transactions.” (See "JDBC 2.0 Optional
Package API" on page 93.) You can also view any unsupported methods at, "Appendix B:
Unsupported JDBC Methods in PointBase" on page 207.

PointBase
Version 4.8 PointBase Developer 10
The PointBase JDBC Driver
The PointBase JDBC driver provides access to PointBase Embedded and Server Option. The
driver interprets the database Universal Resource Locator (URL) to connect to the appropriate
database. PointBase implements a “Type 4” JDBC driver, directly accessing PointBase
Embedded using JDBC calls.
To use the PointBase JDBC driver in your application, you must first load and register the
driver with the JDBC DriverManager, and then provide the URL of the database to which you
want to connect. The database URL specifies the connection protocol, database location,
“listener” port, and the database name. Please refer to the basic tutorial chapter in this guide for
a more detailed explanation.
SQL and PointBase
PointBase Embedded adheres to SQL-92 Entry and Transition levels, as defined by ANSI and
ISO standards. PointBase also implements some features defined in the SQL-99 (SQL3)
standard.
For more specific information about using SQL with PointBase, please refer to “Appendix A:
SQL Reference,” of this guide and the “SQL Data Types” Chapter, which defines the data type
mappings from SQL to JDBC and Java.
Table 1: JDBC 3.0 API Supported by PointBase
API Description
java.sql.BatchUpdateException Provides information about errors that occurred during batch operations
java.sql.Blob Provides access to and manipulation of Binary Large Object data
java.sql.CallableStatement Provides access to and manipulation of Stored Procedures
java.sql.Clob Provides access to and manipulation of Character Large Object data
java.sql.Connection Constructs and manages the connection to the database
java.sql.DatabaseMetaData Provides metadata information about the database
java.sql.Driver Provides information about and manages the JDBC driver
java.sql.PreparedStatement Manages dynamic SQL statements
java.sql.ResultSet Provides metadata information about the result set
java.sql.ResultSetMetaData Manages result set metadata information
java.sql.Statement Manages static SQL statements
javax.sql.DataSource Provides access to JDBC drivers and manages data sources. [See "Additional
PointBase Methods" on page 96.]

PointBase
Version 4.8 PointBase Developer 11
Your Application and PointBase
This section shows how PointBase Embedded interacts with Java applications to provide
database functionality.
Figure 1.2 shows PointBase Embedded, which is designed to be deployed as an integral part of
your application. Both the Java Application and PointBase Embedded run within the same
JVM. Applications can make multiple database connections to the PointBase database.
Figure 1.2 Using PointBase Embedded
Figure 1.3 shows PointBase Server Option, which is deployed using the traditional client-
server model. A thin client is deployed as an integral part of the client application that both
reside in a single JVM. This connects over the network to PointBase Server Option that runs in
a second JVM.
Figure 1.3 Using PointBase Server Option
A diagram displaying a layered view of
a Java application lying on top of a
JDBC driver, which lies on top of
PointBase Embedded, which lies on top
of a Java virtual machine.
Java Application
Java Application
JDBC Driver
JDBC Driver
PointBase Embedded
PointBase Embedded
Java Virtual Machine
Java Virtual Machine
Database
Database
I/O
A layered diagram view of a Java application lying on top of a
JDBC driver, which is on top of a PointBase Client, which is on
top of a Java virtual machine. The PointBase Client
communicates with PointBase Server via TCP/IP.
Java Application
JDBC Driver
PointBase Client
Java Virtual Machine
PointBase Server
Java Virtual Machine
TCP/IP
Database

PointBase
Version 4.8 PointBase Developer 12
What’s New With PointBase Embedded
This section describes all of the new features and changes to PointBase Embedded.
PointBase Embedded (and Server Option) Enhancements
Roll Forward Recovery
Previously, PointBase could only recover using last full backup. Since backups can take a long
time for a large database, the inconvenience of performing a backup meant that it was not
always done as often as was necessary, sometimes creating a significant window of exposure.
In 4.8, changes can be applied using log files that were backed up since the last full backup
(known as "roll forward recovery") Backing up just the log files provides much shorter backup
times and less exposure to data loss.
Count(*) Optimization
Count(*) returns the number of rows (typically in a whole table). In the past, PointBase read
each row in order to determine the value to be returned. Counting this way is slow, but gives
the correct answer. In 4.8, we have added an optimization that will return the number of rows
from an internal structure when possible. Count(*) will always return the correct answer, but in
some cases must resort to the slower method. However in many cases, it will return the correct
value much faster.
Nested Query Optimization
Prior to 4.8, temp tables in nested queries were not indexed, so a query could be slow if it
required a large temp table. In 4.8, we have added indexing to temp tables that results in faster
performance for queries of this type.
Security for Stored Procedures
Previous to 4.8, stored procedures had no security model and could be used maliciously to
crash the JVM that the PointBase Server Option was running in. In 4.8, a new, optional
permission has been added using the Java Security Manager to limit what files can be used for
stored procedures.
Space Release Optimization
Previously, PointBase used a conservative algorithm for space reuse, but in a busy system free
space could be held for a long time causing the database to grow unnecessarily. In 4.8 the
algorithm has been refined so that space can be safely reused more quickly. In an environment
where many concurrent updates are taking place, the database will not grow unnecessarily.
getParameterMetaData()
This JDBC 3.0 feature has been fully implemented in release 4.8.

PointBase
Version 4.8 PointBase Developer 13
PointBase Commander Output to File
The ability to capture screen output to a file has been added for the PointBase Commander and
Console tools.

Version 4.8 PointBase Developer 14
PointBase JDBC Basic Tutorial
This tutorial is intended as a quick reference to the JDBC API. PointBase recommends that
you consult a JDBC reference manual or http://java.sun.com for more comprehensive and the
most up to date information.
The basic tutorial describes fundamental JDBC operations to access and manipulate data using
the JDBC API with PointBase Embedded. The code snippets in this tutorial are taken from the
sample application included in the “<install_folder>\samples\server_embedded\” directory of
your PointBase installation. The examples in this tutorial include: connecting to the database,
creating executable statements and closing the connection to the PointBase database.
Each example provides: a brief description of the code snippet illustrated, a code snippet from
the sample application code, and any additional information to explain the code snippet in
more detail.
Refreshing the Sample Database
If you have deleted or overwritten the sample database provided with your PointBase
installation, you must refresh the sample database by using the following steps:
Step 1. Launch the “embedded_commander.exe” file in the “<install
directory>\tools\embedded” directory.
Step 2. Follow the prompts to create a new database called “sample.”
Step 3. Type
run sample.sql. You must type the complete path to the
“sample.sql” file, for example,
run c:/pointbase/samples/server_embedded/sample.sql;

PointBase
Version 4.8 PointBase Developer 15
Making a Connection to PointBase
The following section describes the process of connecting to a PointBase database, using the
JDBC API.
Loading the PointBase JDBC Driver
This code snippet instantiates the PointBase JDBC driver:
// The PointBase Universal JDBC Driver
String l_driver = "com.pointbase.jdbc.jdbcUniversalDriver";
// Load the PointBase JDBC Driver
Class.forName(l_driver).newInstance();
Connecting to the PointBase database
This code snippet establishes a connection with the PointBase database by passing the database
URL, a username and password. By connecting with the database you create a connection
object (m_conn in the sample application). The User name and Password both default to
PBPUBLIC if they are not specified explicitly.
// The URL for the sample PointBase database
String l_URL = "jdbc:pointbase://" + p_product + "/sample";
// Database UserID
String l_UID = "pbpublic";
// Database Password
String l_PWD = "pbpublic";
// Establish connection with the database and return a Connection object
m_conn = DriverManager.getConnection(l_URL, l_UID, l_PWD);
The form of the PointBase URL, depends on which PointBase database you are using. The
following gives examples for the PointBase Embedded and Server Option databases:
• PointBase Embedded
"jdbc:pointbase:embedded:sample"
• PointBase Embedded – Server Option
"jdbc:pointbase:server://<server ip address>/sample"
or
"jdbc:pointbase:server://<server name>/sample"
To create a new database, you must use one of the specified PointBase flags. The following
example uses the new flag.
"jdbc:pointbase:server://<server name>/sample,new"
Make sure you refer to the PointBase System Guide before using any flag in the URL. Each
flag adheres to different rules when applied. (See the chapter, “Advanced Tips for Starting
PointBase,” of the PointBase System Guide, and then browse the section, “Variable
Descriptions.”)

PointBase
Version 4.8 PointBase Developer 16
Using DataSource
Instead of using the DriverManager facility to connect to the PointBase database, you may use
a JDBC DataSource by initializing a DataSource object. The following example describes how
to connect to a PointBase database using a DataSource object.
// The URL for the sample PointBase database
String l_URL = "jdbc:pointbase://" + p_product + "/sample";
// Database UserID
String l_UID = "pbpublic";
// Database Password
String l_PWD = "pbpublic";
// Create DataSource object
jdbcDataSource ds = new jdbcDataSource();
ds.setDatabaseName(l_URL);
ds.setUser(l_UID);
ds.setPassword(l_PWD);
ds.setCreateDatabase(true);
// Establish connection with the database and return a Connection object
m_conn = ds.getConnection();
Using Connection Pool with DataSource
To use the connection pool implemented by PointBase, you need to use
com.pointbase.jdbc.jdbcPooledDatasource class to create DataSource object.
Connection obtained from this DataSource uses the Connection Pool. The following example
shows how to connect to a PointBase database using the DataSource that supports the
Connection Pool.
Example
// create pooled DataSource Object
jdbcPooledDataSource pds = new jdbcPooledDatasource();
pds.setDatabaseName("sample");
pds.setUser("PBPULIC");
pds.setPassword("PBPUBLIC");
pds.setDescription("Sample database");
pds.dbIni("create=true");// option to create database, if it doesn’t exist
//get a connection object
Connection con = pds.getConnection();
// perform operations using the connection object
// finally close the connection and return the connection to the pool
con.close()
Creating and Executing Static JDBC Statement
The following code snippet gives an example of how to create and execute static JDBC
statements. First, it defines the SQL statement that the statement will execute, a statement is
then created and executed to return a read-only, non-scrollable Result Set object. Updateable
and scrollable result sets are discussed further in the advanced JDBC tutorial.
// Create the SQL Query
String SQL_SELECT = "SELECT customer_tbl.name, customer_tbl.city,"
+ " manufacture_tbl.name, manufacture_tbl.city"

PointBase
Version 4.8 PointBase Developer 17
+ " FROM customer_tbl, manufacture_tbl WHERE"
+ " UPPER(customer_tbl.city) = UPPER(manufacture_tbl.city)";
// Create a static JDBC statement
m_stmt = m_conn.createStatement();
// Execute the SQL statement and return a Non-Scrollable Result Set
m_rs = m_stmt.executeQuery(SQL_SELECT);

PointBase
Version 4.8 PointBase Developer 18
Retrieving Row Values From Non-Scrollable Result Sets
A non-scrollable result set only allows you to retrieve the values stored in the result set in
sequential order. The following example describes how to retrieve values from a non-
scrollable result set.
When a result set is returned, the cursor is positioned before the first row of the result set. To
access the first value of the result set you must advance the cursor to the first row using the
resultSet.next() method. This method is used to move the cursor from row to row in
the result set, and returns a Boolean TRUE value if there is data in the row to which the cursor
is pointing.
// Scroll through the result set (top to bottom)
while(p_rs.next())
{
// Loop through the columns
for(inti=1;i<=rsColumns;i++)
{
// Get the data from the result set
// Place methods to retrieve data here
}
The following code snippets illustrate how to retrieve specific data types from the result set.
These methods would be placed inside the “for” loop of the snippet above.
// Retrieve JDBC Char and Varchar data types
String rsString = p_rs.getString(i);
// Retrieve JDBC Integer data types
Integer rsInt = new Integer(p_rs.getInt(i));
// Retrieve JDBC Smallint data types
Short rsShort = new Short(p_rs.getShort(i));
// Retrieve JDBC Boolean data types
Boolean rsBool = new Boolean(p_rs.getBoolean(i));
// Retrieve Float, Double, Numeric and Decimal JDBC data types
Double rsDouble = new Double(p_rs.getDouble(i));
NOTE: PointBase recommends that you use the ResultSet.getBigDecimal() method
to retrieve Numeric and Decimal JDBC data types. This method is omitted in this
example for JDK 1.1.8 and JView compatibility.
// Retrieve JDBC Real data types
Float rsFloat = new Float(p_rs.getFloat(i));
// Retrieve JDBC Date data types
java.sql.Date rsDate = p_rs.getDate(i);
// Retrieve JDBC Time data types
java.sql.Time rsTime = p_rs.getTime(i);
// Retrieve JDBC Time Stamp data types
java.sql.Timestamp rsTimestamp = p_rs.getTimestamp(i);

PointBase
Version 4.8 PointBase Developer 19
Closing and Committing Objects
The following examples describe how to close result sets, static JDBC statements and finally
database connections. However, before closing a connection to the database or when you have
completed a transaction, you must either commit or rollback any changes made.
Rolling Back or Committing the Transaction
The following code snippet describes how the sample application rolls back all changes made
to the database up to this point. It uses the rollback() method.
// Rollback any changes made to the database
// Use m_conn.commit() if you don’t wish to rollback the transaction
m_conn.rollback();
NOTE: If you fail to commit a transaction prior to disconnecting from the database, and you
do not have “auto commit” switched on, the transaction will be rolled back by default
and any changes made will be lost.
Closing the Result Set
When you close a result set, you invalidate the result set. That is, it cannot be used for any
subsequent operations. The following code snippet describes how the sample application
closes the result set object.
// Close the Result Set
m_rs.close();
Closing the JDBC Statement
The following code snippet describes how the sample application closes the JDBC statement
object.
// Close the JDBC statement
m_stmt.close();
Closing the Connection to the Database
The following code snippet describes how the sample application closes the connection object.
This closes the connection to the database.
// Close the connection
m_conn.close();

Version 4.8 PointBase Developer 20
PointBase JDBC Advanced Tutorial
This tutorial is intended as a quick reference to the JDBC API. PointBase recommends that
you consult a JDBC reference manual or http://java.sun.com for more comprehensive and the
most up to date information.
The advanced tutorial describes how to perform more complex operations using the JDBC API
with PointBase Embedded. The code snippets in this tutorial are taken from the sample
application included in the “<install_folder>\samples\server_embedded\src” directory of your
PointBase installation. The examples in this tutorial include returning scrollable result sets and
performing batch updates.
Each example provides: a brief description of the code snippet illustrated, a code snippet from
the sample application code, any additional information to explain the code snippet in more
detail. The examples assume you have already connected to the PointBase sample database.
(Refer to the Basic Tutorial for information about connecting to a PointBase database.)
Creating and Executing a Dynamic JDBC Statement
The following example describes how to create and execute a dynamic JDBC statement. A
dynamic JDBC statement can improve performance of applications relative to static JDBC
statements. Unlike a static JDBC statement, dynamic or prepared statements are only compiled
once, regardless of the number of times that they are used. For example, use a dynamic JDBC
statement is when you need multiple executions of a particular SQL statement that has
changing values associated with it.

PointBase
Version 4.8 PointBase Developer 21
Creating a Prepared Statement
The following code snippet shows an example of an SQL string for use within a prepared
statement. The preparedStatement() method uses this string as its argument. The
prepared statement executes the INSERT statement as many times as required. The question
marks indicate dynamic parameters that will be bound to the prepared statement. The prepared
statement object is created using the Connection.prepareStatement() method.
// Initialize SQL for the prepared statement
String SQL_PREP_INSERT = "INSERT INTO order_tbl (order_num, customer_num,"
+ " rep_num, product_num, sales_tax_st_cd, quantity,"
+ " shipping_cost, sales_date, shipping_date,"
+ " delivery_datetime, freight_company) VALUES"
+ " (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)";
// Create a prepared statement
m_prepStmt = m_conn.prepareStatement(SQL_PREP_INSERT);
Binding the Dynamic Variables to the Prepared Statement
The following code snippet provides an example of binding dynamic variables to the prepared
statement and executing the prepared statement. Bind the variables by using the
preparedStatement.set<DataType> method, for example
preparedStatement.setInt(). The first input argument for this method is the bind parameter
index (i.e. which question mark it represents), the second input argument is the desired value to
be bound. The prepared statement is executed using the
preparedStatement.execute() method.
// Bind the parameters to the prepared statement
m_prepStmt.setInt(1, var1[i]);
m_prepStmt.setInt(2, var2[i]);
m_prepStmt.setInt(3, var3[i]);
m_prepStmt.setInt(4, var4[i]);
m_prepStmt.setString(5, var5[i]);
m_prepStmt.setInt(6, var6[i]);
m_prepStmt.setDouble(7, var7[i]);
m_prepStmt.setDate(8, var8[i]);
m_prepStmt.setDate(9, var9[i]);
m_prepStmt.setTimestamp(10, var10[i]);
m_prepStmt.setString(11, var11[i]);
// Execute the SQL prepared statement and return a result set
m_prepStmt.execute();

PointBase
Version 4.8 PointBase Developer 22
Using Result Sets
This section explains how to create a statement object for returning and manipulating different
types of result sets. By returning a scrollable type of result set, you have the capability to
retrieve result set row values in any order. Conversely, using a non-scrollable result set, you
can only retrieve result set row values as you scroll forward. With scrollable result sets,
however, you can scroll either forward or backward. Additionally, you can also scroll by
specifying a position in the result set.
To begin returning any type of result set, you have the option to specify the result set type,
concurrency, and the holdability type, when you create the SQL statement. Refer to the
ResultSet interface section of Sun Microsystems’ JDBC 2.0 and 3.0 Javadocs for more
information about the following types, concurrencies, and holdability types.
Result Set Types, Concurrency, and Holdability
To create a scrollable result set you must specify its result set type. The following table
describes the different result set types:
In addition to the result set type, you must also specify the result set concurrency. It defines
whether or not the result set is read-only or updateable. In PointBase, you can specify
CONCUR_READ_ONLY or CONCUR_UPDATEABLE. Using CONCUR_UPDATEABLE,
you have the ability to update rows in a result set using methods in the Java programming
language rather than having to update them with an SQL statement.
For example, you can INSERT, UPDATE, or DELETE a result set row, and make your changes
permanent to the database. Using CONCUR_READ_ONLY, you may read the rows in the
result set only; you cannot change them in any way.
Result Set Type Description
TYPE_FORWARD_ONLY Specifies a result set that you can move the cursor
forward only. The default result set type is
TYPE_FORWARD_ONLY.
TYPE_SCROLL_INSENSITIVE Specifies a result set that you can scroll forward,
backward, and to a specified position. You may not see
changes made by other users in the current result set.
TYPE_SCROLL_SENSITIVE Specifies a result set that you can scroll forward,
backward, and to a specified position. It allows you to
see changes made by other users in the current result set.
Result Set Concurrency Description
CONCUR_READ_ONLY Specifies a result set to be read-only. It is the default
concurrency.

PointBase
Version 4.8 PointBase Developer 23
Finally, you may specify the holdability of your result set. The holdability of a result set
defines whether or not the current result set will close after an implicit or explicit transaction
commit. Regardless of holdability, PointBase releases locks once the transaction is committed.
If cursor holdability is specified, locks will be lost for this statement and result set. Since this
result set is still open, locks need to be re-acquired prior to the next operation on this result set.
PointBase automatically re-acquires table locks required for this Statement, but row locks will
not be re-acquired. Row locks on the newly fetched rows will be determined and acquired in
the next operation depending on the transaction-isolation level.
Transaction isolation cannot be preserved for result sets that specify
HOLD_CURSORS_OVER_COMMIT. Non-repeatable_read and phantom phenomenon may
happen even for isolation levels, REPEATABLE_READ and SERIALIZABLE after a
transaction commit.
So, the recommended isolation level for results sets specifying
HOLD_CURSORS_OVER_COMMIT is READ_COMMITED, which gives the most
consistent results when compared to result sets with the holdability type,
CLOSE_CURSORS_AT_COMMIT.
Additionally, result sets with the holdability type, HOLD_CURSORS_OVER_COMMIT, will
be closed after a ROLLBACK.
Note that methods for holdability are only supported in JDBC3.0. You must use JVM 1.4
or above to specify holdability. The following table explains the different holdability types
that PointBase supports:
CONCUR_UPDATEABLE Specifies a result set to be updateable.
Result Set Concurrency Description
Holdability Type Description
HOLD_CURSORS_OVER_COMMIT ResultSet objects are not closed; they are held open
when a commit operation is implicitly or explicitly
performed.
CLOSE_CURSORS_AT_COMMIT ResultSet objects are closed when a commit operation
is implicitly or explicitly performed. The default
holdability of ResultSet objects is implementation
defined. For backward compatibility,
CLOSE_CURSORS_AT_COMMIT is the default for
PointBase.
To change the holdability default, locate the
“pointbase.ini,” and specify the parameter
“cursor.holdAcrossCommit=true” to change the
default to HOLD_CURSORS_OVER_COMMIT.

PointBase
Version 4.8 PointBase Developer 24
Creating Scrollable Result Sets
The following code snippet illustrates how to create a statement object that can return a read-
only scrollable result set that closes after a transaction commit. You may substitute any of the
supported result set types, concurrencies, or holdability types. You may use either the
“createStatement(),” “prepareStatement(),” or “prepareCall()” method from the Connection
interface. The following uses the “createStatement()” method.
// Create a statement and set the Result Set parameters to make it scrollable
m_stmt = m_conn.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE,
ResultSet.CONCUR_READ_ONLY, ResultSet.CLOSE_CURSORS_AT_COMMIT);
Notes on Scrollable Result Sets
While updating, inserting, or deleting a row in an updateable scrollable result set, PointBase
will change the lock on the row to an exclusive lock. If PointBase cannot acquire the lock, it
will throw an exception.
While using updateable scrollable result sets, you must set autocommit to false. If you set it
to true, PointBase commits the result sets, which invalidates them.
Verification
Before inserting any new rows or updating any row values, PointBase will perform any
necessary checking, including constraints and reference integrities. If a new row or row value
fails to satisfy any of them, PointBase will throw an exception. Also, while inserting a new
row, make sure to define all column values, because PointBase automatically sets undefined
column values to the database default.
Restrictions
PointBase enforces the following restrictions for scrollable result sets specified with the
CONCUR_UPDATEABLE and TYPE SENSITIVE properties:
• A query that returns a result set can select from only a single table, and cannot contain
any join operation.
• A query that returns a result set must select table columns only. It cannot select derived
columns or aggregates.
• A query that returns a result set cannot have ORDER BY, GROUP BY, or HAVING
clause.
Behavior
The PointBase JDBC driver will automatically specify the scrollable result set concurrency or
type, if it observes the following behavior:
• If you specify a result set to be CONCUR_UPDATEABLE and attempt any of the
previously mentioned restrictions, the PointBase JDBC Driver will return a result set of
CONCUR_READ_ONLY.
• If you specify a result set to be TYPE_SENSITIVE and attempt any of the previously
mentioned restrictions, the PointBase JDBC Driver will return a result set of
TYPE_INSENSITIVE.

PointBase
Version 4.8 PointBase Developer 25
Moving the Cursor
After returning a scrollable result set using a statement object, you can move the result set
cursor. The following examples describe how the sample application moves the cursor in a
scrollable result set. Similar to non-scrollable result sets, you access sequential rows of the
result set by using the ResultSet.next() method. You can also move the cursor
anywhere in a scrollable result set using the following methods.
First()
The following code snippet describes the first() method. It moves the cursor to the first
row in the result set.
// Move the cursor to the first entry in the result set - this is the data we just
// inserted
m_rs.first();
Last()
The following code snippet demonstrates the last() method. It moves the cursor to the last
value in the result set m_rs
// Move the cursor to the last entry in the result set
m_rs.last();
Previous()
The following code snippet demonstrates the previous() method. It moves the cursor to
the previous position in the result set m_rs.
// Moving back to the previous entry in the result set
m_rs.previous();
Absolute()
The following code snippet demonstrates the absolute() method. It moves the cursor to a
specific position in the result set. For example, this code snippet describes how to move the
cursor to the first row in the result set.
// Moving to the first entry in the result set using its absolute row reference
m_rs.absolute(1);
BeforeFirst()
The following code snippet demonstrates the beforeFirst() method. It moves the cursor
before the first value in the result set.
// Moving before the first row
m_rs.beforeFirst();
AfterLast()
The following code snippet demonstrates the afterLast() method. It moves the cursor
after the last value in the result set.
// Move after the last row
m_rs.afterLast();

PointBase
Version 4.8 PointBase Developer 26
Relative()
The relative() method moves the cursor to the specified position relative to the current
position of the cursor. This code snippet demonstrates how to move the cursor two rows
forward from the current position of the cursor.
// Move cursor relative to current position
m_rs.relative(2);
Next()
The following code snippet demonstrates the next() method. It moves the cursor to the next
row in the result set m_rs.
// Move the cursor to the next entry in the result set
m_rs.next();
Setting the Direction of the Cursor in Scrollable Result Sets
When you change the direction of the cursor, it effectively reverses all of the previous
methods. To set the direction of the cursor you must use the set.FetchDirection()
method. The fetch direction is set to FETCH_FORWARD by default, and the cursor moves in
the forward direction. PointBase supports the two following fetch directions:
FETCH_REVERSE
The following code snippet demonstrates how to reverse the direction of the cursor in the
scrollable result set.
// Set the cursor to scroll backwards through the Result Set
m_rs.setFetchDirection(ResultSet.FETCH_REVERSE);
As an example of cursor behavior with the fetch direction set to FETCH_REVERSE, if you
call the beforeFirst() method, the cursor is moved after the last row of the result set.
FETCH_FORWARD
The following code snippet demonstrates how to set the fetch direction of the scrollable result
set to FETCH_FORWARD.
// Set the cursor to scroll forwards through the result set
m_rs.setFetchDirection(ResultSet.FETCH_FORWARD);
Retrieving Information About a Result Set
The following examples describe how to retrieve information about a result set. This example
refers to only a few of the methods available for retrieving information about the result set.
Refer to JDBC API documentation at http://java.sun.com or your JDBC reference for a
comprehensive list of the available methods, and “Appendix B: Unsupported JDBC Methods
in PointBase,” for the list of methods that PointBase does not support.

PointBase
Version 4.8 PointBase Developer 27
ResultSet.getType()
The resultSet.getType() method can return TYPE_SCROLL_INSENSITIVE or
TYPE_FORWARD_ONLY. The following code snippet describes how to get the type of the
result set m_rs.
// Check if result set is scroll insensitive
m_rs.getType()
ResultSet.getConcurrency()
The getConcurrency() method can return CONCUR_READ_ONLY or
CONCUR_UPDATEABLE. The following code snippet describes how to get the concurrency
of the result set m_rs.
// Check the concurrency of the result set
m_rs.getConcurrency()
ResultSet.getMetaData()
The getMetaData() method obtains information about the result set, for example, the
column names and column data types. The following code snippet describes how to get the
meta data of the result set m_rs.
// Retrieve Result Set Meta Data to obtain result set properties
m_rsmd = m_rs.getMetaData();
Setting the Number of Returned Rows in Scrollable Result Sets
The following code snippets demonstrate how to set the fetch size or number of returned rows
in a scrollable result set using two different methods. This is applicable to PointBase Server
Option only. Also note that in most cases the default fetch size is optimal.
ResultSet.setFetchSize( int p_Rows )
The result set can change its default fetch size using this method. It will only affect the
specified result set.
m_rs.setFetchSize(2);:
To set the default fetch size for all result sets created by a statement object, you can use the set
fetch size using the Statment object. This method affects all result sets generated by this
statement. For example:
Statement.setFetchSize( int p_Rows )
Updating Row Values in Scrollable Result Sets
To update a row value in a result set, PointBase provides you with four different methods.
Among their uses, you can set the row value of the result set that you want to update and most
importantly, perform the actual update to the underlying database. PointBase also provides two
additional methods that you can use to perform the following: cancel all updates to a row or
verify a row value you just updated.

PointBase
Version 4.8 PointBase Developer 28
updateXXX( )
To update a row value in a result set, you must first set the value using the method,
updateXXX(). It has two different forms:
• update<datatype>( int columnPosition, value )
• update<datatype>( String columnName, value )
This method supports all PointBase data types. The following example sets the quantity
column value in the current row to 150 using the Int data type:
// m_rs.updateInt() method updates the field in question with supplied integer value
m_rs.updateInt("quantity", 150);
updateRow( )
To update the row value of the actual underlying database on the next transaction commit, you
use the method,
updateRow(). After updating a row value, you will be able to view your
updated row value in the current result set. The following is an example of how to use this
method:
// m_rs.updateRow() method updates the row in the database.
m_rs.updateRow();
rowUpdated( )
To verify that you updated the row value in the underlying database, you may use the method,
rowUpdated(). The following is an example of how to use this method:
m_rs.rowUpdated()
cancelRowUpdates( )
To cancel the updated row value in the result set, you may use the method,
cancelRowUpdates(). You cannot cancel the update if you have already made the change to
the underlying database; that is, you cannot cancel the update after calling the
updateRow()
method. The following is an example of how to use this method:
// m_rs.cancelRowUpdates() cancels in case a wrong update has been made.
m_rs.cancelRowUpdates();
Inserting Rows Into Scrollable Result Sets
To insert a new row into a result set, PointBase provides you with four methods. Using them,
you perform the following things: place the cursor to the insertion row in case it is not
currently on the row, to which you want to insert; set the new values of the row, similar to
updating a row value; and, insert a new row making it permanent to the underlying database.
After inserting a new row, you must use another method to move the cursor from the insertion
row to the current row, a non-insertion row.
moveToInsertRow( )
To move the result set cursor to the row into which you want to insert, you must use the
method,
moveToInsertRow(). The following is an example of how to use this method:
m_rs.moveToInsertRow();
updateXXX( )
You must use the method,
updateXXX() to set the row values for the new row, as you similarly
used this method to update a row value. See previous section on updating row values.

PointBase
Version 4.8 PointBase Developer 29
insertRow()
To permanently insert the new row into the underlying database on the next transaction
commit, you use the method,
insertRow(). The following is an example of how to use this
method:
m_rs.insertRow();
moveToCurrentRow( )
To move the cursor to a non-insertion row, if you do not want to insert another row, you must
use the method,
moveToCurrentRow(). The following is an example of how to use this
method.
m_rs.moveToCurrentRow();
Deleting Rows From Scrollable Result Sets
To delete rows from result sets, PointBase provides you with two methods. For example, one
method deletes the row permanently from the underlying database on the next transaction
commit. The second method verifies if the row has been deleted from the database. Please note
that if you try to retrieve a deleted row value from the current result set, PointBase will return
only NULL values.
deleteRow( )
To permanently delete a row from the underlying database, use the method,
deleteRow(). The
following is an example of how to use this method:
// Deleting currentrow.
m_rs.deleteRow();
rowDeleted( )
To verify whether or not a row still exists in the current result set, use the method,
rowDeleted(). The following is an example of how to use this method:
mrs.rowDeleted();
Viewing Changes to Current Result Sets
To view changes made to a row in the current result set by other users, the row must be in a
result set that was defined with the TYPE_SENSITIVE property. All values are also refetched
subject to the transaction-isolation level. If the result set was created with the required
properties, you can call the ResultSet method, “refreshRow().”
It refreshes the current row with its most recent value in the database. This method cannot be
called when the result set cursor is on the insert row, however. The following is an example of
how to use the “refreshRow()” method.
mrs.refreshRow();

PointBase
Version 4.8 PointBase Developer 30
If you also specified the result set with the property, CONCUR_UPDATEABLE, you may
want to use the “refresh()” method before calling the “udpateRow()” method to verify the
newest row values. The following is an example of how to verify the newest row values before
calling the “updateRow()” method.
mrs.refresh();
// Verify row values are correct
mrs.updateRow();
Flushing the Database Log
The following examples describe how to switch to a fresh database log file. The old log file is
deleted as soon as it is no longer required by the DBMS. The database log file is flushed in
different ways for embedded and server option. The code snippets below illustrate log file
switching fro both products:
// Switch log file for PointBase Embedded
((com.pointbase.jdbc.jdbcConnection)m_conn).switchLogFile();
// Switch log file for PointBase Server Option
((com.pointbase.net.netJDBCConnection)m_conn).switchLogFile();
Performing Batch Operations
The following examples demonstrates how to perform batch operations. Batch updates can
improve performance for large numbers of SQL operations. You can use them for any SQL
operation that returns an integer update count, but not a result set for example, INSERT,
UPDATE, or DELETE. You can also use batch operations for any SQL DDL statement, for
example, CREATE TABLE, DROP TABLE, or ALTER TABLE.
NOTE: Batch updates offer the most significant performance improvement when used with
PointBase Server Option, due to reduced network access.
The following code snippet demonstrates the creation of a prepared statement, binding of
variables, and adding the prepared statement to a batch using the
preparedStatement.addBatch() method. The batch is executed, using the
preparedStatement.executeBatch() method, once all the required prepared
statements have been added.
// Create a SQL statement for the batch update
String SQL_BATCH_UPDATE = "UPDATE sales_tax_code_tbl SET effect_date = ?, rate = ? where
state_code = ?";
// Prepare a statement
m_prepStmt = m_conn.prepareStatement(SQL_BATCH_UPDATE);
for (int i=0; i<=9; i++)
{
// Binding variables to the prepared statement
m_prepStmt.setDate(1, java.sql.Date.valueOf(BATCH_DATA[1][i]));
m_prepStmt.setFloat(2, (float)Float.valueOf(BATCH_DATA[2][i]).floatValue());
m_prepStmt.setString(3, BATCH_DATA[0][i]);
// Adding the prepared statement to the batch
m_prepStmt.addBatch();
}

PointBase
Version 4.8 PointBase Developer 31
// Execute the batch
int[] updateCounts = m_prepStmt.executeBatch();
NOTE: If Auto commit is set ON, the transaction will be committed when the
preparedStatement.executeBatch() method is called.
Retrieving Data From BLOB Columns
The following code snippet shows how the sample application retrieves BLOB values from the
result set using the getBLOB() method to retrieve the column value. The final two operations
create a binary stream from the BLOB object to read it into a byte array. This byte array can
then be used as required by your application.
// Retrieve the BLOB containing the sales rep image from the second column of
// the result set and find out its length
Blob image = m_rs.getBlob(2);
int lob_length = (int)image.length();
// Create a Buffered input stream from the BLOB data and read it into a byte
// array
BufferedInputStream bufferedInStream = new BufferedInputStream( image.getBinaryStream()
);
byte[] byteBuffer = new byte[ lob_length ];
bufferedInStream.read( byteBuffer, 0, lob_length );
bufferedInStream.close();
Retrieving Data From CLOB Columns
The following code snippet shows how the sample application retrieves CLOB values from the
result set using the getCLOB() method to retrieve the row value. The final two operations
create a character stream from the CLOB object to read it into a character array. This character
array can then be used as required by your application.
// Retrieve the CLOB containing the sales rep resume from the result set and determine
its length
Clob resume = m_rs.getClob(3);
lob_length = (int)resume.length();
// Create a buffered reader to read the character stream into a character array
BufferedReader bufferedReader = new BufferedReader( resume.getCharacterStream() );
char[] charBuffer = new char[ lob_length ];
bufferedReader.read( charBuffer, 0, lob_length );
bufferedReader.close();

PointBase
Version 4.8 PointBase Developer 32
Creating Functions
This section describes functions in PointBase. Using a function, you can transparently convert
data to be stored in a PointBase database. Functions may only return a single value of the type
specified in the CREATE FUNCTION SQL statement. To create a function (stored function),
you must use the CREATE FUNCTION statement and specify an external Java method for the
stored function to invoke. This section explains how to create and use stored functions in
PointBase.
External Java Methods and Functions
In PointBase, functions may be implemented using external Java methods. These user-defined
methods manipulate SQL data when the function is called by the database. This java method can
be static or non-static. If it is non-static, a connection object will be established during function
invocation, so a non-static member variable of type java.sql.connection and a constructor having
a parameter of type java.sql.connection needs to be implemented. If it is static, the method is
called directly and no connection object will be established during function invocation.
Creating an External Function
Suppose you want to INSERT a european formatted date into a table making sure that the date
format is Y2K compatible. The following external Java method, dateConvert, is called from the
stored function in the database. This external Java method converts a date from dd-mm-yyyy to
yyyy-mm-dd, and then converts it to a java.sql.Date type.
public static java.sql.Date dateConvert(String p_value)
{
String l_day = new String(p_value.substring(0,2));
String l_month = new String(p_value.substring(2,6));
String l_year = new String(p_value.substring(6,10));
return(java.sql.Date.valueOf(l_year + l_month + l_day));
}
Specifying the External Function in a Stored Function
To invoke the dateConvert external Java method from a stored function, you must use the
CREATE FUNCTION statement. The dateConvert external Java method is called from the
class, SampleExternalMethods.
In order for the database to access this external Java method, the class SampleExternalMethods
must be included in the database CLASSPATH. For PointBase Embedded - Server Option, it
must be in the Server CLASSPATH, but not in the Client CLASSPATH.
If PointBase Server is run with the Java Security Manager, in the java policy file grant
’com.pointbase.sp.spPermission’ to the class that implements the external Java method.
An "spPermission" consists of a class name with no action. The class name is a name of a class
that could be used in creating a Stored Procedure in PointBase. The naming convention follows
the hierarchical property naming convention and that is supported by
"java.security.BasicPermission". An asterisk may appear by itself, or if immediately preceded
by ".", may appear at the end of the name, to signify a wildcard match. The name cannot
contain any white spaces.

PointBase
Version 4.8 PointBase Developer 33
Examples:
a.b.c.d a fully qualified class name
a.b.* any class in any package that starts with "a.b."
* any class in any package
An "spPermission" is needed only to create a function and not for executing the
function. A stored procedure is always executed in its own protection domain that is
security controlled. The administrator can configure permission for a group of stored
procedures or any individual stored procedure..
// SQL statement to Create a function
String SQL_CREATE_FUNC = "CREATE FUNCTION dateConvert( IN P1 VARCHAR(20) )"
+ " RETURNS Date"
+ " LANGUAGE Java"
+ " NO SQL"
+ " EXTERNAL NAME \"SampleExternalMethods::dateConvert\""
+ " PARAMETER STYLE SQL";
// Create a statement and execute the SQL
m_stmt = m_conn.createStatement();
m_stmt.executeUpdate(SQL_CREATE_FUNC);
// Close the statement
m_stmt.close();
NOTE: The stored function converts the data before inserting it into the database, and after
selecting data from the database.
Using the Function
The following code snippet describes how the dateConvert function is used in a SELECT
statement by the Sample Database Application.
// SQL SELECT using the external function to convert the date in the WHERE clause
String SQL_USE_FUNC = "SELECT city FROM office_tbl WHERE open_date ="
+ " dateConvert(’01-02-1993’)";
// Create the statement
m_stmt = m_conn.createStatement();
// Execute the statment
m_rs = m_stmt.executeQuery(SQL_USE_FUNC);
Creating Stored Procedures
You can create and use PointBase stored procedures in a similar way to functions. Stored
Procedures may also use external Java methods to perform the procedure action. In addition,
stored procedures may take any number of input parameters and return any number of output
parameters, unlike functions which may only return one parameter. Stored procedures are
invoked explicitly using JDBC callable statements or may be invoked using the CALL
command in a trigger action. However, they cannot be invoked within SQL statements like a
function.
The java method can be static or non-static. If it is non-static, connection object will be
established during function invocation, so a non-static member variable of java.sql.connection

PointBase
Version 4.8 PointBase Developer 34
and a constructor having parameter java.sql.connection needs to be implemented. If it is static,
the method is called directly and no connection object will be established during function
invocation.
If PointBase server is run with Java Security Manager, in the java policy file grant
’com.pointbase.sp.spPermission’ to the class that implements the external Java method. For
more details refer to the earlier section "Specifying the External Function in a Stored Function"
Using INOUT and OUT Parameters
When using a stored procedure with Java external methods, special care must be taken to
properly handle parameters passed to the procedure. Parameters may be of type IN, OUT, or
INOUT. Java passes arguments by value, not by reference; therefore, it is generally impossible
to use stored procedures with argument values that need to be returned through the parameters.
PointBase has added special JDBC Wrapper classes to remedy this issue. This section explains
how you can use this wrapper with INOUT and OUT parameters.

PointBase
Version 4.8 PointBase Developer 35
Using JDBC Wrapper Classes
The jdbcInOut Wrappers are used by the database to enable the database to return values from
Java methods using Callable Statements. They are only required for OUT or INOUT
parameters. Each wrapper class has two constructors, a get and set method, and a toString
method. The wrapper classes are contained in the package "com.pointbase.jdbc" included in
your PointBase jar file.
The wrapper name corresponds to the JAVA data type represented by the wrapper. All
mappings between SQL and JAVA data types are compliant with the JDBC specification. For
the JDBC Binary and BLOB data types, a wrapper is not required, and a Java byte array is
passed as the input argument to your Java method.
• jdbcInOutDateWrapper—>Date Data Type
• jdbcInOutTimeWrapperTime—>Time Data Type
• jdbcInOutTimeStampWrapper—>TimeStamp Data Type
• jdbcInOutBooleanWrapper—>Boolean Data Type
• jdbcInOutLongWrapper—>BigInt Data Type
• jdbcInOutDoubleWrapper—>Double and Float Data Types
• jdbcInOutFloatWrapper—>Real Data Type
• jdbcInOutIntWrapper—>Integer Data Type
• jdbcInOutStringWrapper—>Char, Varchar, Clob Data Types
• jdbcInOutShortWrapper—>SmallInt Data Types
• jdbcInOutBigDecimalWrapper—>Decimal and Numeric Data Types
• jdbcInOutByteArrayWrapper —>BLOB Data Type
Creating an External Procedure Using JDBC Wrapper Classes
The code snippet below defines the getCost external procedure found in the class
SampleExternalMethods. Initially, you must first use a constructor to obtain a connection to
the database.
*/
import java.sql.*;
import com.pointbase.jdbc.jdbcInOutDoubleWrapper;
public class SampleExternalMethods
{
// A connection object to allow database callback
private Connection m_conn;
// Constructor accepts a java.sql.Connection object to allow database callback
public SampleExternalMethods(Connection p_conn)
{
m_conn = p_conn;
}

PointBase
Version 4.8 PointBase Developer 36
The following Java method is called as a stored procedure by the database. Procedure uses the
net order cost (INOUT) and state code (IN) to return the net order cost (INOUT). This
particular procedure also makes a callback into the database
NOTE: A jdbcInOutDoubleWrapper is passed into this method as an argument rather than the
FLOAT JDBC data type that was bound to the callable statement.
public static void getCost(String p_productInfo, String p_state, jdbcInOutDoubleWra
pper p_price)
{
try
{
// Query the database for the sales tax rate
Statement l_stmt = l_conn.createStatement();
ResultSet l_rs = l_stmt.executeQuery( "SELECT rate FROM public.sales_tax_cod
e_tbl"
+ " WHERE state_code =’" + p_state + "’"
);
// Calculate the totoal cost of the item using the sales tax rate
// obtained from the database.
l_rs.next();
float total_cost = (float)p_price.get() * (1 + (l_rs.getFloat(1)/100));
// Bind the total cost to the INOUT variable to return
p_price.set(total_cost);
// Close the result set
l_rs.close();
// Close the statement
l_stmt.close();
}
Executing a Stored Procedure
To allow a stored procedure to call out from the database system to an external procedure,
follow these two mandatory steps:
Create a stored procedure in the database.
The code snippet below shows how to create stored procedure, getCost in PointBase, where
EXTERNAL NAME refers to the class and the getCost external procedure.
In the following example, getCost is a method contained within the class
SampleExternalMethods.
// SQL statement to create a stored procedure
String SQL_CREATE_PROC = "CREATE PROCEDURE getCost(IN P1 VARCHAR(20), IN P2
VARCHAR (2), INOUT P3 FLOAT )"
+ " LANGUAGE JAVA"
+ " SPECIFIC getCost"
+"NOSQL"
+ " EXTERNAL NAME \"SampleExternalMethods::getCost\""
+ " PARAMETER STYLE SQL";
// Create a SQL statement
m_stmt = m_conn.createStatement();
// Execute the SQL

PointBase
Version 4.8 PointBase Developer 37
m_stmt.executeUpdate(SQL_CREATE_PROC);
// Close the statement
m_stmt.close();
Create a JDBC CallableStatement that executes the stored procedure.
The code snippet below is an example of how to create a CallableStatement that invokes the
stored procedure.
You must set the appropriate inbound arguments with values. After the execution of the
CallableStatement, you may obtain the values for each applicable outbound argument.
// Create SQL to invoke stored procedures
String SQL_USE_PROC = "{ call getCost(?,?,?) }";
// Create a callable statement with three binding parameters
m_callStmt = m_conn.prepareCall(SQL_USE_PROC);
m_callStmt.setString(1, m_productInfo);
m_callStmt.setString(2, "CA");
m_callStmt.setFloat(3, 449.00F);
m_callStmt.executeQuery();
// Close the callable statement
m_callStmt.close();
For further details on OUT and INOUT parameters, see ‘JDBC API Tutorial and Reference’,
Second Edition, Sun Microsystems, by White, Fisher, Cattell, Hamilton and Harper.
Connecting to Multiple Databases
You can connect to multiple databases in the same VM using Pointbase Embedded. All
databases must be in the same directory specified by database.home parameter.
Pointbase.ini
Pointbase.ini behavior is not changed in this case. There will be only one Pointbase.ini used in
the same VM. Any setting in Pointbase.ini file may apply to all databases opened in the same
VM.
Transactions
Each connection will have its own transaction, which means every connection works
independently to each other. They may start, commit or rollback their own transactions.
Shutdown Command
Shutdown command will shutdown one database, which the current connection connects to. It
will not shut down all databases opened in the VM. For shutting down all databases, user may
have to shutdown every database opened in the VM one by one.
Backup Command
Same as shutdown command, backup command will only backup one database, which the
current connection connects to.

Version 4.8 PointBase Developer 38
Basic SQL Data Objects
This section describes basic data objects relative to PointBase Embedded. It describes each
data object individually and explains how PointBase data objects interact with one another.
Read this chapter before creating a database to fully understand the behavior of each data
object within PointBase Embedded.
Data Objects Within PointBase Embedded
The following diagram illustrates the relationship between basic data objects in PointBase
Embedded. The database itself is a data object that encompasses all other data objects. A
database contains Schema objects, which in turn contain Table objects. Tables whose values
are derived from other tables are called Derived Tables or Views. Finally, a Column is located
within a Table. Columns are the smallest data object within PointBase Embedded.
Database
Figure 1.1 PointBase Embedded Data Objects
A diagram displaying the
following data objects within a
database: user, schema, table,
column, view.
User
Column
Table
Schema
View

PointBase
Version 4.8 PointBase Developer 39
Database
PointBase Embedded can contain one or more database(s). A database is at the highest level of
abstraction and is simply an operating system file. PointBase stores all data in dbn files and all
log information in wal files. For example, the sample database file is “sample.dbn” and the
sample log file is “sample.wal.” You can locate these files in the directory, “<install
directory>\databases.”
PointBase automatically creates other .dbn or .wal files like sample$$1.dbn or
sample$$1.wal when a .dbn or .wal file reaches its maximum size. All automatically
created .dbn and .wal files have the same page size as the original .dbn or .wal file.
Database Size Limit
For the default page size of 4 K, the database size is limited to 0.5 terabytes. If the default page
size is 1 K, the database size is limited to 128 GB, and for the default page size of 32 K, the
database is limited to 4 terabytes.
Because PointBase supports multiple page sizes for a database, the previous limits are true
assuming that the database does not use additional page sizes. If the database has more than
one page size, the database size limit increases. For example, if the database has two different
page sizes, one page size of 4K (0.5 terabytes), plus another page size of 32K (4 terabytes), the
total database size limit is 4.5 terabytes.
Concurrent Databases
PointBase supports multiple databases, but only one database concurrently. If multiple
connections are made to PointBase Embedded, then each connection needs to access the same
database. When the set of connections to a particular database is completed, then the next set of
connections can be initiated to another database.
Typically, multiple databases separate data for different applications. Schemas can be used to
accomplish the same effect. Refer to “Schemas” in this chapter for more information
Read-Only Support
Using PointBase, you may query a database on a CD. In this section we use the term “read-
only database,” when the database files are on a CD or, when the database files are set to the
operating system property “read-only.” PointBase supports only SELECT statements for read-
only databases. Using any other statements, such as INSERT, CREATE TABLE,... etc. with a
read-only database causes PointBase to throw an exception. The error message states “Invalid
statement.”
To have a database on a CD, you must first create the database on a writable drive. After
creating the database, connect to it using the PointBase Commander or any Java program [see
PointBase System Guide], and then close the connection without performing any other
operations during the connection.

PointBase
Version 4.8 PointBase Developer 40
By performing this step, you ensure that all the data is completely recovered from the log
(.wal) before loading the .dbn and .wal files on a CD. You cannot recover data from a
database on a CD. If the database on a CD needs recovery, the application terminates with the
following message on the screen (standard system output): “Database needs recovery from log.
This version does not support recovery.”
To connect to the database on CD or any other location use the pointbase.ini file’s
"database.home" parameter or the Java command line -D option to specify the location of
the database. See the PointBase System Guide for more information about starting PointBase.
Restrictions
Operations that involve writing to the database (dbn) or log (wal) files are not allowed.
Additionally, PointBase does not allow the following statements, because they use temporary
tables and writes into the database.
• Non-correlated subqueries that are part of IN predicate
• Read-only views
• Scrollable Cursors
User
Databases contain collections of users. Users are a means of providing security at the schema
level. Each schema has explicit user(s) associated with it, one of which must own the schema.
The schema owner has full access to the schema and determines the access privileges of the
other users. To manage users, use the CREATE USER and DROP USER SQL statements.
When you create a PointBase database using PointBase Commander, PointBase Console, or
the JDBC API, the system creates a default user PBPUBLIC with the password PBPUBLIC
who owns the default schema PBPUBLIC. Only the PBSYSADMIN, the database owner, or
users with the PBDBA role may create new users. (See "SQL Security and Privileges" on page
102.)
You cannot connect to a database as a user who does not exist in the SYSUSERS table, which
is one of the system tables in the POINTBASE schema. For a list of predefined system tables
and their attributes within the POINTBASE schema, please refer to “Appendix A: System
Tables” of the PointBase System Guide.

PointBase
Version 4.8 PointBase Developer 41
Schema
Databases contain collections of independent schemas. A schema is a logical grouping of
tables, indexes, triggers, routines, and other data objects under one qualifying name.
Internationalization characteristics and user-level security can also be defined for schema
objects.
When a database is created using PointBase Commander, PointBase Console, or the JDBC
API, PointBase Embedded creates two schemas:
• An internal schema called POINTBASE, in which the system keeps all of the system
catalogs and tables
• A default schema called PBPUBLIC
You cannot create any user-defined data objects within the POINTBASE schema. For a list of
predefined system tables and their attributes within the POINTBASE schema, please refer to
“Appendix A: System Tables” in the PointBase System Guide.
Previous Schema PUBLIC
In versions 4.1 and earlier, PointBase used the default schema, PUBLIC. By default, it also has
the password and user, PUBLIC. These names will still remain effective in versions 4.2 and
later; however, PointBase will now use PUBLIC for superficial purposes only. That is, you
may still connect to the database using PUBLIC. But internally, PointBase converts the user
and the password, PUBLIC, to PBPUBLIC every time you connect, and PointBase recognizes
the schema, PUBLIC as if it were the schema, PBPUBLIC. Additionally, you cannot drop the
superficial schema name, PUBLIC. However, you may create and later drop a new schema
called PUBLIC, and PointBase will not affiliate it with the schema, PBPUBLIC.
Schema Owners
The PointBase predefined user, PBPUBLIC, with the password, PBPUBLIC, is the owner of
the PBPUBLIC schema and has full access to all objects within this schema. The predefined
user, PBSYSADMIN, has access to all objects in the database. (See "Predefined Users" on
page 103.)
Unless you specify a different user explicitly, you automatically become the owner of a schema
if you created it. The schema owner has full access privileges and must grant access privileges
to other users for them to access that schema. PointBase recommends that you create new
schemas with the same name as your user name (if you are the schema owner) or with the same
names as the user who owns the schema. When you access the database, PointBase will
automatically search for the schema with the same name as the current user, making this the
current schema.
Schema Referencing
Data objects are mapped to the current schema by default, without the need for an explicit
reference. The CURRENT_SCHEMA special register contains the name of the current
schema. Please refer to the “SQL Scalar and Aggregate Functions” chapter in this guide for
more information about the CURRENT_SCHEMA special register.

PointBase
Version 4.8 PointBase Developer 42
In databases with multiple schemas, data objects must explicitly reference the schema for
which they are intended. If no explicit reference is made, PointBase automatically tries to
associate the data object with the current schema. If the data object cannot be logically
associated with the current schema, it references the default (PBPUBLIC) schema.
In databases with multiple schemas, when referencing a data object that is not in the current
schema, you must append the schema name to the data object name, separated by a period. For
example, if you have a schema named Employee_Info, which contains a table named
Employees. Then, you must refer to that table in the following way:
Employee_Info.Employees
Managing Schemas
To manage schemas, use the CREATE SCHEMA and DROP SCHEMA SQL statements.
CREATE SCHEMA initially creates a schema and conversely, DROP SCHEMA drops a
schema. The user that creates the schema owns the schema unless the optional
AUTHORIZATION qualifier is used to specify another user. The schema owner can grant
applicable privileges to the appropriate users.
Table
A table is comprised of a number of column objects and contains rows of data. A row is a
nonempty sequence of values that correspond to the column objects in the table. Every row of
the same table has the same number of columns and contains a value for every column of that
table.
The following are three types of tables used in PointBase Embedded:
• Base Table: a table whose data is actually stored in the database.
• Derived Table: a table obtained from other tables directly or indirectly through the
evaluation of a query expression.
• Global Temporary Table: a table that persists data for as long as the current database
connection or transaction exists. The table definition, however, persists until you
manually drop it from the database. Please see sdf for more information about creating
global temporary tables and their behavior.
NOTE: Due to known limitations, it is highly recommended that you always use uppercase
letters when specifying table names or column names wherever applicable.
Derived Table
A derived table is a table derived directly or indirectly from one or more other tables by the
evaluation of a <query expression> whose result has an element type that is a row type. The
values of a derived table are derived from the values of the underlying tables when the <query
expression> is evaluated.
A viewed table is a named derived table defined by a <view definition>. A viewed table is
sometimes
called a view.

PointBase
Version 4.8 PointBase Developer 43
View
A view is a derived table with a name. They provide an alternative way to look at the data of
one or more tables. This view derives its values from the evaluation of a query expression in a
CREATE VIEW statement. The query expression can reference base tables, other views,
aliases, etc. Essentially, a view is a stored SELECT statement, of which you can retrieve the
results at a later time by querying the view as though it were a table. See also "CREATE
VIEW" on page 132. A view can be read-only or updateable. Currently, PointBase supports
Read-Only Views only.
The definition of each view is stored in PointBase’s system catalog SYSVIEWS. If no errors
are encountered, PointBase adds the view name to the SYSVIEWS catalog table. Additionally,
all referenced columns of all referenced tables will be added to the SYSVIEWTABLES
catalog table.
Security for Views
Because a view is a type of table, you can grant privileges on it, and the privileges can be
different than the privileges on any base table from which the view was derived. Unlike base
tables, however, an owner of a view does not automatically have the authority to grant
privileges on the view to others.
To grant privileges on the view to others, you must have grant privileges on every referenced
column and table in the view's query expression. If you have privileges revoked on any of the
referenced columns or tables, you also have the same privileges revoked on the view.
Revoking privileges on a view using the RESTRICT option will raise an error, if any users of
that view had the grant option privilege and they granted that privilege to other users. If you
revoke privileges on a view using the CASCADE option, you will revoke all the users’
privileges on that view. Likewise, you must verify if the view has any dependent views, and
verify the privileges on those as well.
NOTE: Revoking privileges on a view does not affect base table privileges.
Temporary Table
A temporary table is a kind of base table. Temporary table is created by CREATE TABLE
command with TEMPORARY keyword. For temporary table, an indication of whether ON
COMMIT DELETE ROWS or ON COMMIT PRESERVE ROWS needs to be specified.
Temporary table can be global temporary, created local temporary or declared local temporary
table. PointBase only supports global temporary tables. Global temporary table is a named
table defined by a <table definition> that specifies GLOBAL TEMPORARY. Global
temporary table are effectively materialized only when referenced in a SQL-Session. Different
SQL-Sessions cause a distinct instance of that created global temporary table to be
materialized. That is, the contents of global temporary table cannot be shared between SQL-
Sessions.
A global temporary table is like persistent base table. You can insert, update, delete, create
indexes, create constraints or create triggers to a global temporary table.

PointBase
Version 4.8 PointBase Developer 44
Column
Each PointBase table can have a maximum limit of 32,000 columns and a minimum of one. All
values contained within a specific column are of the same data type and every column has an
associated default value. The system uses the default value when data is entered into a table
without specifying a value for the column. The default value for a column is NULL unless the
column specifies the NOT NULL constraint or a different default value. If a column specifies
the NOT NULL constraint and has no default value defined, then you must specify a value for
this column whenever data is inserted or updated in the table.
NOTE: Due to known limitations, it is highly recommended that you always use uppercase
letters when specifying table names or column names wherever applicable.
IDENTITY Property for Autoincrement
PointBase has autoincrement capability using the IDENTITY property. By defining it for a
column (making it an IDENTITY column), PointBase or you can generate values for every
row in a table. You can define it for only a column that has either of the data types:
• INTEGER
• SMALLINT
• NUMERIC
•DECIMAL
You can create a table with an IDENTITY column or you can add an IDENTITY column at a
later time using the ALTER TABLE statement. Please note, however, each table may have only
one IDENTITY column, and once you have created a table with an IDENTITY column or
added it at a later time, you cannot update any values in the IDENTITY column.
PointBase Generated Values
If you create, alter, or insert into a table without specifying a value for the IDENTITY column,
PointBase automatically assigns incremental values to every row in a table. If you allow
PointBase to generate the values, the default value for the first row is 1 (one). By default,
PointBase will also assign increments of 1 to the rows that follow. For example, PointBase
automatically assigns the default value of 1 to the first row of the table and continues to give
the value 2 for the second row, 3 to the third row, and so on. (See “identity_property” on page
123.) If you insert a row value into an IDENTITY column without specifying a value for the
IDENTITY column, PointBase will continue to generate incremental values based on the
highest value assigned for the column—even if the highest value was deleted. (See
“insert_column_list” on page 176.)
User-defined Values
You can also opt to specify the values yourself. If you are creating or adding the IDENTITY
column and specifying its values, you must specify the value of the first row, and you must
specify the incremental value, which affects the rest of the rows in the table. (See
“identity_property” on page 123.) If you are inserting a row value into an IDENTITY column,
you must specify only the column value. PointBase will continue to generate incremental
values based on the highest value assigned for the column—even if the highest value was
deleted. (See “insert_column_list” on page 176.) Please note that PointBase recommends that
you allow PointBase to generate the IDENTITY column values when inserting new rows.

PointBase
Version 4.8 PointBase Developer 45
Deleting Rows
Additionally, PointBase supports deleting rows from an IDENTITY column. However, once
you delete a row value from an IDENTITY column, PointBase will not generate that value
again; PointBase generates only unique values. PointBase will generate incremental values
based on the highest row value assigned for the column—even if the highest value was
deleted.

Version 4.8 PointBase Developer 46
Connection Pools
This chapter describes the Connection Pool feature implemented by PointBase. Basically a
Connection Pool is a feature to maintain a pool of connections to the database and to reduce the
need for creating new connection. The maintained pool of connections can be used and reused
by an application. It is useful when applications frequently ask for a new connection and close
it after a short usage. In PointBase the pool is maintained on the server side.
The connection pool is transparent to the user. The only requirement from the user is to use
com.pointbase.jdbc.jdbcPooledDatasource to get connection.
com.pointbase.jdbc.jdbcPooledDatasource
com.pointbase.jdbc.jdbcPooledDatasource implements the following interfaces:
javax.sql.DataSource
javax.naming.Referenceable
java.io.Serializable
Datasource Properties
A datasource object has properties to identify and describe the database that it represents.
com.pointbase.jdbc.jdbcPooledDatasource has the following properties to describe the
database. Each property has a setter and getter method

PointBase
Version 4.8 PointBase Developer 47
Connection Pool Size
Ini parameter conpool.size=<postive number> specifies the number of connections to kept in
the connection pool. The default is 10. This number specifies the number of connections that
has to be kept in the pool for reuse. If the size is set to n, then first n connections are kept in the
pool. However, there is no set limit for the number of database connections. When the database
is opened, the system does not rush to create connections to fill the connection pool. A
connection is created as and when requested.
Property
Name
Type Description Methods Default
databaseName String The name of the
database
getDatabaseName()
setDatabaseName(String)
NULL
dbIni String A list of ini parameters
for the database. Each
parameter is separated
by a ’; ’. E.g. The s t ring
"database.home=c:\\poin
tbase;cache.size=4001"
sets database.home and
cache.size ini
parameters. It is not
recommended to use
create=force parameter.
getDbIni()
setDbIni(String)
NULL
description String A description of this
datasource
getDescrition()
setDescrption(String)
NULL
user String The user id for the
database
getUser
setUser(String)
“PBPUBLIC”
password String The user's database
password
getPassword()
setPassword(String)
“PBPUBLIC”
portNumber int The port number where
a server is listening for
requests. Required for
Server Option only
getPortNumner()
setPortNumber(int)
9092
serverName String The machine name
where the database
server is running. It can
be "localhost" for the
local computer.
Required for Server
Option only.
getServerName()
setServerName(String)
NULL

PointBase
Version 4.8 PointBase Developer 48
There is no direct call to create or close the Connection Pool. When the first connection
through the Database object is requested, the Connection Pool is automatically created. The
connection pool is closed when any of the following occurs:
•SHUTDOWN SQL statement is executed
•The application that embeds PointBase exits the jvm
•In PointBase Server Option, the server is closed
PointBase Embedded or Server Option
If you’re using Server Option, you must set the port number and the server name.
If server name are set, then Pointbase will expect to find pbclient jar file in the classpath. If it is
not set, then PointBase will expect to find the pbembedded jar file in the classpath.
If pbclient jar file is found it will be used to load the driver class and look for PointBase Server.
If pbembedded jar file is found, the driver will be loaded from there and the calling application
will embed the database.
Other Methods
In addition to the methods to set and get the properties specified in the above table, the
following methods are supported.
Connection getConnection() throws SQLException
Connection getConnection(String user, String password) throws SQLException
The above methods get Connection to the database specified in the datasource. In fact what is
returned is a wrapper to the Connection. When close() is invoked on this wrapper, any open
result set or statements are closed and returned to the pool. The physical connection is not
closed. If the user and password specified in the call overrides the user and password provided
in the datasource.
One has to be cautious while setting 'create=force' through dbIni property. The first
getConnection() creates a new database by deleting any existing database in that name.
Subsequent, getConnection() calls throws SQLException.
int getLoginTimeout throws SQLException
void setLoginTimeout( int seconds) throws SQLException
The above methods set and get the login timeout. However, login timeout is not enforced by
the database.
PrintWriter getLogWriter() throws SQLException
Void setLogWriter( PrintWriter out)
The above methods get and set the IO stream for trace messages. However, as of the current
release the datasource does not write any messages

PointBase
Version 4.8 PointBase Developer 49
Creating a Datasource Object
The following code snippet shows how to created a datasource object for the connection
pooling.
jdbcPooledDatasource pds = new jdbcPooledDatasource();
pds.setDatabaseName("demo");
pds.setDescription("datasource for demo database");
pds.setUser("PBPUBLIC");
pds.setPassword("PBPUBLIC");
Connection conn = pds.getConnection();
// perform any operation on the connection
conn.close();// returns the connection to the connection pool
JNDI
It is possible to register the Datasource object with a JNDI naming service. The naming service
may be JNDI File System or LDAP or some other naming service that supports JNDI.
Registering Datasource with JNDI
File System Service Provider Example
The following method is a sample which demonstrates registering a datasource with JNDI.
/**
* Method to save the jdbcPooledDatasource object via JNDI
* This method uses the File System Service Provider for the Java Naming and
* Directory InterfaceTM (JNDI) from Sun Microsystems, available for
* download from Sun Microsystems. You must have the JARs fscontext.jar and
* providerutil.jar in the classpath.
**/
public static void saveDataSource(jdbcPooledDataSource pds) {
Properties props = new Properties();
Context ctx=null;
//create the directory if it doesn’t exist
File f = new File("c:\\jndi");
if (! f.exists()) { f.mkdir(); }
props.put(Context.INITIAL_CONTEXT_FACTORY,
"com.sun.jndi.fscontext.RefFSContextFactory");
try {
ctx = new InitialContext(props);
//the bind method will create a file called .bindings in c:\jndi
//to store values of object pds identified as jndiex
ctx.bind("c:\\jndi\\jndiex",pds);
ctx.close();
}
catch(NameAlreadyBoundException nabe) {
try {
ctx.rebind("c:\\jndi\\jndiex",pds);
ctx.close();
}
catch(Exception e) {
e.printStackTrace();
}
}
catch(Exception e) {
e.printStackTrace();
}
}//saveDataSource

PointBase
Version 4.8 PointBase Developer 50
The datasource object is created and its properties are set as shown above. The bind method
registers the datasource with the logical name "jndiex".
Readers are referred to the JNDI File System manual for further information.
LDAP example
// set all needed environment variables to access the LDAP
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY,"com.sun.jndi.ldap.LdapCtxFactory)
;
env.put(Context.PROVIDER_URL, "ldap://JUPITER:389");
// set security information, if any
// create the context and register
Context ctx = new IntialContext(env);
ctx.bind("jndiex", pds);
In the above bind statement "jndiex" is the logical name for the datasource. Readers are
referred to the LDAP manual for further information on LDAP usage.
Retrieving from JNDI
If the datasource object is registered with a JNDI naming service, to retrieve the object one
needs to set up the context and use the logical name of the datasource.
File System Service Provider Example
The following sample method shows how to retrieve the datasource object form the JNDI File
System.
/**
* Method to retrieve a jdbcPooledDatasource object via JNDI
* This method uses the File System Service Provider for the Java Naming and
* Directory InterfaceTM (JNDI) from Sun Microsystems, available for
* download from Sun Microsystems. You must have the JARs fscontext.jar and
* providerutil.jar in the classpath.
**/
public jdbcPooledDataSource getDataSource() {
Properties props = new Properties();
Context ctx;
jdbcPooledDataSource pds = new jdbcPooledDataSource();
try {
props.put(Context.INITIAL_CONTEXT_FACTORY,
"com.sun.jndi.fscontext.RefFSContextFactory");
ctx = new InitialContext(props);
//the lookup method will look in c:\jndi for file .bindings
//and will return an object with the values for jndiex,
//which can be cast as a jdbcPooledDataSource object
pds = (jdbcPooledDataSource )ctx.lookup("c:\\jndi\\jndiex");
ctx.close();
}//try
catch(Exception e) {
e.printStackTrace();
}
finally {
return pds;
}
}//getDataSource
The lookup method returns the datasource object.

PointBase
Version 4.8 PointBase Developer 51
LDAP example
The following code shows how to retrieve the datasource object from LDAP.
// set all needed environment variables to access the LDAP
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY,
"com.sun.jndi.ldap.LdapCtxFactory);
env.put(Context.PROVIDER_URL, "ldap://JUPITER:389");
// set security information, if any
// create the context and retrieve datasource object
// use the logical name used in the bind method
// cast the retrieved object to com.pointbase.jdbc.jdbcPooledDatasource
Context ctx = new IntialContext(env);
Datasource pds = (Datasource)ctx.lookup("jndiex");
The lookup method returns the datasource object.

Version 4.8 PointBase Developer 52
SQL Data Types
This chapter describes all of the SQL data types that PointBase supports. Data types define
what type of data a column can contain. The following sections describe each PointBase data
type in detail and discuss converting data types. Tables are provided at the end of the chapter to
show the mappings between PointBase data types and industry standard and other common
non-standard data types.
PointBase supports the following data types for its column and parameter declarations.
• CHARACTER [(length)] or CHAR [(length)]
• VARCHAR (length)
• BOOLEAN
• SMALLINT
• INTEGER or INT
•BIGINT
• DECIMAL [(p[,s])] or DEC [(p[,s])]
• NUMERIC [(p[,s])]
•REAL
• FLOAT(p)
• DOUBLE PRECISION
• DATE
•TIME
• TIMESTAMP
• CLOB [(length)] or CHARACTER LARGE OBJECT [(length)] or CHAR LARGE
OBJECT [(length)]
• LONGVARCHAR[(length)]
• BLOB [(length)] or BINARY LARGE OBJECT [(length)]
• BINARY[(length)]
• VARBINARY[(length)]
• LONGVARBINARY[(length)]

PointBase
Version 4.8 PointBase Developer 53
CHARACTER [(length)] or CHAR [(length)]
The CHARACTER data type accepts character strings, including Unicode, of a fixed length.
The length of the character string should be specified in the data type declaration; for example,
CHARACTER(n) where n represents the desired length of the character string. If no length is
specified during the declaration, the default length is 1.
The minimum length of the CHARACTER data type is 1 and it can have a maximum length up
to the table page size. Character strings that are larger than the page size of the table can be
stored as a Character Large Object (CLOB).
NOTE: CHARACTER(0) is not allowed and raises an exception.
If you assign a value to a CHARACTER column containing fewer characters than the defined
length, the remaining space is filled with blanks characters. Any comparisons made to a
CHARACTER column must take these trailing spaces into account.
Attempting to assign a value containing more characters than the defined length results in the
truncation of the character string to the defined length. If any of the truncated characters are
not blank, an error is raised.
Character String Examples:
CHAR(10) or CHARACTER(10)
• Valid
’Race car’
’RACECAR’
’24865’
’1998-10-25’
’1998-10-25 ’
• Invalid
24865
1998-10-25
Date: 1998-10-25
VARCHAR (length)
The VARCHAR data type accepts character strings, including Unicode, of a variable length is
up to the maximum length specified in the data type declaration.
A VARCHAR declaration must include a positive integer in parentheses to define the
maximum allowable character string length. For example, VARCHAR(n) can accept any
length of character string up to n characters in length. The length parameter may take any value
from 1, to the current table page size minus 42 bytes. For example, the maximum length
parameter for a page size of 4k (4096) would be 4096 minus 42 bytes, equaling 4054 bytes.
Attempting to assign a value containing more characters than the defined maximum length
results in the truncation of the character string to the defined length. If any of the truncated
characters are not blank, an error is raised.

PointBase
Version 4.8 PointBase Developer 54
NOTE: VARCHAR(0) is not allowed and raises an exception.
If you need to store character strings that are longer than the current table page size, the
Character Large Object (CLOB) data type should be used.
Examples
VA RC HAR (1 0 )
• Valid
’Race car’
’RACECAR’
’24865’
’1998-10-25’
’1998-10-25 ’
• Invalid
24865
1998-10-25
Date: 1998-10-25
BOOLEAN
The BOOLEAN data type accepts a single value that can be TRUE or FALSE. No parameters
are required when declaring a BOOLEAN data type.
Use the case insensitive keywords TRUE or FALSE to assign a value to a BOOLEAN data
type. Comparisons using the BOOLEAN data type should also use these keywords. If you
attempt to assign any other value to a BOOLEAN data type, an error is raised.
Examples
BOOLEAN
• Valid
TRUE
true
True
False
• Invalid
1
0
Yes
No

PointBase
Version 4.8 PointBase Developer 55
SMALLINT
The SMALLINT data type accepts a 16 bit signed integer value with an implied scale of zero.
It stores any integer value between the range 2^ -15 and 2^15 -1. Attempting to assign values
outside this range causes an error.
If you assign a numeric value with a precision and scale to a SMALLINT data type, the scale
portion truncates, without rounding.
NOTE: To store values beyond the range (2^-15) to (2^15)-1, use the INTEGER data type.
Examples
SMALLINT
• Valid
-32768
0
-30.3 (digits to the right of the decimal point are trun-
cated)
32767
• Invalid
-33,000,567
-32769
32768
1,897,536,000
INTEGER or INT
The INTEGER data type accepts a 64-bit signed integer value with an implied scale of zero. It
stores any integer value between the range 2^ -31 and 2^31 -1. Attempting to assign values
outside this range causes an error.
If you assign a numeric value with a precision and scale to an INTEGER data type, the scale
portion truncates, without rounding.
NOTE: To store integer values beyond the range (2^-31) to (2^31)-1, use the DECIMAL data
type with a scale of zero.

PointBase
Version 4.8 PointBase Developer 56
Examples
INTEGER or INT
• Valid
-2147483648
-1025
0
1025.98 (digits to the right of the decimal point are
truncated)
2147483647
• Invalid
-1,025,234,000,367
-2147483649
2147483648
1,025,234,000,367
BIGINT
The BIGINT data type can accept numeric values up to 8 bytes. It can be used in place of the
LONG data type. It stores any integer value between the range of 9223372036854775807 and
-9223372036857447808. Attempting to assign values outside this range causes an error.
Examples
BIGINT
• Valid
-3372036857447808
-857447808
0
23372036854775807
• Invalid
-1,025,234,000,367
-9999999999999999999
9999999999999999999
1,025,234,000,367

PointBase
Version 4.8 PointBase Developer 57
DECIMAL [(p[,s])] or DEC [(p[,s])]
The DECIMAL data type accepts fixed-precision decimal values, for which you may define a
precision and a scale in the data type declaration. The precision is a positive integer that
indicates the number of digits that the number will contain. The scale is a positive integer that
indicates the number of these digits that will represent decimal places to the right of the
decimal point. The scale for a DECIMAL cannot be larger than the precision.
DECIMAL data types can be declared in one of three different ways.
• DECIMAL – Precision defaults to 38, Scale defaults to 0
• DECIMAL(p) – Scale defaults to 0
• DECIMAL(p, s) – Precision and Scale are defined by the user
In the above examples, p is an integer representing the precision and s is an integer
representing the scale.
NOTE: If you exceed the number of digits expected to the left of the decimal point, an error is
thrown. If you exceed the number of expected digits to the right of the decimal point,
the extra digits are truncated.
Examples
DECIMAL(10,3)
• Valid
1234567
1234567.123
1234567.1234 (Final digit is truncated)
-1234567
-1234567.123
-1234567.1234 (Final digit is truncated)
• Invalid
12345678
12345678.12
12345678.123
-12345678
-12345678.12
-12345678.123
NUMERIC [(p[,s])]
PointBase treats the NUMERIC data type in exactly the same way as the DECIMAL data type.

PointBase
Version 4.8 PointBase Developer 58
REAL
The REAL data type accepts single-precision floating point number values, up to a precision of
32. No parameters are required when declaring a REAL data type. If you attempt to assign a
value with a precision greater than 32 an error is raised.
Examples
REAL
• Valid
-2345
0
1E-3
1.245
123456789012345678901234567890
• Invalid
123,456,789,012,345,678,901,234,567,890,123
FLOAT(p)
The FLOAT data type accepts a single or double precision floating point number value, for
which you may define a precision up to a maximum of 64. If no precision is specified during
the declaration, the default precision is 32. Attempting to assign a value larger than the
declared precision will cause an error to be raised.
Examples
FLOAT(8)
• Valid
12345678
1.2
123.45678
-12345678
-1.2
-123.45678
• Invalid
123456789
123.456789
-123456789
-123.456789
DOUBLE PRECISION
The DOUBLE PRECISION data type accepts a double precision floating point value, up to a
precision of 64. No parameters are required when declaring a DOUBLE PRECISION data
type. If you attempt to assign a value with a precision greater than 64 an error is raised.

PointBase
Version 4.8 PointBase Developer 59
Examples
DOUBLE PRECISION
• Valid
123456789012345678901234567890123456789012345678901234567890
-123456789012345678901234567890123456789012345678901234567890
• Invalid
123,456,789,012,345,678,901,234,567,890,123,123,456,789,
012,345,678,901,234,567,890
-123,456,789,012,345,678,901,234,567,890,123,123,456,789,
012,345,678,901,234,567,890
DATE
The DATE data type accepts date values, consisting of year, month, and day. No parameters are
required when declaring a DATE data type. Date values should be specified in the form:
YYYY-MM-DD. However, PointBase will also accept single digits entries for month and day
values.
Month values must be between 1 and 12, day values should be between 1 and 31 depending on
the month and year values should be between 0 and 9999.
Values assigned to the DATE data type should be enclosed in single quotes. The case
insensitive keyword, DATE, may or may not precede the value, for example: DATE ‘1999-04-
04’ or ‘1999-04-04.’ Note that, PointBase does not determine the SQL type of the Literal
(keyword + String value) by parsing the String value and checking for DATE patterns. That is,
PointBase determines the SQL type from the operation. For example:
CREATE TABLE T1(C1 VARCHAR(20));
CREATE TABLE T2(C1 DATE);
INSERT INTO T2 SELECT C1 FROM T1
PointBase automatically converts the value from “T1.C1” to the DATE type and inserts it into
the table “T2,” because the column into which it is inserting accepts only DATE types.
Examples
DATE
• Valid
DATE ‘1999-01-01’
DATE ‘2000-2-2’
date ‘0-1-1’
‘1999-01-01’
‘2000-2-2’
‘0-1-1’

PointBase
Version 4.8 PointBase Developer 60
• Invalid
DATE ‘1999-13-1’
date 2000-2-27
date ‘2000-2-50’
TIME
The TIME data type accepts time values, consisting of hours, minutes, and seconds. No
parameters are required when declaring a TIME data type. Date values should be specified in
the form: HH:MM:SS. An optional fractional value can be used to represent nanoseconds.
The minutes and seconds values must be two digits. Hour values should be between zero 0 and
23, minute values should be between 00 and 59 and second values should be between 00 and
61.999999.
Values assigned to the TIME data type should be enclosed in single quotes. The case
insensitive keyword, TIME, may or may not precede the value, for example: TIME ‘00:00:00’
or ‘00:00:00.’ Note that, PointBase does not determine the SQL type of the Literal (keyword +
String value) by parsing the String value and checking for TIME patterns. That is, PointBase
determines the SQL type from the operation. For example:
CREATE TABLE T1(C1 VARCHAR(20));
CREATE TABLE T2(C1 TIME);
INSERT INTO T2 SELECT C1 FROM T1
PointBase automatically converts the value from “T1.C1” to the TIME type and inserts it into
the table “T2,” because the column into which it is inserting accepts only TIME types.
Examples
TIME
• Valid
TIME ‘00:00:00’
TIME ‘1:00:00’
TIME ‘23:59:59’
time ‘23:59:59.99’
‘00:00:00’
‘1:00:00’
‘23:59:59’
‘23:59:59.99’
TIME ‘00:3:00’
• Invalid
TIME ‘00:62:00’
TIME ‘23:01’
TIMESTAMP
The TIMESTAMP data type accepts timestamp values, which are a combination of a DATE
value and a TIME value. No parameters are required when declaring a TIMESTAMP data
type. Timestamp values should be specified in the form: YYYY-MM-DD HH:MM:SS. There
is a space separator between the date and time portions of the timestamp.

PointBase
Version 4.8 PointBase Developer 61
All specifications and restrictions noted for the DATE and TIME data types also apply to the
TIMESTAMP data type.
Values assigned to the TIMESTAMP data type should be enclosed in single quotes. The case
insensitive keyword, TIMESTAMP, may or may not precede the value, for example:
TIMESTAMP ‘1999-04-04 07:30:00’ or ‘1999-04-04 07:30:00.’ Note that, PointBase does not
determine the SQL type of the Literal (keyword + String value) by parsing the String value and
checking for TIMESTAMP patterns. That is, PointBase determines the SQL type from the
operation. For example:
CREATE TABLE T1(C1 VARCHAR(20));
CREATE TABLE T2(C1 TIMESTAMP);
INSERT INTO T2 SELECT C1 FROM T1
PointBase automatically converts the value from “T1.C1” to the TIMESTAMP type and inserts
it into the table “T2,” because the column into which it is inserting accepts only TIMESTAMP
data types.
Examples
TIMESTAMP
• Valid
TIMESTAMP ‘1999-12-31 23:59:59.99’
TIMESTAMP ‘0-01-01 00:00:00’
‘1999-12-31 23:59:59.99’
‘0-01-01 00:00:00’
• Invalid
1999-00-00 00:00:00
TIMESTAMP ‘1999-01-01 00:64:00’
CLOB [(length)] or CHARACTER LARGE OBJECT [(length)] or CHAR
LARGE OBJECT [(length)] LONGVARCHAR[(length)]
The Character Large Object (CLOB) data type accepts character strings longer than those that
are allowed in the CHARACTER [(length)] or VARCHAR (length) data types. The CLOB
declaration uses the following syntax to specify the length of the CLOB in bytes:
n [K | M | G]
In the above syntax, n is an unsigned integer that represents the length. K, M, and G
correspond to Kilobytes, Megabytes or Gigabytes, respectively. If K, M, or G is specified in
addition to n, then the actual length of n is the following:
• K = n * 1024
• M = n * 1,048,576
• G = n * 1,073,741,824
The maximum size allowed for CLOB data types is 2 gigabytes. If a length is not specified,
then a default length of 2 gigabytes is used. CLOB values can vary in length from one byte up
to the specified length.

PointBase
Version 4.8 PointBase Developer 62
NOTE: The CLOB data type supports Unicode data.
BLOB [(length)] or BINARY LARGE OBJECT [(length)] LONGVARBIN-
NARY[(length)] BINARY[(length)] VARBINARY[(length)]
The Binary Large Object (BLOB) data type accepts binary values. The BLOB declaration uses
the following syntax to specify the length in bytes:
n [K | M | G]
In the above syntax, n is an unsigned integer that represents the length. K, M, and G
correspond to Kilobytes, Megabytes or Gigabytes, respectively. If K, M, or G is specified in
addition to n, then the actual length of n is the following:
• K = n * 1024
• M = n * 1,048,576
• G = n * 1,073,741,824
The maximum size allowed for BLOB data types is 2 gigabytes. If a length is not specified,
then a default length of 2 gigabytes is used if the type was BLOB or LONGVARBINARY. If
the type was BINARY or VARBINARY, then a default length of one byte is used. BLOB
values can vary in length from one byte up to the specified length.
NOTE: BLOB data types cannot be used with SQL scalar functions.
Data Conversions and Assignments
The PointBase database allows two types of data conversions - implicit and explicit. An
implicit data conversion is automatically performed between data types that are in the same
data type family. Table 1 describes the data type families supported by PointBase. Implicit data
conversions are performed as needed and are transparent to the user.
PointBase handles explicit data conversion using the SQL Scalar CAST function. This
function converts a value from one PointBase data type to another in the same data type family.
Table 1: Data Type Families and Data Types
Data Type Family Data Types
Character String CHARACTER, VARCHAR, CLOB, LONGVARCHAR
Boolean BOOLEAN
Binary String BLOB, BINARY, VARBINARY, LONGVARBINARY
Date Time DATE, TIME, TIMESTAMP
PointBase
Version 4.8 PointBase Developer 63
Number SMALLINT, INTEGER, DECIMAL, NUMERIC, REAL, FLOAT, DOUBLE
Table 1: Data Type Families and Data Types
Data Type Family Data Types
Table 2: Mapping Standard Data Types to PointBase SQL Data Types
JDBC Data Types Java Data Types PointBase SQL Data Types
BIT boolean boolean
TINYINT byte smallint
SMALLINT short smallint
INTEGER int integer
BIGINT long numeric/decimal
FLOAT double float
REAL float real
DOUBLE double double
NUMERIC java.math.BigDecimal numeric
DECIMAL java.math.BigDecimal decimal
CHAR String char
VARCHAR String varchar
LONGVARCHAR String longvarchar
DATE java.sql.Date date
TIME java.sql.Time time
TIMESTAMP java.sql.Timestamp timestamp
BINARY byte[] binary
VARBINARY byte[] varbinary
LONGVARBINARY byte[] longvarbinary

PointBase
Version 4.8 PointBase Developer 64
BLOB Blob blob
CLOB Clob clob
Table 2: Mapping Standard Data Types to PointBase SQL Data Types
JDBC Data Types Java Data Types PointBase SQL Data Types

PointBase
Version 4.8 PointBase Developer 65
PointBase also supports other non-SQL standard data types. Table 3 describes the mapping of
non-SQL standard data types from other database vendors to PointBase data types.
Table 3: Mapping Non-standard Data Types to PointBase SQL Data Types
Oracle
Data Types
Sybase and Microsoft
Data Types
DB2
Data Types
PointBase
Data Types
NUMBER DECIMAL
TINYINT SMALLINT
VARCHAR2
VARCHAR
LONGVARCHAR
TEXT LONGVARCHAR
LONG CLOB
CLOB
RAW
VARBINARY(2000)
LONGRAW LONGVARBINARY
BINARY BINARY
VARBINARY VARBINARY
IMAGE LONGVARBINARY
CHAR for
BIT DATA
BINARY
VAR CHAR
for BIT
DATA
VARBINARY

Version 4.8 PointBase Developer 66
SQL Scalar and Aggregate
Functions
This chapter describes the SQL Scalar Functions supported in PointBase. PointBase provides
these ready to use functions to perform in-statement operations when querying or inserting
data into the database. For example, you can use the CAST function to convert data types to
other data types or use a numeric function to perform calculations. The following sections
describe the behavior of these functions and examples of how to use them.
NOTE: Unless specified otherwise, when applying any of the following functions to a column
containing NULLS, the NULL rows are not counted or used and the following warning
is given:
java.sql.SQLWarning: Warning--null value eliminated in set function
To eliminate this warning and ignore the NULLs in aggregate functions, you can use the
DISTINCT keyword in front of the column reference, for example:
select (count(DISTINCT product_code)) from product_tbl
SQL Scalar Numeric Functions
The Scalar Numeric Function operates on numeric values (i.e. INTEGER, SMALLINT,
DECIMAL, FLOAT, DOUBLE and NUMERIC data types). The PointBase database supports
the following standard Numeric Functions:
• Multiplication
• Division
• Addition
• Subtraction
• ABS() - absolute value
• MOD() - remainder
The numeric functions are evaluated in the following order. Numeric Functions within
parentheses are evaluated from the innermost set of parentheses, following the same rules of
precedence:

PointBase
Version 4.8 PointBase Developer 67
1. Multiplication (*) and division (/) from left to right
2. Addition (+) and subtraction (-) from left to right
Numeric Functions are calculated as floating point numbers with a precision of 17 significant
digits (and a rounding error). However, if you use these functions when inserting or updating
data the accuracy is dependent up on the data type of the column for which the data is intended.
Examples
2 + 3 * 4 / 2 = 8
2 + (3 * 4) / 2 = 8
2 + 3 / 2 = 3.5
100/3 = + 3 / 2 = 33.333333333333333
ABS(-123)=123
MOD(100,3)=1
SQL Scalar Character String Functions
Scalar Character String Functions operate on character strings. These functions all return either
character strings or numeric values. PointBase currently supports the following functions.
CONCATENATION
The concatenation operator (||) joins the values of two or more character strings into a single
string. You may use the concatenated string expression anywhere you would use a character
string and there is no limit to the number of string expressions you can concatenate. The
following is the CONCATENATION Function syntax:
string_value || string_value [{|| string_value}...]
Examples:
’$’ || ’ ’ || ’150’ ----> ’$150’
SELECT order_num, sales_tax_st_cd, 'Shipping Cost', '$' || shipping_cost FROM order_tbl
WHERE shipping_cost > 300 AND UPPER(sales_tax_st_cd) NOT LIKE '%FL' ORDER BY order_num
ASC;

PointBase
Version 4.8 PointBase Developer 68
SUBSTRING
The SUBSTRING Function extracts a specified portion of the character string on which it is
operating. The following is the SUBSTRING Function syntax:
SUBSTRING (string_value FROM start [FOR length])

PointBase
Version 4.8 PointBase Developer 69
In the previous syntax, the start variable is an integer that represents the starting position for
the sub string. The first character in a string is considered to be position 1. The length variable
is optional and indicates the length of the sub string; if it is missing, the SUBSTRING Function
returns the characters from the start position to the end of the character string.
Examples
SUBSTRING(’George Valentie’ FROM 3) ----> ’orge Valentine’
SUBSTRING(’George Valentie’ FROM 3 FOR 2) ----> ’or’
CHARACTER_LENGTH
The CHARACTER_LENGTH function returns the length of a character string as the numeric
data type. There are two syntax variations for the CHARACTER_LENGTH function:
1. CHARACTER_LENGTH (string_value)
2. CHAR_LENGTH (string_value).
Examples
CHAR_LENGTH(’George Valentine’) ----> 16
CHARACTER_LENGTH(’$150’) ----> 4
POSITION
The POSITION function searches for a specified string pattern in another string. If the pattern
is found, a value is returned that indicates the beginning position of the location of the pattern.
If the pattern is not found, then a value of zero is returned. If the pattern is a string length of
zero (0, a NULL string), then a value of one is returned. All returned values are of the numeric
data type. The following illustrates the syntax for the POSITION Function:
POSITION (string_pattern IN string_value)
Examples
POSITION(‘Valentine’ IN ‘George Valentine') ----> 8
POSITION(‘’ IN ‘George Valentine’) ----> 1
TRIM
The TRIM function allows you to strip trailing and/or leading characters from a character
string. The following illustrates the syntax for the TRIM Function:
TRIM (LEADING | TRAILING | BOTH 'character' FROM string_value)

PointBase
Version 4.8 PointBase Developer 70
Although it is common only to strip a blank characters (’ ’) from the start and ends of character
strings, using the TRIM function you can strip any character. The character variable, enclosed
in single quotes, represents the character that is to be stripped from the character string. The
keywords LEADING, TRAILING, and BOTH indicate whether you strip the character variable
from the front of the character string, at the end of the character string, or both.
Examples
TRIM (LEADING ‘ ‘ FROM ‘ George Valentine ‘)
----> 'George Valentine '
TRIM (TRAILING ‘ ‘ FROM ‘ George Valentine ‘)
----> ‘ George Valentine ‘
TRIM (BOTH ‘ ‘ FROM ‘ George Valentine ‘)
----> ‘George Valentine’
TRIM (LEADING ‘$’ FROM ‘$150’)
----> ‘150’
UPPER and LOWER
The UPPER function returns the value specified in the character string entirely in upper case
letters, regardless of the initial capitalization of the character string. The LOWER Function
returns the value specified in the character string entirely in lower case letters, regardless of the
initial capitalization of the character string variable. The following syntax is used for the Case
Functions:
UPPER(string_value)
LOWER(string_value)
Examples
LOWER(’George Valentine’) ----> ’george valentine’
UPPER(’George Valentine’) ----> ’GEORGE VALENTINE’
SQL Scalar Date/Time Functions
The SQL Scalar Date Time Functions operate on date/time values and return of date/time
values. PointBase supports the following Date/Time Functions.
CURRENT_DATE
The CURRENT_DATE Function returns the current system date from the machine that is
hosting the PointBase database as a DATE data type. You may use the CURRENT_DATE
Function anywhere you specify a DATE value.

PointBase
Version 4.8 PointBase Developer 71
Example
UPDATE order_tbl SET shipping_date = CURRENT_DATE
If the current date is April 4, 1998, the CURRENT_DATE Function returns: 1998-04-04.
CURRENT_TIME
The CURRENT_TIME Function returns the current system time from the machine that is
hosting the PointBase database as a TIME data type. You may use the CURRENT_TIME
Function anywhere you specify a time value.
Example
if the current time is exactly 9:00 AM, the CURRENT_TIME Function returns: 09:00:00.
CURRENT_TIMESTAMP
The CURRENT_TIMESTAMP Function returns the current system date and time from the
machine that is hosting the PointBase database as a TIMESTAMP data type. You may use the
CURRENT_TIMESTAMP Function anywhere you specify a timestamp value.
Example
UPDATE order_tbl SET delivery_datetime = CURRENT_DATE
If the current date and time is 9:00 AM on April 4, 1998, the CURRENT_TIMESTAMP
Function returns: 1998-04-04 09:00:00.
EXTRACT
The EXTRACT Function returns a portion of a DATE, TIME, or TIMESTAMP value. It
extracts the year, month, or day from a DATE value; an hour, minute, or second from a TIME
value; or any of these intervals from a TIMESTAMP value. The EXTRACT Function always
returns a numeric data type. The following syntax is for the EXTRACT Function.
EXTRACT (extract_field FROM datetime_value)
Use one of the keywords YEAR, MONTH, DAY, HOUR, MINUTE, or SECOND in place of
the extract_field. Format the datetime_value inside the single quotes appropriately, according
to the value the extract_field seeks.

PointBase
Version 4.8 PointBase Developer 72
Examples
EXTRACT(YEAR FROM DATE ’1998-04-01’) ----> 1998
EXTRACT(MONTH FROM DATE ’1998-04-01’) ----> 4
EXTRACT(DAY FROM TIMESTAMP ’1998-04-01 09:00:00’) ----> 1
EXTRACT(HOUR FROM TIMESTAMP ’1998-04-01 09:00:00’) ----> 9
EXTRACT(MINUTE FROM TIME ’09:00:00’) ----> 0
EXTRACT(SECOND FROM TIME ’09:00:00’) ----> 0
SQL Scalar CAST Function
The SQL Scalar CAST Function explicitly converts a value from one PointBase data type to
another. To perform an explicit data conversion, use the following syntax for the SQL Scalar
CAST Function.
CAST (value AS datatype)
Table 1 lists the data types that can be CAST into other data types. If there is a Y in the
intersection of two data types, the CAST Function can perform an explicit conversion from the
data type in the vertical axis to the data type on the horizontal axis.
Table 1: Converting Data Types With the CAST Function
C VC B I SI DEC N R F DB D T TS BB CB
CHARACTER (C) Y Y Y Y Y Y Y Y Y Y Y Y Y N Y
VARCHAR (VC) Y Y Y Y Y Y Y Y Y Y Y Y Y N Y
BOOLEAN (B) Y Y Y N N N N N N N N N N N N
INTEGER (I) Y Y N Y Y Y Y Y Y Y N N N N N
SMALLINT (SI) Y Y N Y Y Y Y Y Y Y N N N N N
DECIMAL (DEC) Y Y N Y Y Y Y Y Y Y N N N N N
NUMERIC (N) Y Y N Y Y Y Y Y Y Y N N N N N
REAL (R) Y Y N Y Y Y Y Y Y Y N N N N N
FLOAT (F) Y Y N Y Y Y Y Y Y Y N N N N N
DOUBLE (DB) Y Y N Y Y Y Y Y Y Y N N N N N
DATE (D) Y Y N N N N N N N N Y N Y N N
TIME (T) Y Y N N N N N N N N N Y Y N N
TIMESTAMP (TS) Y Y N N N N N N N N Y Y Y N N
BLOB (BB) NN NN N N NNNN NNN Y N
CLOB (CB) YY NN N N NNNN NNN N Y

PointBase
Version 4.8 PointBase Developer 73
NOTE: A VARCHAR(10) cast to CHAR(5) will be truncated at the 5th character. The system
will display a warning if the truncated characters are nonwhite spaces.
The CAST function throws an exception if the data is not convertible, for example:
CAST(’a’ AS INT) --------> Exception
SQL Scalar Routine Invocation
Using SQL Scalar Routine Invocation, you can call a pre-defined SQL Routine that returns a
scalar value. The Routine Invocation can be used anywhere you use a scalar expression. The
following syntax is for the Routine Invocation Function. For more information about creating
SQL routines (functions and procedures) refer to “Appendix A: SQL Reference.”
routine_name( [ SQL_argument_list ] )
Routine_name is the name of the routine (SQL Function or Procedure). SQL_argument_list
consists of expressions separated by commas. Each expression will result in a SQL data type
dependent on the routine called.
NOTE: If you use a Routine Invocation Function as a scalar expression, it must only return a
single value, otherwise an error is raised.
Routine Determination
Routine determination is the process that determines the routine to invoke, based on the routine
name, SQL argument list, and the current path of schemas. The routine name and SQL
arguments make up the signature of the routine. It is possible that more than one routine could
have the same signature. If more than one possible routine has the same signature, then
PointBase uses a precedence list to match each argument of each routine, to determine which
one is the best match.
Examples
DateConvert(’01-02-1993’)
SQL Aggregate Functions
SQL Aggregate Functions operate on complete sets of data and return a single result.
PointBase supports five Aggregate Functions: AVG, COUNT, MAX, MIN, and SUM.

PointBase
Version 4.8 PointBase Developer 74
AV G
The AVG Function returns the average value for the column when applied to a column
containing numeric data. The following is the syntax for the AVG Function.
AVG (column_name)
Example
SELECT AVG(commission_rate) FROM sales_rep_tbl
COUNT
The COUNT Function returns the number of rows in a specified result set. The following
syntax is one form of the COUNT Function:
COUNT(*)
Example
SELECT COUNT(*) FROM sales_rep_tbl
The second form of the COUNT Function returns the number of rows in a result set where the
specified column has a distinct, non-NULL value. The following syntax is the second form of
the COUNT Function.
COUNT(DISTINCT column_name)
MAX
The MAX Function returns the data item with the highest value for a column when applied to a
column containing numeric data. If you apply the MAX Function to a CHARACTER value, it
returns the last value in the sorted values for that column. The following syntax is for the MAX
Function.
MAX(column_name)
Example
SELECT MAX(commission_rate) FROM sales_rep_tbl
MIN
The MIN Function returns the data item with the lowest value for a column when applied to a
column containing numeric data. If you apply the MIN Function to a CHARACTER value, it
returns the first value in the sorted values for that column. The following syntax is for the MIN
Function.
MIN(column_name)

PointBase
Version 4.8 PointBase Developer 75
Example
SELECT MIN(commission_rate) FROM sales_rep_tbl
SUM
The SUM Function returns the sum of all values in the specified column. The result of the
SUM Function has the same precision as the column on which it is operating. The following
syntax is for the SUM Function.
SUM(column_name)
Example
SELECT SUM(ytd_sales) FROM sales_rep_tbl
SQL Special Registers
PointBase Embedded supports the following list as special registers. These can be used
anywhere a scalar/value expression is allowed.
• CURRENT_USER: is the current user on the system and is an SQL varchar data type of
maximal length 128.
• CURRENT_SCHEMA: is the name of the current schema in use and is an SQL varchar
data type of maximal length 128.
• CURRENT_DATABASE: is the name of the database in use and is an SQL varchar data
type of maximal length 128.
• CURRENT_SESSION: gives the current session ID.
• CURRENT_PATH: is the list of schemas in the path of the current user. The return data
type is an SQL varchar of undetermined length. The length depends upon the number of
schema names in the path.

Version 4.8 PointBase Developer 76
Indexes and Constraints
This chapter gives a brief outline of indexes and constraints in PointBase Embedded. Indexes
and constraints are used to reinforce data integrity and increase database performance. Using
indexes and constraints, you can access information from the database quicker and guarantee
the referential integrity of information. The following sections describe indexes, keys, and
constraints.
Indexes
An index is a set of ordered references to rows of a table. It can contain data from one or more
columns of a table. An index improves the performance of data retrieval by reducing the
number of physical pages that the database must access in order to read a row in the database.
Because indexes store data in order, they also eliminate the need to create temporary storage
for the ORDER BY clause if the relevant column is included in an index. Every index has a
header, which contains the following information:
• the depth of the index
• number of leaf pages
• the selectivity factor
PointBase builds and maintains indexes without user intervention and provides current
information to the query optimizer.
NOTE: Whenever you specify a unique constraint, PointBase creates a unique index
automatically.
You can also create and drop an index using the CREATE INDEX and DROP INDEX
statements. For information on the query optimizer refer to “Optimizing Query Expressions,”
in the PointBase System Guide. For CREATE INDEX and DROP INDEX syntax refer to
“SQL Reference” of this guide.

PointBase
Version 4.8 PointBase Developer 77
Keys
In a database, a key consists of one or more columns of a table that have been granted specific
properties. When defining a table or index, you specify the key (primary or foreign). PointBase
supports the following types of keys:
Primary Key
The primary key is used as a master reference for columns defined as foreign keys in other
tables. Foreign keys can only contain values defined in the Primary key to which they refer. A
table can only have one primary key, and the key must contain only unique values without any
NULL values. The table containing the primary key is referred to as the parent table.
Foreign Key
A foreign key associates values contained in one or more columns of a table to primary keys of
other tables. The table containing the foreign key is referred to as the child table.
The child table references a parent table, which must contain a primary key. The values in a
foreign key column must match either all the values, or a subset of the values in the referenced
Primary Key. A foreign key cannot contain values that are not in the primary key to which it
refers. A column defined as a foreign key can contain NULL values.
Constraints
Constraints are rules that the database enforces to improve data integrity. You can specify all of
the following constraints at either the column level or at the table level in PointBase
Unique Constraint
A unique constraint forces a column to contain only unique values. PointBase allows NULL
values in unique columns, unless you specify NOT NULL when creating or altering a table.
When creating or altering a table, you must define unique constraints. However, you can also
create a unique constraint automatically when you create a primary key. Although a table can
contain any number of unique columns, only one can be the primary key.
NOTE: Whenever you specify a unique constraint, PointBase creates a unique index
automatically.
Referential Constraint
You can use a referential constraint to link foreign key columns with primary key columns.
You can define referential constraints as you create or alter a table.

PointBase
Version 4.8 PointBase Developer 78
Check Constraint
The body of a check constraint is a search condition. You can use a check constraint to make
sure that a value going into a column meets the criteria of the search condition. Similar to the
other constraints, you can define a check constraint when creating or altering a table. However,
you can also use this constraint when updating a column(s) of a table. The value being inserted
or modified (through an UPDATE) must cause the search condition to evaluate to TRUE, in
order for the data to be inserted or updated.
Deferrable Constraint
Normally constraint checking is performed immediately after a row is inserted, updated or
deleted. In this case, if an operation takes several statements to completely satisfy a constraint,
this operation may fail with constraint checking.
In SQL99, deferrable constraint is defined to avoid this problem. A user may define a
constraint as deferrable, so the constraint checking will not be performed until the transaction
commits. If the constraint is defined as deferrable, then it can be set to immediate or deferred in
each transaction using the set constraints statement. If it is set to immediate, constraint
checking is performed immediately after a row is modified. Otherwise, it is checked at the end
of a transaction. The scope of the set constraints statement is for the current transaction only.
See table constraint and set constraints statement for more detail.
When a constraint is effectively checked, if the constraint is not satisfied, then an integrity
violation exception condition is raised:
If this exception condition is raised as a result of executing a commit statement, then the
SQLSTATE is not set to integrity violation, but is set to transaction rollback - integrity
violation, and the transaction needs to be rolled back. In this case, Pointbase automatically
rolls back the transaction implicitly.
NOTE: Pointbase supports deferrable check and referential constraints.

Version 4.8 PointBase Developer 79
Index Organized Tables
This chapter gives a brief outline of index organized tables in PointBase Embedded.
The organization of a table refers to the order in which the rows of the table are physically
ordered on disk. In a regular (HEAP) table organization, all rows are stored in no particular
order. Each row has a system generated "row pointer" that identifies the location of the data
for that row. All indexes on the table then contain rows that consist of key values for that index,
followed by the row pointer for the row that contains those values. The row pointer is used to
fetch any non-key values that are needed from the base table.
In an index-organized table, the data for the table is stored directly in the primary key index.
The primary key index contains the primary key values, as in the primary key on a regular
table. But, instead of each row in the primary index being followed by the row pointer, each
row consists of the primary key column values followed by the non-key column values.
Alternate indexes are allowed on index organized tables. Each entry in an alternate index on a
index organized table consists of the alternate index key column values, followed by the
primary key values. The primary key values are used to fetch any non-key values from the
primary key.
Because rows are stored directly in the primary key index, index organized tables provide
faster access for queries involving equality predicates or range predicates on the primary key
columns. For range queries, access time is potentially much faster. This is because rows with
similar primary key values are stored physically close to each other on disk, i.e. the rows are
clustered on the primary key values. Because of this, fewer pages of data need to be read to
fetch all the requested rows, and access times are reduced. In most cases, rows with the same
or similar key values will be on the same page(s). If n is the number of rows that satisfy the key
predicates, then on average, a select from a key sequenced table via the key values will have to
access (n / # of rows/page) pages, instead of n pages.
If no alternate indexes exist, then an index organized table requires less storage space then the
corresponding base table + primary key for a regular table. This is because the primary key
values do not need to be duplicated, and no storage is required for the row pointer values.
However, if many alternate indexes are needed, then the storage requirements can be greater,
because the primary key values must be duplicated in each alternate index row.
Any change to the table, such as inserting, updating or deleting rows, result in changes to the
primary key index and any alternate indexes.

Version 4.8 PointBase Developer 80
Search Conditions and Predicates
This chapter describes search conditions and predicates in PointBase. Search conditions and
predicates help return specific values from the database. To use a search condition, you must
use it with an SQL statement. To use a predicate, you must use it with a search condition. You
can specify certain criteria in a search condition and predicate for an SQL statement to perform
to the database. The following sections describe search conditions and predicates and their
behaviors in PointBase.
Search Conditions
A search condition specifies a condition of “TRUE”, “FALSE”, or “UNKNOWN” about a
specific row. It is comprised of predicates associated with the logical operators: AND, OR, and
NOT. The syntax for a search condition is as follows:
[NOT] {predicate | (search_condition)}
[{AND | OR} [NOT] {predicate | (search_condition)}...]
Search conditions contained within parentheses first reads the values from left to right. The
precedence order for the logical operators are: NOT, AND, and then OR. If more than one
operator of the same precedence is used in a search condition, the optimizer will determine
which one to execute before the other. If a search condition does not comprise any logical
operators, then the result is the result of the predicate specified.
Simple search conditions
A search condition—in its simplest form—is a logical test that can be applied to each row. It
takes the format of two value expressions and an operator and tests the relationship between
the two values, for example:
value 1 > value 2
x > 2

PointBase
Version 4.8 PointBase Developer 81
Values
Any one of the values in a search condition may be one of the following:
• a constant
• the value in a column name that is used in the place of one of the value expressions
• a value derived from either one of these two values, using standard operators and non-
aggregate functions, such as BALANCE + 10.
Operators
PointBase SQL supports all standard relational operators:
•equals (=)
• greater than (>)
• less than (<)
• not equal to (<>)
• less than or equal to (<=)
• greater than or equal to (>=)
Notice in a combined relation, for example, less than or equal to or greater than or equal to, the
equal sign must be the last sign in the relation.
Complex search conditions
A complex search condition can contain multiple boolean expressions, linked by the keywords
AND or OR. A boolean expression uses all the same syntax and operators as a boolean
condition.
The AND keyword returns TRUE if the search conditions on both sides of the AND keyword
return TRUE. If either one of the conditions return FALSE, the joined condition returns
FALSE.
The OR keyword returns TRUE if the expressions on either side of the OR keyword return
TRUE. If both conditions return FALSE, the joined condition returns FALSE.
The search conditions that make up a complex search condition return according to four rules
of precedence:
1. Conditions within parentheses
2. Conditions joined by an AND keyword
3. Conditions joined by an OR keyword
4. Conditions prefixed by a NOT keyword

PointBase
Version 4.8 PointBase Developer 82
Order of Evaluation
Any set of expressions within parentheses return first. If there are more than one set of
conditions within parentheses in a boolean expression, the sets evaluate from right to left. If
sets of conditions within parentheses contain other sets of conditions within parentheses, the
innermost sets evaluate first. Although it is not required that complex search conditions, which
contain multiple sets of search conditions, use parentheses to separate the conditions, it is
highly recommended to improve the readability of the conditions.
The AND, OR, and NOT keywords are reflexive, which means that the ordering of the
expressions in a boolean expression does not matter. Regardless of the order, you receive the
same result. A code optimizing program may execute the AND, OR, and NOT keywords
differently than they appear in a boolean expression, but the boolean expression returns the
same result.
Examples
In the first example below, the statement executes from left to right, because AND has a higher
precedence than OR. In the second example, the search condition in parenthesis executes first.
1. emp_id > 201 AND d_name = ‘engineering’ OR d_name = ‘research’
2. emp_id > 201 AND (d_name = ‘engineering’ OR d_name = ‘research’)
Predicates
A predicate is an SQL expression that evaluates a search condition that is either TRUE,
FALSE or UNKNOWN. TRUE means the expression is correct. FALSE means the expression
is incorrect. UNKNOWN means the expression is neither TRUE nor FALSE. All SQL values
used in a predicate must be of a compatible data type (family) for comparison.
PointBase supports the following types of predicates:
• comparison (=, <>, <, >, <=, >=, !=)
• BETWEEN
•LIKE
• EXITS | NOT EXISTS
• IN | NOT IN
• NULL
NOTE: PointBase does not support multi-valued predicates.

PointBase
Version 4.8 PointBase Developer 83
COMPARISON
The COMPARISON predicates compare two values. If either value is NULL, then the result of
the predicate is UNKNOWN.
NOTE: When comparing two string values, PointBase ignores any spaces that trail after the
string. PointBase ignores trailing spaces in queries and in the table. This behavior
supports the ANSI standard; however, it may vary with other database vendors.
Examples
The following are examples of using the comparison predicates. The results (TRUE, FALSE,
or UNKNOWN) of the predicates are based on the values of the column.
• emp_id = 200 ---> TRUE if emp_id is 200
• emp_manager <> ‘Jones’ ----> TRUE if the manager is not
JONES
• salary > 50000 ----> TRUE if salary is greater than $50,000
BETWEEN
The BETWEEN predicate determines if a value is between a range of values. The BETWEEN
predicate is a short hand notation. It is equivalent to saying the value is greater than or equal to
the beginning range and less than or equal to the ending range. For example, value1
BETWEEN value2 AND value3 is equivalent to the following search_condition:
value1 >= value2 AND value1 <= value3
Table 1: Comparison Predicate Symbols
Comparison Symbol
Symbol
Description
Result
Description
= equal to This symbol results to TRUE if both
values are the same.
<> or != not equal to This symbol results to TRUE if the first
value is equal to the second value.
< less than This symbol results to TRUE if the first
value is less than the second value.
> greater than This symbol results to TRUE if the first
value is greater than the second value.
<= less than or equal to This symbol results to TRUE if the first
value is less than or equal to the second
value.
>= greater than or equal to This symbol results to TRUE if the first
value is greater than or equal to the
second value.

PointBase
Version 4.8 PointBase Developer 84
The following is the syntax for a between predicate:
expression [NOT] BETWEEN literal AND literal
Examples
In the first example below, the system returns TRUE if the emp_deptid is between 200 and
1000. In the second example, the system returns TRUE if emp_managerid is less than 100 or
greater than 400.
1. emp_deptid BETWEEN 200 AND 1000
2. emp_managerid NOT BETWEEN 100 AND 400
LIKE
The LIKE predicate searches a string to determine if the string has a particular pattern. The
pattern is a string with a combination of the following special characters: underscore character,
_ and percent sign, %. If the value of any of the arguments is NULL, then the result is
UNKNOWN. The following is the syntax for the LIKE predicate:
match_expression [NOT] LIKE pattern [ESCAPE escape]
match_expression
The match_expression is a string that will be searched to determine if the pattern specified can
be found. Escape, if specified, represents a character string that evaluates to a single character,
and allows the special interpretation given to the characters "_" and "%" to be disabled by
preceding them with the defined escape character.
NOTE: The LIKE predicate is case-sensitive.
Examples
In the following example, the LIKE predicate looks for any row where the column contains a
pattern of “engineer” as eight characters contained within the column. The percent sign
represents any string of zero or more characters.
1. emp_description LIKE ‘%engineer%’
In the next example, the LIKE predicate looks for all rows that do not contain only a pattern of
some character followed by ‘bc’ value for a column. The underscore character represents a
single character. All other characters in both examples represent themselves.
2. dept_description NOT LIKE ‘_bc’
In the last example, the LIKE predicate looks for all rows where the department name begins
with the underscore character "_", followed by the letter “e” plus zero or more characters. This
disables the special interpretation given to the underscore character "_", allowing it to be used
as part of the character pattern to be matched.
3. 3. dept_description LIKE '=_e%' ESCAPE '='
PointBase also supports parameterized escape values for LIKE in prepared statements.

PointBase
Version 4.8 PointBase Developer 85
EXISTS | NOT EXISTS
These quantified operators verifies the existence of rows. The boolean result of an EXISTS or
NOT EXISTS predicate is determined by the number of rows returned by the subquery. For
EXISTS, the boolean result is TRUE if the subquery returns at least one row and FALSE if the
subquery does not return any rows. For NOT EXISTS, the boolean result is TRUE if the
subquery does not return any rows and FALSE if the subquery returns at least one row.
Notes
• PointBase supports any level of nested subqueries.
• PointBase allows a subquery to return multiple values only using EXITS, NOT EXISTS,
IN, or NOT IN.
• Currently, PointBase does not support any form of the quantified operators, ANY or
ALL, for example: =ANY, <=ANY, >=ALL, <>ALL,... etc.
Example
This example retrieves all cities, in which at least one sales representative works.
SELECT a.city
FROM office_tbl a
WHERE EXISTS
( SELECT *
FROM sales_rep_tbl b
WHERE a.office_num = b.office_num);
Results:
CITY
Miami
Atlanta
San Mateo
San Francisco
San Diego
Oakland
Detroit
New York

PointBase
Version 4.8 PointBase Developer 86
IN | NOT IN
You can use these predicate keywords to return a value list or a subquery.
Value List
The IN predicate determines if a value is TRUE for a list of values. The following is the syntax
for an IN predicate. The NOT IN predicate also follows the same format as the IN predicate.
SELECT|UPDATE|DELETE FROM table
WHERE expression [NOT] IN (list_of_values)
The list_of_values can be represented only by literals with the IN predicate. The NOT IN
predicate returns a TRUE value only when it does not find the list_of_values specified.
Example
In the following example, the IN predicate returns TRUE if the “emp_deptid” is any of the
values 10, 100, or 1000.
emp_deptid IN (10,100,1000)
Subquery
IN or NOT IN can compare a single value of each row of a table to a value from potentially
multiple result rows from a subquery. IN returns TRUE, if at least one of the resultant subquery
row values is equal to the expression; it returns FALSE otherwise. NOT IN returns TRUE if all
of the resultant subquery row values are not equal to the expression.
Example
This example retrieves the names of all sales reps working in the western region.
SELECT a.first_name, a.last_name
FROM sales_rep_tbl a
WHERE a.office_num IN
( SELECT b.office_num
FROM office_tbl b
WHERE b.region = ’Western’);
Results:
FIRST_NAME LAST_NAME
Heather Smith
George Valentine
Raymond Brown
Jack Smith

PointBase
Version 4.8 PointBase Developer 87
NULL
The NULL predicate determines if a column in a selected row contains the SQL value: NULL.
If the column value is NULL, then PointBase returns TRUE. The following is the syntax for
the NULL predicate:
column_name IS [NOT] NULL
Examples
In the first example, the NULL predicate looks for any row where the column contains a
NULL value. In the second example, the NULL predicate looks for all rows that do not contain
a NULL value for a column.
1. emp_dept IS NULL
2. emp_manager IS NOT NULL

Version 4.8 PointBase Developer 88
Transactions and Locks
This chapter describes the behavior and usage of transactions and locks in PointBase. By
understanding how transactions and locks work in PointBase, you can maximize concurrent
database utilization while maintaining appropriate data integrity for your application. The
following sections describe transactions, locking concepts, and the different isolation levels
that PointBase supports.
Transactions
A transaction is the primary mechanism used by PointBase to protect the integrity of data that
can be accessed from the database. All of the changes (INSERT, UPDATE, DELETE) made to
a database during a transaction are added to the database when the transaction commits.
A transaction implicitly starts if any Data Manipulation Language (DML) statement is
executed, such as SELECT, INSERT, UPDATE, and DELETE, or if any Data Definition
Language (DDL) statement is executed, such as CREATE TABLE, CREATE INDEX, etc. A
transaction can be explicitly started by executing a START TRANSACTION ISOLATION
LEVEL statement.
A transaction commits, when you issue a COMMIT statement. An application can also cancel
all the changes made within a transaction by rolling back the transaction. A transaction rolls
back when you issue a ROLLBACK statement or when an exception occurs.
If you set AUTOCOMMIT to on, a transaction will automatically commit after each statement
(INSERT, UPDATE, DELETE) is completed. For example, a statement is completed when all
result sets and/or update counts have been retrieved. To bound transactions explicitly,
AUTOCOMMIT must be set to off.
A transaction is associated with a connection to the database. If multiple statements or threads
use the same connection, they are part of the same transaction. If you decide to allow multiple
threads to share one connection, you must synchronize all threads in order to commit the
transaction.
For example, if one thread in a transaction issues commit, all the threads within the same
transaction will be committed, invalidating threads that have not finished executing. PointBase
recommends that you use one connection per thread.

PointBase
Version 4.8 PointBase Developer 89
Row Level Locking
When multiple connections or threads access the database concurrently, PointBase ensures the
integrity of the data using row level locking. PointBase locks only the rows affected by an SQL
statement rather than pages or tables, to ensure maximum concurrent activity. For example,
when transaction T1 is updating row 10 in page 100, transaction T2 is able to update row 20 in
the same page (100) or to read other rows in page 100.
Locks and Memory
PointBase stores all locks in memory. For efficient use of memory, you can limit the number of
locks a single transaction can hold. The default limit is 2000, but you can change this using the
locks.maxCount property in the pointbase.ini file. (Refer to the PointBase System Guide
for more information about the pointbase.ini file, which you can use to configure the system
properties.)
When a transaction reaches the specified limit of locks, PointBase automatically converts all of
the row-level locks, to a table-level lock, reducing concurrency as a consequence. If the system
cannot convert the row level locks to the table level lock within a reasonable time, the
transaction is aborted. This may happen, if other transactions hold row-level locks on the same
table.
Transaction Isolation Levels
The following section describes the transaction-isolation levels that PointBase supports. The
transaction-isolation level defines the rules for releasing locks, allowing other users access to
the row or table. By understanding PointBase isolation levels, you can understand how the
system locking mechanism behaves.
NOTE: For all isolation levels, PointBase holds locks on rows that are modified until the end
of the transaction.
READ_COMMITTED
When the transaction-isolation level is set to READ_COMMITTED, PointBase releases the
lock on a row as soon it returns the row data to the user. For example, if a query returns 100
rows, the system locks the first row, reads the data and returns it to the user. Before locking and
reading from the second row, PointBase releases the lock on the first row to minimize resource
usage and maximize concurrency. After all the reads are complete, no locks are held.

PointBase
Version 4.8 PointBase Developer 90
SERIALIZABLE and REPEATABLE_READ
When the isolation level is set to SERIALIZABLE or REPEATABLE_READ, PointBase does
not release locks on rows read until the end of the transaction. For example, if a query returns
100 rows, the system applies the lock on each row as it reads them. The system releases the
locks only when it returns the data from all 100 rows to the user and the transaction is
complete.
Recommended Isolation Level
The READ_COMMITTED isolation level gives maximum concurrency and minimum
resource usage while providing the required data integrity for most applications. The default
isolation level is READ_COMMITTED.

Version 4.8 PointBase Developer 91
Distributed Transactions
This chapter summarizes distributed transaction processing (DTP) environments and how to
use PointBase Embedded in a DTP environment. Following the section, “PointBase’s Role in a
DTP Environment,” this chapter briefly describes Sun’s Java Transaction API (JTA), the Java
mapping for X/Open’s XA Specification, and also the JDBC API Extensions for distributed
transactions. Finally, this chapter describes how to use PointBase Embedded in a DTP
environment by providing code snippets, explaining important restrictions, and supplying
specific java classes that PointBase Embedded implements for distributed transactions.
Although this chapter summarizes DTP concepts, it is only a summary, and it pertains
specifically to PointBase Embedded. For more information about the topics discussed in this
chapter, PointBase recommends reading the following books or documents:
• X/Open’s Distributed Transaction Processing: The XA Specification
• Sun Microsystem’s JDBC API 2.0
• Sun Microsystem’s Java Transaction API (JTA) 1.0.1
Important Note
To successfully run your XA application with PointBase, you must obtain the following two
JAR files from the Sun Microsystem’s website, “jta.jar” and “jdbc2_0-stdext.jar” and, include
them in your classpath with the PointBase JAR’s.
• Download the “jta.jar “at http://java.sun.com/products/jta/index.html
• Download the “jdbc2_0-stdext.jar” at http://java.sun.com/products/jdbc/
download.html#corespec21.
PointBase’s Role in a DTP Environment
According to the X/Open’s Distributed Transaction Processing (DTP) Model, a DTP
environment specifies that application programs can use Resource Managers and a
Transaction Manager to access multiple data sources through one global transaction.
PointBase acts as a resource manager (RM) in a DTP environment.

PointBase
Version 4.8 PointBase Developer 92
You can use PointBase in a DTP environment to write Enterprise JavaBeans that are
transactional across multiple PointBase servers. Workgroup environments, such as J2EE and
J2SE where the data extends across multiple databases can benefit using PointBase, because
the PointBase JDBC driver supports the 2-phase commit protocol used by the Java
Transactional API (JTA).
Transaction Managers, Resource Managers, and Global Transactions
A transaction manager (TM) manages global transactions by ultimately deciding to commit, to
rollback, or to recover global transactions. A global transaction is known as a unit of work. For
example, an application can group multiple updates to several different data sources into one
unit of work—a global transaction. A TM also associates resource managers with global
transactions.
Each resource manager (RM) involved in a global transaction is unaware of any other RMs
involved besides itself. For this reason, each RM requests and receives “permission” from the
TM before it performs any work requested by an application. The RM also communicates all
work it completes for a global transaction to the TM—whether it successfully completes or
fails. With this information, the TM decides how to handle the global transaction.
NOTE: If any RM fails to successfully complete its part of a global transaction, all RMs
involved in that global transaction must rollback the work for that particular global
transaction.
Interaction Among DTP Components
The following illustration shows PointBase interacting with the application program and the
transaction manager. Notice that the application program also interacts with the transaction
manager. In this interaction, the application program defines the transaction boundaries or
rules with the transaction manager. This guide, however, does not discuss this interaction. For
more information about this topic, please refer to the relevant application program
documentation. The following list describes the interaction flow among the application
program (AP), the resource manager (RM), and the transaction manager (TM).
A simple diagram displaying the interaction
among DTP components.
Application Program (AP)
Transaction Manager (TM)
Resource Manager (RM)
PointBase
Embedded

PointBase
Version 4.8 PointBase Developer 93
Java Transaction API (JTA)
The Java Transaction API (JTA) is part of the Sun J2EE standard which deals with distributed
transactions. JTA defines a high-level transaction management interface intended for resource
managers and transactional applications in DTP environments. PointBase implements the
XAResource and Xid Interface of JTA, which maps the industry standard, X/Open XA
Interface, to Java. The interface, X/Open XA Interface allows a transaction manager to manage
operations performed by multiple resource managers, using the two-phase commit X/Open XA
protocol.
JDBC 2.0 Optional Package API
Sun Microsystems created the JDBC API 2.0 Extensions, java.sql.XAConnection and
javax.sql.XADataSource, so that JDBC drivers can support distributed transactions
using the Java Transaction API’s XAResource Interface. Refer to the JDBC 2.0 Standard
Extension Specification for more details on JDBC API 2.0 Extensions (http://java.sun.com/
products/ jdbc).
The PointBase JDBC driver supports distributed transactions by implementing the following
interfaces. For unsupported methods, you can view both, “Appendix B: Unsupported JDBC
2.0 Methods in PointBase” and the section, “Unsupported in PointBase” at the end of this
chapter.
API Description
javax.transaction.xa.XAResource This interface maps the industry standard X/Open XA
Interface to Java. It defines APIs between the transaction
manager and the resource manager. PointBase implements
the JDBC standard for this interface. For more information
about this interface, refer to http://java.sun.com/products/
jta/javadocs-1.0.1/javax/transaction/xa/XAResource.html.
javax.transaction.xa.Xid This interface defines the global transaction identification
structure of the X/Open XA Interface. PointBase
implements the JDBC standard for this interface. For more
information about this interface, refer to http://
java.sun.com/products/jta/javadocs-1.0.1/javax/
transaction/xa/Xid.html.

PointBase
Version 4.8 PointBase Developer 94
Implementing javax.sql.XADataSource
The class, com.pointbase.xa.xaDataSource is the PointBase implementation of the
JDBC Extension Interface, javax.sql.XADataSource. It is normally used with the Java
Naming and Directory Interface (JNDI) for defining data sources in a DTP environment.
Because database vendors may support different data source properties, this section describes
what PointBase supports. And, in addition to the standard JDBC Extension methods of
javax.sql.XADataSource, PointBase has created its own methods, which this section
also describes.
XADataSource and JNDI
Using com.pointbase.xa.xaDataSource to initialize an XADataSource object, is the
first step to distributed transactions with PointBase. To initialize an XADataSource object, for
example, you provide the database URL information, password, user name, etc., to get a
connection with a database. However, you can also use JNDI.
Using JNDI, an application can find and access remote services, such as a database service
across a network. After registering an XADataSource object with a JNDI naming service, an
application can access that object to connect to the data source it represents.
javax.sql.XADataSource This is the JDBC Extension DataSource Interface for
JTA’s XAResource Interface. PointBase implements the
class, com.pointbase.xa.xaDataSource for this
interface. In addition to the JDBC standard methods,
PointBase implements some of its own methods.
For more information about PointBase’s implementation
of this interface, see the section, "Implementing
javax.sql.XADataSource" on page 94.
For more information about the standard JDBC interface,
javax.sql.XADataSource, refer to http://
java.sun.com/products/jdbc/jdbc20.stdext.javadoc/.
javax.sql.XAConnection This interface is the JDBC Extension Connection Interface
for JTA’s XAResource Interface. PointBase uses the JDBC
standard for this interface. For more information about this
interface, refer to http://java.sun.com/products/jdbc/
jdbc20.stdext.javadoc/.
API Description

PointBase
Version 4.8 PointBase Developer 95
With PointBase, you can use a JNDI naming service to manage data sources and connections.
JNDI adds portability to the application code, for example, you do not have to include data
source properties in the application code, such as the database name or the password. Also, you
do not have to change the application code if you want to change a data source property. For
example, instead of changing the application code to reflect a new user name, you can change
the user name with the JNDI naming service.
Support for XADataSource Properties
Database vendors may vary when it comes to supporting XADataSource properties. For every
supported XADataSource property, the database vendor must provide set and get methods.
PointBase supports the following XADataSource methods for their respective XADataSource
properties:
XADataSource Method Description
setDatabaseName( String url ) Sets the databaseName property, defining the name of a
particular database on a server. In PointBase, this defines the
URL.
String getDatabaseName() Returns the URL of a particular database on a server
setDescription( String description ) Sets the description property, defining a description of this data
source
String getDescription() Returns a description of this data source
setPassword( String password ) Sets the password property, defining the user’s database
password
String getPassword() Returns the user’s database password
setUser( String user ) Sets the user property, defining the user name
String getUser() Returns the user name

PointBase
Version 4.8 PointBase Developer 96
Additional PointBase Methods
In addition to the standard methods of the javax.sql.XADataSource interface and
javax.sql.DataSource
for that matter, PointBase provides the following methods.
Using PointBase in a DTP Environment
This section describes how to use PointBase in a DTP environment. PointBase acts as the
resource manager (RM) in a DTP environment, which reads or writes the data requested by an
application in a global transaction. The following sections describe step-by-step how to use
PointBase in a DTP environment.
Getting the XAResource Object
First, the transaction manager (TM) must get an XAResource object to start and end the
association between an XAConnection object and a global transaction. To get an XAResource
object, you must do the following:
Initialize XADataSource
Create a DataSource object to produce an XAConnection object. An XAConnection object is
similar to a typical Connection object; however, an XAConnection object can obtain an
XAResource object, which you need to perform a global transaction.
xaDataSource xads = new com.pointbase.xa.xaDataSource();
xads.setDatabaseName( url );
NOTE: Initializing a JNDI XADataSource compared to a JDBC XADataSource is similar.
The following example initializes a JNDI XADataSource—assuming the
XADataSource object has been stored with a JNDI naming service previously.
xaDataSource xads = (xaDataSource)ctx.lookup(“pointbase/datasource1”);
Get XAConnection Object
Get an XAConnection to “datasource1,” using the getXAConnection method. You need an
XAConnection object to obtain an XAResource object.
XAConnection conxa = xads.getXAConnection();
XADataSource Method Description
setCreateDatabase( boolean p_Create ) Sets TRUE or FALSE. If set to TRUE, it creates a new database.
Default is FALSE.
Boolean getCreateDatabase() Returns TRUE if database exists and FALSE if it does not exist.

PointBase
Version 4.8 PointBase Developer 97
Get Connection Object
Get a connection to the data source that “datsource1” represents, using the getConnection
method. The application involved with the global transaction uses this connection to perform
necessary work with the data source.
Connection con = conxa.getConnection();
Get XAResource Object
Get an XAResource object from the XAConnection object, using the getXAResource method.
The TM uses the XAResource object to manage a global transaction and its association with an
XAConnection object.
xaResource xrs = conxa.getXAResource();
NOTE: Only one XAResource object may exist for each XAConnection object. For example,
if you call a second getXAResource method on the same XAConnection object, you
obtain the same XAResource object.
Using the XAResource Object
Obtaining an XAResource object prepares you for starting and ending the association between
a global transaction and an XAConnection object. The following examples describe the syntax
that starts and ends the association between an XAConnection and a global transaction; “xrs”
is the XAResource object:
•Start
xrs.start( Xid, Flag );
•End
xrs.end( Xid, Flag );
Xid
The TM assigns Xids to identify a global transaction. Xid consists of two parts, GTRID
(transaction ID) and BQUAL (branch ID); both can be a maximum of 64 bytes. PointBase uses
a constructor that requires the following parameters:
The following example describes the syntax that a TM can use to define an Xid using the
PointBase class, com.pointbase.xa.xaXid:
Xid xid1 = new com.pointbase.xa.xaXid ( formatId, trId , brId );
Parameter Name Parameter Type
formatId int
trId byte[ ]
brId byte[ ]

PointBase
Version 4.8 PointBase Developer 98
Flags
The following “Flags” help start and end the association between a global transaction and an
XAConnection object.
• TMNOFLAGS: indicates the start of a new global transaction. If you try to start a global
transaction with an Xid that is currently in use, you receive the error, XAER_DUPID.
xrs.start( xid1, TMNOFLAGS );
• TMJOIN: indicates the joining of another existing global transaction branch. If you try to
start a global transaction with an Xid that is currently in use, you receive the error,
XAER_PROTO.
xrs.start( xid1, TMJOIN );
• TMRESUME: indicates resuming a suspended global transaction, which must have been
previously suspended using the TMSUSPEND flag. You can use the TMRESUME flag
in a different thread than the thread that suspended the global transaction, but it must use
the same XAConnection.
xrs.start( xid1, TMRESUME );
• TMSUCCESS: indicates that a global transaction has completed successfully.
xrs.end( xid1, TMSUCCESS );
• TMFAIL: indicates that a global transaction failed. You must rollback this global
transaction.
xrs.end( xid1, TMFAIL );
• TMSUSPEND: indicates suspending a global transaction. You must continue this global
transaction with the flag, TMRESUME, within the same XAConnection.
xrs.end( xid1, TMSUSPEND );
Committing Global Transactions
Starting and ending a global transaction is similar to committing one, because you must
commit a global transaction, using the XAResource object. After calling the
XAResource.end(Xid, TMSUCCESS) method, you may commit the global transaction.
The beginning of this chapter mentioned that TMs ultimately decide to commit a global
transaction. TMs have the choice to use a “Two Phase Commit” or a “One Phase Commit”
protocol. PointBase (the RM) supports both protocols.
One Phase Commit
A TM can use the one phase commit protocol, if it knows that only one RM in the DTP
environment made changes to the shared data sources.
The following example describes the syntax for committing a global transaction using the one
phase commit protocol; “xrs” is the XAResource object:
xrs.commit( xid1, true);

PointBase
Version 4.8 PointBase Developer 99
Two Phase Commit
A TM uses the two phase commit protocol, if multiple RMs made changes to shared data
sources. In the first phase, (absent in the one phase commit protocol), the TM must confirm
that all RMs involved in the global transaction have completed the necessary work
successfully. If one RM does not complete its work successfully, the TM must rollback the
global transaction. If the TM received a successful response from all RMs, however, the TM
proceeds to phase two, committing the global transaction.
The following example describes the syntax for committing a global transaction using the two
phase commit protocol; “xrs” is the XAResource object:
•Phase One
xrs.prepare( xid1 );
•Phase Two
xrs.commit( xid1, false);
Rolling Back Global Transactions
The TM must rollback a global transaction if any RM does not complete its work successfully
or if the application requests that the TM rollback the global transaction. The following
example describes the syntax for rolling back a global transaction; “xrs” is the XAResource
object:
xrs.rollback( xid1 );
Recovering Global Transactions
A DTP environment or system may need to recover after a storage, connection path, or
program failure. PointBase (the RM) provides the TM a list of Xids that it has prepared for
commitment by the two phase commit protocol. The TM must recover the Xids by either
committing them or rolling them back. The following example describes the syntax for
recovering a global transaction; “xrs” is the XAResource object:
Xid[] xids = xrs.recover( Flags );
Flags
• TMSTARTSCAN: indicates the start of a new recovery process.
Xid[] xids = xrs.recover( TMSTARTSCAN );
• TMENDSCAN: indicates the end of a recovery process.
Xid[] xids = xrs.recover( TMENDSCAN );
• TMNOFLAGS: indicates that no other flags are specified. Use this flag only after you
started the recovery scan.
Xid[] xids = xrs.recover( TMNOFLAGS );
• TMSTARTSCAN | TMENDSCAN: indicates the retrieval of all pending Xids.
Xid[] xids = xrs.recover( TMSTARTSCAN|TMENDSCAN );

PointBase
Version 4.8 PointBase Developer 100
Example
The following example describes a global transaction using a single thread and a single
resource manager.
// initialize DataSource
com.pointbase.xa.xaDatasource xads = new com.pointbase.xa.xaDataSource()
xads.setDatabaseName( “jdbc:pointbase:embedded:xyz” );
xads.setCreateDatabase( true );
// get a connection object from DataSource
XAConnection conxa = xads.getXAConnection ( );
Connection con = conxa.getConnection();
// get a resource object from Connection
XAResource xrs = conxa.getXAResource ( );
// define an Xid
Xid xid = new com.pointbase.xa.xaXid ( “tr001” , “br001”);
// start a new transaction
xrs.start ( xid, XAResource.TMNOFLAG );
// do something
Statement stmt = con.createStatement ( );
stmt.execute ( “ create table xxx ( c1 int )“ );
stmt.execute ( “ insert into xxx values ( 1 ) “ );
…
// end an Xid
xrs.end ( xid, XAResource.TMSUCCESS );
// commit the transaction
xrs.prepare ( xid );
xrs.commit ( xid, false );
//close the connection
con.close();
conxa.close();
Mixing Global and Local Transactions
Using PointBase, you can mix global and local transactions in the same XAConnection. If you
execute an SQL statement and have not started a global transaction, (for example, getting an
XAResource object) PointBase starts a local transaction automatically.
If you execute a local transaction, you must commit or rollback the transaction before you can
start a global transaction.
NOTE: If autocommit is ON, local transactions commit automatically.

PointBase
Version 4.8 PointBase Developer 101
Unsupported in PointBase
PointBase does not support the following for distributed transactions:
• setTransactionTimeout: this method sets the transaction time-out value for this
XAResource instance.
• getTransactionTimeout: this method gets the transaction time-out value set for this
XAResource instance.

Version 4.8 PointBase Developer 102
SQL Security and Privileges
This chapter describes PointBase security and privileges. Schemas are an integral part of
security in PointBase. When creating a PointBase user, they do not have any access privileges
to schemas or other data objects within the database. PointBase only permits the schema or
database owner, PBSYSADMIN, or the PBDBA role to grant privileges to the schema and
data objects within the schema. These users can grant privileges to the following data objects
in the schema:
•Tables
• Columns
•Roles
• SQL Procedures and Functions
Table 1 describes the privileges that the previously mentioned users can grant to other users for
tables and columns:
Table 1: User Privileges for Tables and Columns
Privilege Statements
Privilege
Description
DELETE Allows a user to delete rows from tables within the schema
INSERT Allows a user to insert rows of data into tables within the
schema
REFERENCES Allows a user to set up references to primary keys within
the schema
SELECT Allows a user to select rows from tables within the schema
TRIGGER Allows a user to create triggers on tables within the schema
UPDATE Allows a user to update rows in tables within the schema
EXECUTE Allows users to execute functions or stored procedures
within the schema

PointBase
Version 4.8 PointBase Developer 103
Predefined Users
PointBase provides you with two predefined users. They each have their own purposes for the
database. For example, anyone connected to the database using the predefined user,
PBPUBLIC, has the capability to perform the following:
• connect to the database
• access the PBPUBLIC schema
• alter any objects within the default schema
In addition, PointBase provides one more type of predefined user. It has complete authority
and privileges over all databases in the system. However, it does not have the privilege to
modify or drop the system catalog tables.
Internal_System_Administrator (ISA)
This type of predefined user is for PointBase internal use only.
PBSYSADMIN
This type of predefined user has complete authority and privileges over all objects in the
database, for example, it can create new users in the database. However, it does not have the
privilege to modify or drop the system catalog tables. You may not grant additional
privileges to the predefined user, PBSYSADMIN. To connect using PBSYSADMIN, you will
initially have to use the password, “PBSYSADMIN.” After using it to connect, PointBase
encourages you to change the password immediately.
PBPUBLIC
Another PointBase predefined user is PBPUBLIC. To connect using this type of user, you must
use the default password, PBPUBLIC. With this type of user, you may access objects in the
default schema, PBPUBLIC.
Previous User PUBLIC
In versions 4.1 and earlier, PointBase used the default user, PUBLIC. By default, it also has the
password and schema, PUBLIC. These names will still remain effective in versions 4.3 and
later; however, PointBase will now use PUBLIC for superficial purposes only. That is, you
may still connect to the database using PUBLIC. But internally, PointBase converts the user
and the password, PUBLIC, to PBPUBLIC every time you connect, and PointBase recognizes
the schema, PUBLIC as if it were the schema, PBPUBLIC. Please note that the passwords,
PBPUBLIC and PUBLIC act as the same password, so if you alter either password, it affects
the other.

PointBase
Version 4.8 PointBase Developer 104
Granting and Revoking Privileges to Users
When you initially create a PointBase database, it automatically creates the user, PBPUBLIC
with a password of PBPUBLIC. The PBPUBLIC user owns the default PBPUBLIC schema.
For security reasons, PointBase does not recommend using this schema to store sensitive data.
Like any PointBase user, PBPUBLIC must be granted the appropriate privileges to access data
objects in schemas owned by other users.
PBPUBLIC users will own any new schema that they create unless otherwise specified while
creating the schema. New users are then able to create their own new schema and grant
appropriate privileges on objects in the schema that they own. All new users must be granted
privileges to access the objects in the PBPUBLIC schema if this is required.
To grant the ability for a user to pass a privilege on to other users, you must specify the
optional WITH GRANT OPTION qualifier when granting the privilege.
GRANT Syntax
GRANT <privilege-list>
ON <object>
TO <user> [ WITH GRANT OPTION ] | PUBLIC ]
[GRANTED BY <grantor>]
Use the GRANT statement to grant privileges on a data object. The following describes the
GRANT statement syntax.
GRANT <Privilege-list> Syntax
privilege [ , privilege [ , privilege ]…] | ALL PRIVILEGES
<Privilege> Syntax
SELECT [ ( column-name [ , column-name ]…)]
| DELETE
| INSERT [ ( column-name [ , column-name ]…)]
| UPDATE [ ( column-name [ , column-name ]…)]
| REFERENCES [ ( column-name [ , column-name ]…)]
| TRIGGER [ ( column-name [ , column-name ]…)]
| EXECUTE
Usage Notes
• If you do not include one or more of these privileges in the GRANT statement, an error
will be raised.
• If the optional “column-names” are not specified for the SELECT, INSERT, UPDATE,
REFERENCES and TRIGGER privileges, the GRANT is a table-level grant that allows
access to all present and future columns of the table.
• If you execute a GRANT statement that contains privileges that you don’t have or for
which you do not have the right to grant, then PointBase raises an error.

PointBase
Version 4.8 PointBase Developer 105
ON <Object> Syntax
[ TABLE ] table-name
|SPECIFIC routine_type specific_routine-name
|routine_type routine_name (parameter_types_list)
[ TRIGGER ] trigger-name
Usage Notes
• You may only grant the EXECUTE privilege on an SQL Function or Procedure. The user
cannot access tables that the SQL Function or Procedure uses.
TO <user/role-list> | [WITH GRANT OPTION] | PUBLIC Syntax
user [ , user ]... [WITH GRANT OPTION] | PUBLIC
Usage Notes
• If you do not specify WITH GRANT OPTION, the user cannot pass the same privilege
on to other users. However, if you do specify WITH GRANT OPTION, you have given
the user permission to pass on the privilege to other users.
• Granting a privilege to PUBLIC grants the privilege to all present and future users.
PUBLIC is a keyword, representing all users in the database.
• If you grant a privilege twice, and one of the times—either first or second—you granted
the optional WITH GRANT OPTION and the other time you granted it without the grant
option, the user will retain the grant option.
[GRANTED BY <grantor> ] Syntax
[GRANTED BY CURRENT_USER | user_name]
Usage Notes
• Use this option to indicate whether you want the grant to be from the CURRENT_USER
or the CURRENT_ROLE, or whether you want to revoke authorization records that were
granted from the CURRENT_USER or from the CURRENT_ROLE.
• If GRANTED BY <grantor> is not specified, then the grantor is the CURRENT_USER.
• If GRANTED BY CURRENT_ROLE is specified, then the CURRENT_ROLE must not
be NULL.
•A <grantor> of user_name is not ANSI standard. Only the users, PBSYSADMIN,
database owner, or someone with the PBDBA role can specify a <grantor> of
user_name.
Examples
• The following statement grants the SELECT privilege on the CUSTOMER_TBL table to
the user MARKETING_MGR.
GRANT SELECT
ON customer_tbl
TO marketing_mgr;

PointBase
Version 4.8 PointBase Developer 106
• The following GRANT statement allows the user FINANCIAL_MGR to delete, insert
and update rows from the DISCOUNT_CODE_TBL table; it also allows this user to
grant the same privileges to others.
GRANT DELETE,INSERT,UPDATE
ON discount_code_tbl
TO financial_mgr
WITH GRANT OPTION;
• The following GRANT statement allows the user HR_MGR to have ALL PRIVILEGES
on the table SALES_REP_DATA_TBL. However, the user HR_MGR will only be
granted privileges that the user granting the privileges has the right to grant. For example,
if the user granting the privileges does not have the right to grant DELETE privileges, the
HR_MGR will not have the delete privilege.
GRANT ALL PRIVILEGES
ON sales_rep_data_tbl
TO hr_mgr
REVOKE Syntax
REVOKE [ GRANT OPTION FOR ] <privilege_list>
ON <object>
FROM <user_name> [ RESTRICT | CASCADE ]
[GRANTED BY <grantor>]
To revoke a role from a user, use the SQL command, REVOKE. This command revokes only
the privileges that the specified <grantor> granted to the <user_name>. If another <grantor>
granted the same privileges to the <user_name>, then the <user_name> will still have those
privileges.
Please note that the syntax rules for the REVOKE syntax is similar to the GRANT statement.
The major difference is the additional RESTRICT or CASCADE keyword and the GRANT
OPTION FOR clause. The following describes the optional clauses GRANT OPTION FOR
and RESTRICT or CASCADE.
NOTE: You may only revoke privileges, which you have granted.
GRANT OPTION FOR
If the optional GRANT OPTION FOR clause is used, the WITH GRANT OPTION right is
revoked, but the actual privilege itself is not revoked. CASCADE and RESTRICT may be used
in the same way as a normal REVOKE statement.
RESTRICT | CASCADE
If you specify the RESTRICT keyword, only the privilege granted by you, will be revoked
from the specified user. If the specified user had the grant option and granted the same
privilege to other users, then PointBase will raise an error.
If you specify CASCADE, only the privilege granted by you, will be revoked from the
specified user and any other privileges dependent on your grant.
If the optional RESTRICT or CASCADE keywords are not used, PointBase uses CASCADE
by default.

PointBase
Version 4.8 PointBase Developer 107
Predefined Roles
This section describes predefined roles in PointBase. Predefined roles and roles in general can
save you time granting commonly-used privileges to a user, a group of users, or another role.
Predefined roles can provide you some type of authority over databases. Predefined roles and
roles in general are multiple privileges bundled into one object. You can typically use a
predefined role to apply commonly-used privileges to one user or a group of users or another
role. For example, one predefined role gives specified users all the privileges that a database
owner has. The other predefined role gives specified users read authority on all objects in the
database. You may not grant additional privileges to predefined roles. PointBase provides
the following predefined roles:
PBDBA Role
You have complete authority, including all privileges over the database using the PBDBA role.
Please note that it cannot be granted to other roles.
READALL Role
You can grant other users the read or SELECT authority on all objects in the database using the
READALL role. With it, any user can unload the entire database—regardless of who owns the
objects or what privileges have been granted on them.
Granting and Revoking Privileges to Roles
With PointBase, you have the capability to grant or revoke roles. They may contain multiple
privileges, which you can apply towards multiple users, without having to apply each privilege
one user at a time. Any user can grant roles to other users or to other roles if they have the
authority. Any user with the authority may grant additional privileges to roles.
To enable your current role, you must use the SQL command, SET ROLE. PointBase allows
you to enable or set your current role if your current user has been granted that role. A user
may only have one enabled role—one current role, at any given time—though a user may have
been granted several different roles. Please note that at any given time, users’ total privileges
are the sum of all privileges directly granted to them and any privileges or roles granted to their
current role.
The following diagram briefly characterizes roles by illustrating User I granting Role A to
User II and Role B. It also displays User III granting Role C to Role A and how User II and
Role B are affected by this change.

PointBase
Version 4.8 PointBase Developer 108
CREATE ROLE Syntax
CREATE ROLE <role_name> [WITH ADMIN <grantor>]
To create a role that can have privileges granted to it, use the SQL command CREATE ROLE.
The following explains the CREATE ROLE syntax.
<role_name>
It is the name of the role you are creating. For <role_name>, you may use any valid user
name, except PUBLIC, NONE, or the same name as an existing user.
<grantor> = CURRENT_USER | CURRENT_ROLE | user_name
A two-step diagram displaying what was described in the previous
paragraph and, showing User II and Role B acquiring Role C,
which was the result from the User III grant, also described in the
previous paragraph.
User I
Role A
Privilege A
Privilege B
GRANT ROLE A to
User II
Role B
User II
Role A
Privilege A
Privilege B
Role B
Role A
Privilege A
Privilege B
User I
Role A
Privilege A
Privilege B
S
tep 1
R
esult of Step 1
S
tep 2
R
esult of Step 2
Role A
Privilege A
Privilege B
Role A
Privilege A
Privilege B
Role C
Privilege C
Privilege D
GRANT ROLE C to
Role A
Privilege A
Privilege B
Role C
Privilege C
Privilege D
User I
Role A
Privilege A
Privilege B
Role C
Privilege C
Privilege D
Role B
Role A
Privilege A
Privilege B
Role C
Privilege C
Privilege D
User II
User III
Role C
Privilege C
Privilege D

PointBase
Version 4.8 PointBase Developer 109
•If WITH ADMIN <grantor> is not specified, then the grantor is the CURRENT_USER.
• IF WITH ADMIN CURRENT_ROLE is specified, then the CURRENT_ROLE must not
be NULL.
•A <grantor> of user_name is not ANSI standard. Only the PBSYSADMIN, database
owner, or someone in the PBDBA role can specify a <grantor> of user_name.
Examples
If the current user is SALES_MANAGER:
CREATE ROLE SALES WITH ADMIN CURRENT_USER
This will create a role called SALES whose owner is the user SALES_MANAGER. Privileges
can now be granted to the role SALES just as they can to a user. The user SALES_MANAGER
can then grant the role SALES to other users, or to other roles. These users or roles will then
have all the privileges that were granted to the role SALES, the same as if these privileges
were granted to them individually.
ed examples>
GRANT ROLE Syntax
GRANT <role_name> [ { , <role_name> } …]
TO <grantee> [{ , <grantee>} … ]
[WITH ADMIN OPTION]
[GRANTED BY <grantor>]
To grant users a role, use the SQL command, GRANT ROLE. The following explains its
syntax.
<role_name>
It is the name of the role you are granting. You may grant more than one role.
<grantee> = PUBLIC | <role_name>
• A role can be granted to users or other roles.
• You cannot grant a role to itself.
• You cannot grant one role to a second role, and then attempt to grant the second role back
to the first.
For example, you can grant Role (A) to Role (B) or Role (B) to Role (A), but
not both.
Such a series of grants would result in a role grant cycle, which is not allowed.
• Granting to PUBLIC grants the role to all present and future users and roles.
[WITH ADMIN OPTION]
If WITH ADMIN OPTION is specified, then the <grantee> can grant the role to other users or
roles. It also gives the <grantee> the right to drop the role.
<grantor> = CURRENT_USER | CURRENT_ROLE | user_name
• If you do not specify GRANTED BY <grantor>, then the grantor is the
CURRENT_USER.

PointBase
Version 4.8 PointBase Developer 110
• If you specify GRANTED BY CURRENT_ROLE, then the current role must not be
NULL.
• To successfully execute this command, current users must either be the PBSYSADMIN
or the database owner. Or, current users must either have the PBDBA role, or the
<grantor>s must have admin option for every role that they grant.
•A <grantor> of user_name is not ANSI standard. Only the PBSYSADMIN, database
owner, or someone in the PBDBA role can specify a <grantor> of user name.
REVOKE Syntax
REVOKE [ADMIN OPTION FOR] <role_name> [ { , <role_name> } …]
FROM <grantee> [{ , <grantee>} … ]
[GRANTED BY <grantor>]
<drop_behavior>
To revoke a role from a user or another role, use the SQL command, REVOKE. This command
revokes only the roles that the specified <grantor> granted to the <grantee>. If another
<grantor> granted the same role the <grantee>, then the <grantee> will still have privileges
to that role.
Please note that the syntax rules for the REVOKE syntax is similar to GRANT ROLE, except
for the following.
NOTE: You may only revoke roles, which you have granted.
[ADMIN OPTION FOR]
If ADMIN OPTION FOR is specified, then only the admin option for the role is revoked.
<drop_behavior> = CASCADE | RESTRICT
• If you specify the RESTRICT keyword, only the role granted by you, will be revoked
from the specified <grantee>. If the specified <grantee> had the ADMIN OPTION and
granted the same privilege to other users, they will retain the privilege.
• If you specify CASCADE, only the role granted by you, will be revoked from the
specified <grantee> and any other roles dependent on your grant.
• If the optional RESTRICT or CASCADE keywords are not used, PointBase uses
CASCADE by default.
DROP ROLE Syntax
DROP ROLE <role_name> [<drop_behavior>]
To successfully execute this command, the current user must be the PBSYSADMIN or the
database owner, or the current role must be PBDBA. If your current user or role has been
granted admin option on the role being dropped, you may also use this command.
<drop_behavior> = CASCADE | RESTRICT

PointBase
Version 4.8 PointBase Developer 111
• If the drop behavior is CASCADE, then all schemas owned by this role will be dropped.
Also, all privilege entries in the catalog tables where this role is the <grantor>, the
<grantee>, or the object being granted will be dropped.
• If the drop behavior is RESTRICT, then an error will be raised if there are any schemas
owned by this role or if there are any privilege entries, where this role is the <grantor>,
the <grantee>, or the object being granted.
• If drop behavior is not specified, then CASCADE is the default.
• You cannot drop the predefined roles: PBDBA and READALL.
SET ROLE Syntax
SET ROLE <role_name> | NONE
Usage Notes
• To successfully execute this command, the current user must be the PBSYSADMIN, the
database owner, or a user granted to use this role. Or, the current role must be PBDBA.
• This statement will set the current role for the current user to either the role specified or
to the null value if NONE is specified.
• If this statement is executed and an SQL transaction is currently active, then an error will
be raised: dbexcpITSActiveSQLX : "Invalid transaction state - active SQL-transaction".

Version 4.8 PointBase Developer 112
Application Programming
Interface Tools
This chapter describes what application programming interface (API) tools PointBase offers
and how to use them. Unlike other PointBase tools, for example, Commander and Console,
you can integrate the API tools explained in this chapter with a Java application. This chapter
will divide each API tool or combination of tools into sections, beginning with the main
purpose for using the tool(s), followed by a description of the Java classes and other
components, accompanied with a brief summary of how the different parts can work together
(if needed), and finally, ending with examples of how to implement the tool(s). After reading
or browsing this chapter, you may find a useful tool(s) that an application can integrate.
Load and Unload API’s
PointBase provides tools that you can use to either load or unload a database, or unload a table
using the load and unload API’s. Using it, you can write your application once and call
methods to unload or load a database without having to write anything on a command line.
However, you can also create a stand-alone tool or a command-line tool using the load and
unload API’s. Either way you choose, PointBase gives you the needed tools to load or unload a
database, or unload a table.
Unload API
To unload a database or table using the unload API, you must use the PointBase class,
“com.pointbase.tools.toolsUnload.” It contains two static methods,
“unloadDatabase(Connection p_conn, String p_filename, boolean p_preserve)” and
“unloadTable(Connection p_conn, String p_filename, String p_tableName).”
unloadDatabase(Connection p_con, String p_filename, boolean p_preserve)
To unload a complete database into directory as a specific .sql file, you must use the static
method, “unloadDatabase(Connection p_conn, String p_filename, boolean p_preserve).” You
need to create the connection and then pass the connection reference to the API. You also need
to provide the file name with the complete path; if you do not provide it, the API will unload
the database into a .sql file located in the directory, where you launched the application.

PointBase
Version 4.8 PointBase Developer 113
The third parameter preserves ownership when unloading. TRUE preserves the ownership of
schemas, grantors in GRANT statements, and create ROLE owners. But, it does not preserve
the DATABASE OWNER. Whoever creates the new database becomes the database owner.
See the example after the unload table method.
unloadTable(Connection p_conn, String p_filename, String p_tableName)
To unload an entire table into a specific .sql file and directory, you must use the static method,
“unloadTable(Connection p_conn, String p_filename, String p_tableName).” You need to
create the connection and then pass the connection reference to the API. You also need to
provide the file name with the complete path; if you do not provide it, the API will unload the
table into a .sql file located in the directory where you launched the application. If you unload
a table, you must provide the complete-qualified name of the table; that is,
“<schema_name>.<tableName>”; if you do not provide it, the API will search for the table
name in the current schema path. For mixed-case-table names, the example describes the
supported syntax.
import com.pointbase.tools.toolsUnload;
import java.sql.*;
public class test
{
Connection m_con;
public test() throws Exception
{
Class.forName("com.pointbase.jdbc.jdbcUniversalDriver");
m_con = DriverManager.getConnection("jdbc:pointbase:embedded:sample", "pbpublic",
"public");
}
public void unloadDatabase() throws Exception
{
toolsUnload.unloadDatabase( m_con, "e:\\pointbase\\database.sql", true);
toolsUnload.unloadTable( m_con, "e:\\pointbase\\table.sql", "public.t1");
//table names are case-sensitive, see the following:
toolsUnload.unloadTable( m_con, "e:\\pointbase\\table1.sql", "public.ajay");
}
public static void main( String[] args)
{
try
{
test t = new test();
t.unloadDatabase();
}
catch(Exception ex)
{
System.out.println("Exception occurred: " + ex);
}
}
}
Stand-Alone or Command Line Tool
To use the unload tool on the command line, you can use the following example, which
unloads a complete database into the file, “database.sql” in the directory, “e:\.” It also
preserves the ownership of schemas, grantors in GRANT statements, and create ROLE
owners. But, it does not preserve the DATABASE OWNER. Whoever creates the new
database becomes the database owner. You must provide the file name with the complete path;
if you do not provide it, the API will unload the table into a .sql file located in the directory
where you launched the application.

PointBase
Version 4.8 PointBase Developer 114
If you unload a table, you must provide the complete-qualified name of the table; that is,
“<schema_name>.<tableName>”; if you do not provide it, the API will search for the table
name in the current schema path. For mixed-case-table names, the example describes the
supported syntax. It uses the following default options:
• -driver com.pointbase.jdbc.jdbcUniversalDriver
• -url jdbc:pointbase:embedded:sample
• -user PBPUBLIC
• -password PBPUBLIC
java com.pointbase.tools.toolsUnload
–driver com.pointbase.jdbc.jdbcUniversalDriver –url jdbc:pointbase:embedded:sample –
file e:\database.sql -preserve true –user pbpublic –password pbpublic -table null
To unload a table, you can refer to the following example:
java com.pointbase.tools.toolsUnload
–driver com.pointbase.jdbc.jdbcUniversalDriver –url jdbc:pointbase:embedded:sample –
file e:\table.sql –user pbpublic –password pbpublic -table pbpublic.table1
Load API
To load a database using the load API, you must use the PointBase class,
"com.pointbase.tools.toolsLoad." It contains couple of static method, First "load (Connection
p_conn, String p_filename)."
load( Connection p_conn, String p_filename)
Using this method, you must first create the connection and then pass the connection reference
to the API. You must also provide the file name with the complete path, if you do not provide
the complete path, the API will try to load the file from the current location of the application.
The following example describes the connection, "m_con" and the complete path and file
name, "e:\pointbase\database.sql."
import com.pointbase.tools.toolsLoad ;
import java.sql.*;
public class test
{
Connection m_con;
public test() throws Exception
{
Class.forName("com.pointbase.jdbc.jdbcUniversalDriver");
m_con = DriverManager.getConnection("jdbc:pointbase:embedded:sample", "pbpublic",
"pbpublic");
}
public void loadDatabase() throws Exception
{
toolsLoad.load( m_con, "e:\\pointbase\\database.sql");
}
public static void main( String[] args)
{
try
{
test t = new test();
t.loadDatabase();
}
catch(Exception ex)
{
System.out.println("Exception raised: " + ex);
}
}
}

PointBase
Version 4.8 PointBase Developer 115
Second "load (Connection p_conn, InputStream p_in)".
load (Connection p_conn, InputStream p_in)
Using this method, you must first create the connection and then pass the connection reference
to the API. You must also provide the InputStream; if you do not provide it, your program will
not compile. The following example describes the connection, "m_con" and an Input file
Stream to read from a file with the specified name "e:\pointbase\database.sql."
import com.pointbase.tools.toolsLoad;
import java.sql.*;
import java.io.*;
public class test
{
Connection m_con;
public test() throws Exception
{
Class.forName("com.pointbase.jdbc.jdbcUniversalDriver");
m_con = DriverManager.getConnection("jdbc:pointbase:embedded:sample", "pbpublic",
"pbpublic");
}
public void loadDatabase() throws Exception
{
toolsLoad.load( m_con, new FileInputStream("e:\\pointbase\\database.sql"));
}
public static void main( String[] args)
{
try
{
test t = new test();
t.loadDatabase();
}
catch(Exception ex)
{
System.out.println("Exception raised: " + ex);
}
}
Stand-Alone or Command Line Tool
To use the load tool on the command line, you can use the following example, which loads a
complete database into the file, “database.sql” in the directory, “e:\.” You must provide the
file name with the complete path; if you do not provide it, the API will try to load the file from
the current location of the application. It uses the following default options:
• -driver com.pointbase.jdbc.jdbcUniversalDriver
• -url jdbc:pointbase:embedded:sample
• -user PBPUBLIC
• -password PBPUBLIC
•
java com.pointbase.tools.toolsLoad –driver com.pointbase.jdbc.jdbcUniversalDriver –
url jdbc:pointbase:embedded:sample –file e:\database.sql –user pbpublic –
password pbpublic –log true

PointBase
Version 4.8 PointBase Developer 116
Database Compress Tool
PointBase provides a tool that you can use to compress the database. This tool can be only used
as a command line tool.
Command Line Tool
To use the Compress tool on the command line, you can use the following example, which will
compress the database called "sample" in the directory "e:\". Make sure that the user specified
is PBSYADMIN, Database Owner or the default role for that user is PBDBA. A backup of the
existing database will made and the name of the backed up database will renamed as
<database>.bak. The tool uses the following default options:
· -database sample
· -user PBPUBLIC
· -password PBPUBLIC
· -unloadfolder <current folder>
· -unloadfilename sample.sql
java com.pointbase.tools.toolsDbCompress -database sample -user PBPUBLIC -password
PBPUBLIC -unloadfolder e:\ -unloadfilename sample.sql
The database must be located on the local machine. This utility will not work over the network.
The user needs to set the database home either using the java -D option or by providing
pointbase.ini in the current folder from where this utility is run. The user should have enough
disk space for the unload file, the backed up database and the new database.
Important Note for UniSync Users
If you are using UniSync - the database synchronization tool for PointBase databases - to
synchronize a database and you use the compress tool on it, the next synchronization must be a
snapshot operation. UniSync tracks incremental activity using the database log files and
performing a compress operation results in the log files being completely regenerated.
Incremental activity tracking cannot survive this, and so a fresh snapshot is required following
a database compress operation.

Version 4.8 PointBase Developer 117
Appendix A: SQL Reference
Conventions
This section describes documentation conventions. There are two basic conventions:
1. Page format conventions provide a structure for the organization of individual pages
in the documentation.
2. Syntax conventions convey specific information about keywords and clauses in the
SQL statements described in this document.
Page Format Conventions
Each SQL statement in the data manipulation language, data definition language, and
transaction control sections of the PointBase SQL documentation uses a specific page format.
• Each statement page starts with the primary keyword of the statement, which displays at
the heading of the page; for example, SELECT.
• The statement keyword(s) is followed by the syntax of the statement. The statement
syntax follows the conventions described in “Syntax Conventions,” below.
• Immediately following the statement syntax is a brief description of the overall statement.
• Detailed explanations are then described for each keyword and clause in the statement.
Some clauses may include a more detailed explanation of their own syntax or links to
other documents that describe clauses that are common to more than one SQL statement.

PointBase
Version 4.8 PointBase Developer 118
Syntax Conventions
Each SQL statement uses certain types of capitalization, formatting, and punctuation that
describe the attributes of different portions of the statement.
• If a portion of an SQL statement displays in UPPERCASE, the capitalized words are
keywords, which are generally required in the SQL statement or clause. Keywords are not
case sensitive, and they must be spelled exactly as they display in this document.
• Portions of SQL statements that display in lowercase italic are SQL values. SQL values
used in PointBase SQL can be constants, column names, values formed from
combinations of column values and constants, or the result of any function that returns a
single value. The values for variables in conditional expressions are case sensitive.
• The clauses in an SQL statement that display between [brackets] are optional. If an
optional clause has several components or keywords, they display within the brackets.
• Curly braces {} in SQL statements indicate that one or more clauses are used together.
• Ellipses are sets of periods (such as “...”). Ellipses in an SQL statement have the same
meaning as “etc.”; they denote that the series of keywords, clauses, or variables that
precede the ellipses go on indefinitely.
Data Definition Language
The following section describes the syntax for creating and managing logical data objects. The
Data Definition Language (DDL) is essential to creating a database. Use the following DDL
statements and operations to begin building your PointBase database.
• "CREATE SCHEMA" on page 119
• "CREATE TABLE" on page 120
• "CREATE VIEW" on page 132
• "CREATE USER" on page 134
• "CREATE ROLE" on page 135
• "CREATE INDEX" on page 136
• "CREATE FUNCTION" on page 137
• "CREATE PROCEDURE" on page 141
• "CREATE TRIGGER" on page 144
• "ALTER USER" on page 153
• "ALTER TABLE" on page 151

PointBase
Version 4.8 PointBase Developer 119
CREATE SCHEMA
CREATE SCHEMA schema_name
[ AUTHORIZATION user_name ]
[COUNTRY country_code [LANGUAGE language_code]]
The CREATE SCHEMA statement creates a schema in a PointBase database.
Syntax
CREATE SCHEMA The CREATE SCHEMA keyword is required as the first words
in a CREATE SCHEMA statement.
schema_name
a
a. PointBase recommends to use the same name for both the schema_name and the
user_name. Once you log in, PointBase creates new objects in the schema that has the
same name as your user_name. If no schema has the same name as your user_name,
PointBase creates the new objects in the PBPUBLIC schema.
The name of the schema.
user_name The schema owner name or the role name. If you specify a role
name, any user who enables the specified role can have full
schema ownership privileges. The schema owner name or the
role name must exist in the database or an error is raised. If
user_name is not specified the current user_name is the owner of
the schema.
country_code
b
b. Please refer to Country and Language Codes of the PointBase System Guide for a
list of valid country codes and languages.
Specifies the country code. The default country code is US
English. When this option is used, char data is stored as Unicode.
If this option is NOT used, char, varchar, and CLOB columns use
US ASCII values.
language_code Specifies the language code. The default language code is US
English. When this option is used, char data is stored as Unicode.
If this option is NOT used, char, varchar, and CLOB columns use
US ASCII values.

PointBase
Version 4.8 PointBase Developer 120
Examples
CREATE SCHEMA ORDERS
AUTHORIZATION Orders_Mgr
COUNTRY FR
LANGUAGE FR;
CREATE TABLE
CREATE [GLOBAL TEMPORARY] TABLE table_name (column_definition |
table_constraint_definition
[{, column_definition | table_constraint_definition}...]) [TABLE PAGESIZE size, LOB
PAGESIZE size] [ON COMMIT {PRESERVE|DELETE} ROWS]
[COUNTRY country_code [LANGUAGE language_code]]
[ORGANIZATION {INDEX|HEAP}]
The CREATE TABLE statement creates the table structures for the PointBase database. The
CREATE TABLE statement allows you to define the table by name, to define the columns,
default values, keys, and constraints on the table.
Syntax
CREATE TABLE The CREATE TABLE keywords are required as the first words
in a CREATE TABLE statement.
GLOBAL TEMPORARY The GLOBAL TEMPORARY keyword creates a global
temporary table. Once a global temporary table is defined, the
definition will be persistent in SYSTABLES. Global temporary
table is materialized only when referenced in an SQL-Session.
Each SQL-Session maintains distinct instance of global
temporary table materialized in that session. Hence contents of
global temporary table is not shared between SQL-Sessions. For
global temporary table, ON COMMIT clause must be supplied or
ON COMMIT DELETE ROWS is implicitly implied.
table_name The table_name is the name of the table structure. The table
name cannot be the same as a PointBase keyword. Table names
in the PointBase database are not case sensitive and can be up to
128 characters long.
column_definition The column_definition contains all the information needed to
define the columns that are a part of a table. See the following
pages for the section on column_definition syntax.
table_constraint_definition The table_constraint_definition allows you to define a constraint
that is applicable to the table. Usually this type of constraint is
used when you specify multiple columns for any type of
constraint. See the following pages for the section on
table_constraint_definitions.

PointBase
Version 4.8 PointBase Developer 121
ON COMMIT
{PRESERVE | DELETE}
ROWS
This parameter specifies the lifespan of temporary tables. For on
commit preserve rows, the life of temporary tables is for the
entire session. For on commit delete rows, the life of temporary
tables is only for each transaction.
TABLE PAGESIZE size Use the TABLE PAGESIZE keywords after all the column
definitions and table constraint definitions to define the page size
of the table. If this specification is omitted, the table uses the
default pagesize as set in the database properties file
(pointbase.ini). Size can be one of the following:
• a number, such as 1024
• Kilobytes, such as 1K
• Megabytes, such as 1M
LOB PAGESIZE size Use the LOB PAGESIZE keywords after all the column
definitions and table constraint definitions to define the page size
of the BLOB and CLOB columns. If this specification is omitted,
the LOB uses the default pagesize. If both table and LOB
pagesizes are specified, either the table or the LOB pagesize can
be defined before the other. Size can be the following:
• a number, such as 1024
• Kilobytes, such as 1K
• Megabytes, such as 1M
It is required only if one or more columns in the table contain
LOB characters. You should specify this only once, even if the
table has multiple LOB columns. All LOBs will use pages of this
size for storing LOBs, unless the LOB fits into the data page.
If this specification is omitted, the LOB pages use the default
page size.
COUNTRY country_code Specifies the country code. The default country code is US
English
a
. When this option is used, char data is stored as
Unicode. If this option is NOT used, char, varchar, and CLOB
columns use US ASCII values.

PointBase
Version 4.8 PointBase Developer 122
A table has a given locale property if the following items are fulfilled:
• the country code or language code is explicitly specified in the CREATE TABLE
statement.
• the country code or language code is explicitly specified in the CREATE SCHEMA
statement.
• language and country settings are specified in the pointbase.ini file.
LANGUAGE
language_code
Specifies the language code. The default language code is US
English. When this option is used, char data is stored as Unicode.
If this option is NOT used, char, varchar, and CLOB columns use
US ASCII values.
ORGANIZATION (INDEX |
HEAP)
Specifies how the rows of the table are to be physically stored.
ORGANIZATION HEAP is the default and is sometimes
referred to in this document as a "regular" table organization. In a
regular table organization, all the rows of the table are stored in
no particular order. If ORGANIZATION INDEX is specified,
then the rows are stored in the order of the primary key values.
Therefore, a primary key constraint must be declared if
ORGANIZATION INDEX is specified. The total declared
maximum size of all columns in an index-organized table must
fit within the table page size, including lobs. Dropping a column,
or adding or dropping the primary key via the ALTER TABLE
command is not allowed on an index organized table. Please see
the chapter "Index Organized Tables" for more information about
this type of table organization.
a. Please refer to Country and Language Codes of the PointBase™ System Guide for a list
of valid country codes and languages

PointBase
Version 4.8 PointBase Developer 123
Column_Definition Syntax
column_name data_type [identity_property | default_clause] [column_constraint]
column_name The column_name is the name of the column structure within the
table created with the CREATE TABLE statement. The column
name must be composed of alphanumeric characters or the
equivalent in another language, for example, a word in Japanese
characters and cannot be the same as a PointBase keyword. The
column name must be unique within the table that contains it.
Column names in the PointBase database are not case sensitive
and can be up to 128 characters in length.
data_type The data type describes the type of data that can be stored in the
column.
identity_property
IDENTITY [(start_value, increment_value)]
IDENTITY [(start_value, increment_value)]The IDENTITY
keyword is used indicate that this column should have its values
generated by the database system. Each value is guaranteed to be
unique, starting with start_value, and is automatically
incremented by increment_value after every insert into the table.
An IDENTITY column is sometimes referred to as an auto-
increment column, and is suitable for use as a primary key.
start_value is the value that should be used for the first insert into
the table. The value must be a value greater than zero. If you do
not specify this value, the default is 1 (one). increment_value is
an incremental value based on the start_value. The value must be
a value greater than zero. If you do not specify this value, the
default is 1.The maximum value for either start_value or
increment_value is equal to the maximum value possible for the
data type. For example, The maximum value possible for
NUMERIC (4,0) is 9999. You can have IDENTITY columns
with exact numeric data types and a 0 (zero) scale only. The
exact numeric data types include INTEGER, SMALLINT,
NUMERIC, or DECIMAL. You cannot update IDENTITY
columns nor can you specify NULL for them. Also, you can only
have one IDENTITY column in a table.
(See "IDENTITY Property for Autoincrement" on page 44.)

PointBase
Version 4.8 PointBase Developer 124
default_clause The default_clause allows one to specify default values for a
given column. The clause must begin with the keyword
DEFAULT. Possible default values and an example are:
• character string literal: ‘abc’
• numeric literal: 123
• datetime literal: time ‘22:45:21’
• binary string literal: X’104dc2’
• boolean literal: TRUE
• NULL value
• datetime value functions: CURRENT_DATE,
CURRENT_TIME, CURRENT_TIMESTAMP
• special registers
• SQL routine
The default value can be used with SQL Insert and Update
statements. Specify either DEFAULT or specify nothing at all
and the default value will be inserted.
Example: CREATE TABLE T1 (C1 INT, C2 TIMESTAMP
DEFAULT CURRENT_TIMESTAMP)
column_constraint The column_constraint is one or more keywords that restricts the
data that can be written to a particular column. The PointBase
database currently supports the following column constraints. All
column constraints are optional.
• NOT NULL
•PRIMARY KEY
• UNIQUE
• FOREIGN KEY
•CHECK

PointBase
Version 4.8 PointBase Developer 125
Column_Constraints
NOT NULL The optional NOT NULL keyword indicates that a particular
column must have a non-NULL value associated with it. If one
performs any action to a table that results in a NOT NULL
column having a NULL value, the PointBase database returns a
runtime error. The syntax for the NOT NULL column constraint
is:
NOT NULL
PRIMARY KEY The optional PRIMARY KEY keyword creates an index for a
column. The syntax for the PRIMARY KEY column constraint
is:
PRIMARY KEY
The PRIMARY KEY column constraint can specify only one
column. To specify a PRIMARY KEY constraint with multiple
columns, use a table_constraint.
UNIQUE The optional UNIQUE constraint defines a unique key on the
column. All values for this column must be unique.
The syntax for the UNIQUE column constraint is:
UNIQUE
The UNIQUE column constraint can specify only one column.
To specify a UNIQUE constraint with multiple columns, use a
table_constraint.
FOREIGN KEY The optional FOREIGN KEY keyword indicates that a
relationship exists between the column value of this table
(known as the child table) and the primary key of the parent table
referenced in the REFERENCES clause. The syntax for the
FOREIGN KEY constraint is:
FOREIGN KEY
REFERENCES table_name (column_name )
[ON DELETE {NO ACTION | RESTRICT | CASCADE | SET
DEFAULT | SET NULL}]
[ON UPDATE {NO ACTION | RESTRICT |CASCADE | SET
DEFAULT | SET NULL}]
The ON DELETE clause defines the rules for deleting specific
columns on the specified table. To do this, specify either:
NO ACTION, CASCADE, RESTRICT, SET DEFAULT or SET
NULL.
You must specify at least one identifier. NO ACTION omits the
ON DELETE clause. RESTRICT looks to see what objects are
dependent on the object being dropped and if there are dependent
objects, then the dropping of the object does not occur.
CASCADE has the effect of dropping all SQL objects that are
dependent on that object. SET DEFAULT assigns default values
to all components of the target column. SET NULL assigns null
values to all components of the target column.

PointBase
Version 4.8 PointBase Developer 126
Table_Constraint_Definition
The table_constraint_definition allows you to define a constraint that is applicable to the table.
Usually this type of constraint is used when you specify multiple columns for any type of
constraint. There can only be a single column_constraint per column. The
table_constraint_definition uses the syntax of:
[CONSTRAINT constraint_name] {unique_constraint | referential_constraint
|check_constraint} [<constraint characteristics>]
<constraint characteristics> ::= <constraint check time> [ [ NOT ] DEFERRABLE ]
| [ NOT ] DEFERRABLE [ <constraint check time> ]
<constraint check time> ::= INITIALLY DEFERRED | INITIALLY IMMEDIATE
The ON UPDATE clause defines the rules for updating specific
columns on the specified table. To do this, specify either:
NO ACTION, RESTRICT, CASCADE, SET DEFAULT or SET
NULL.
If the ON DELETE or ON UPDATE clauses are omitted, the
default is NO ACTION.
FOREIGN KEY REFERENCES are required keywords,
table_name is the name of a table that already exists in the
PointBase database, and the column_names are the names of the
columns that define the primary key of the referenced table.
This column and the column in the referenced table must have
exactly the same data type. The referenced table must have a
unique or primary index on the specified column.
A foreign key relationship means that any values written to a
column with an INSERT or UPDATE statement must already
exist as a value in the primary key of the referenced table and
columns.
CHECK The optional CHECK keyword indicates that the value of a
column to be inserted or updated must meet the criteria of the
check constraint. The syntax for the CHECK constraint is:
CHECK ( search_condition )
where the search_condition follows the rules of search conditions.
constraint_name The name that one supplied to identify a constraint. Each
constraint_name must be unique for a table. The
constraint_name is optional but if two constraints have the same
definition, then they will each need a name for uniqueness.
unique_constraint The unique_constraint defines an explicitly named primary key
or unique constraint of one or more columns.
The syntax for the unique_constraint is:
{UNIQUE | PRIMARY KEY} (column_name [{,
column_name}...])

PointBase
Version 4.8 PointBase Developer 127
referential_constraint The referential_constraint defines an explicitly named foreign
key constraint of one or more columns.
The syntax for the referential_constraint is:
FOREIGN KEY (column_name [{, column_name}...])
REFERENCES table_name [{column_name,
column_name,...}]
[ON DELETE {NO ACTION | CASCADE | RESTRICT | SET
DEFAULT | SET NULL}]
[ON UPDATE {NO ACTION | CASCADE | RESTRICT | SET
DEFAULT | SET NULL}]
[INDEX PAGESIZE <size>]
A given foreign key and its matching candidate key must contain
the same number of columns, N, such as: the Ith column of the
foreign key corresponds to the Ith column of the matching key (I
= 1 to N), and corresponding columns must have exactly the
same data type.
The referenced table must have a unique or primary index on the
specified columns. Not allowed on a view. PointBase raises an
error if you attempt this on a view.
If the column_name for the referenced table is omitted, it
defaults to the columns in the primary key of the referenced
table.

PointBase
Version 4.8 PointBase Developer 128
ON DELETE The ON DELETE clause defines the rules of behavior when an
attempt is made to delete a row in the parent table that has a
corresponding row in the referencing table that is dependent on
the row in the parent table. The dependency is based on the
columns of the FOREIGN KEY in the parent table and
corresponding columns in the referencing table. The purpose of
this clause is to avoid dangling references.
If the behavior rule is CASCADE, then all dependent or
matching rows in the referencing table are deleted when the row
in the parent table is deleted.
If the behavior rule is NO ACTION, then if an attempt is made to
delete a row in the parent table that has a dependent row in the
referencing table, the row in the parent table will not be deleted.
If the behavior rule is RESTRICT, then if an attempt is made to
delete a row in the parent table that has a dependent row in the
referencing table, the row in the parent table will not be deleted.
The database checks before attempting to delete the row in the
parent table.
If the behavior rule is SET DEFAULT, then the columns of the
rows in the referencing table are set to default values for their
respective columns when the row in the parent table is deleted.
Each column of the referencing table that corresponds to the
FOREIGN KEY in the parent table must have a default value or
an exception will be raised.
If the behavior rule is SET NULL, then the columns of the rows
in the referencing table are set to the SQL NULL value for their
respective columns when the row in the parent table is deleted.
Each column of the referencing table that corresponds to the
Foreign Key in the parent table must allow SQL NULL values or
an exception will be raised.

PointBase
Version 4.8 PointBase Developer 129
ON UPDATE The ON UPDATE clauses defines the rules of behavior when an
attempt is made to update the FOREIGN KEY columns in the
parent table that has a corresponding row(s) in the referencing
table that is dependent on the values of the FOREIGN KEY
columns in the parent table.
If the behavior rule is CASCADE, then all dependent or
matching columns of rows in the referencing table are updated
with the new values in the FOREIGN KEY columns of the
parent table row.
If the behavior rule is NO ACTION, then if an attempt is made to
update columns of the FOREIGN KEY in the parent table and
there are columns of rows in the referencing table that are
dependent on the pre-updated values, then the update of the
FOREIGN KEY columns in the parent table do not occur.
If the behavior rule is RESTRICT, then if an attempt is made to
update columns of the FOREIGN KEY in the parent table and
there are columns of rows in the referencing table that are
dependent on the pre-updated values, then the update of the
FOREIGN KEY columns in the parent table does not occur. The
database checks before attempting to update the row in the parent
table.
If the behavior rule is SET DEFAULT, then all dependent or
matching columns of rows in the referencing table are updated
with the default values of the referencing table. Each column of
the referencing table that corresponds to the FOREIGN KEY in
the parent table must have a default value or an exception will be
raised.
If the behavior rule is SET NULL, then the columns of the rows
in the referencing table are set to the SQL NULL value for their
respective columns when the row in the parent table is updated.
Each column of the referencing table that corresponds to the
Foreign Key in the parent table must allow SQL NULL values or
an exception will be raised.
check_constraint The check_constraint defines an explicitly named check
constraint of one or more columns.
The syntax for the check_constraint is:
CHECK ( column_name search_condition )

PointBase
Version 4.8 PointBase Developer 130
NOTE: Creating a table with the CREATE TABLE statement creates the table structures, but
does not add any data to the table. An INSERT statement for a table, or a LOAD via an
IMPORT statement in PointBase Console, or a RUN in PointBase Commander, must
follow the creation of the table.
constraint
characteristics
The constraint_characteristics defines deferrable characteristics
for this constraint. A constraint may be set to deferrable or not
deferrable and initial behavior of constraint check time to be
initially deferred or initially immediate. The syntax rule is as
follows:. If constraint check time is not specified, then initially
immediate is implicit.. If deferrable is not specified, then not
deferrable is implicit.
constraint check time The constraint check time defines the initial behavior of a
constraint, it can be initially deferred or initially immediate.The
syntax rule is as follows:. If initially deferred is specified, not
deferrable shall not be specified or deferrable is implicit. If
initially immediate is specified or implicit and neither deferrable
nor not deferrable is specified, then not deferrable is implicit.

PointBase
Version 4.8 PointBase Developer 131
Example 1
CREATE TABLE ORDER_TBL
(ORDER_NUM INT,
CUSTOMER_NUM INT,
REP_NUM INT,
PRODUCT_NUM INT,
SALES_TAX_ST_CD CHAR (2),
QUANTITY SMALLINT,
SHIPPING_COST DECIMAL(12,2),
SALES_DATE DATE,
DELIVERY_DATETIME TIMESTAMP,
FREIGHT_COMPANY VARCHAR (30))
COUNTRY FR
LANGUAGE FR;
Example 2
This creates a table with a 5k page size:
CREATE TABLE TM5 (C1 INT PRIMARY KEY) TABLE PAGESIZE 5K;
This creates a table with a default page size, but the primary key constraint specifies a page
size of 2K for the index:
CREATE TABLE TM (C1 INT NOT NULL, C2 CHAR (10),
CONSTRAINT PKCONSTRAINT PRIMARY KEY (C1)
INDEX PAGESIZE 2K);
In this example, each index has a different pagesize:
CREATE TABLE TMF (C1 INT, C2 CHAR (10), C3 INT NOT NULL,
CONSTRAINT PK_TMF PRIMARY KEY (C3)INDEX PAGESIZE 5K
CONSTRAINT FK_TMF FOREIGN KEY (C1) REFERENCES TM (C1) INDEX PAGESIZE 3K );
In this example, all LOBs in the table have pagesize and the LOBs automatically create 5K
pagesize file for the LOB index:
CREATE TABLE TMBLOB (C1 INT NOT NULL, C2 BLOB (10K), C3 BLOB (5K))
LOB PAGESIZE 5K;
CREATE INDEX TMIX ON TMBLOB (C1) INDEX PAGESIZE 6K;
Example 3
This creates a table with a column having the IDENTITY property. This column will have the
ability to autoincrement the values for each row.
CREATE TABLE TAB1(ID INT IDENTITY, NAME VARCHAR(30));
Example 4
CREATE TABLE T1 (C1 INT, C2 TIMESTAMP DEFAULT CURRENT_TIMESTAMP);

PointBase
Version 4.8 PointBase Developer 132
CREATE VIEW
CREATE VIEW <view name> [ ( view_column_list )]
AS query_expression
[ WITH [ levels_clause ] CHECK OPTION ]
The CREATE VIEW statement creates a view or derived table in the PointBase database.
Notes
• To create a view, you must own the schema, in which you are creating the view.
• You must have SELECT permission on all referenced columns of all referenced tables in
the query expression.
• You can have “nested views,” which are views that reference other views.
• To grant privileges on a view, you must have SELECT grant privileges on all referenced
columns of all referenced tables in the query expression.
Syntax
CREATE VIEW The CREATE VIEW keywords are required as the
first words in a CREATE VIEW statement
view_name The name of the view. The name is not case sensitive
and can be up to 128 characters long.
view_column_list Specify a view column list if the query expression
includes two columns with the same name. The view
column list and the query expression must specify the
same amount of column names. If no view column
list is specified, then the view column names are
derived from the query expression (select column
list).
query_expression This is a SELECT statement. If the query expression
does not include a column, it must have an AS clause
correlation name defined. If it includes a column, the
view column name is the column name without any
table correlation name. The query expression is not
allowed to contain any parameters and is limited to
3958 characters.

PointBase
Version 4.8 PointBase Developer 133
Examples
CREATE VIEW customer_order
AS select order_num,order_tbl.customer_num,customer_tbl.name
FROM order_tbl,customer_tbl
WHERE product_num = 10;
CREATE VIEW customer_order1
AS select order_num,order_tbl.customer_num
FROM order_tbl,customer_tbl
WHERE order_tbl.customer_num = customer_tbl.customer_num;
CREATE VIEW customer_order2
AS select order_num,order_tbl.customer_num
FROM order_tbl,customer_tbl
WHERE order_tbl.customer_num = customer_tbl.customer_num and product_num=10;
CREATE VIEW namereps
AS select first_name,last_name
FROM sales_rep_tbl
WHERE last_yr_sales in (4000,6000,10000);
CREATE VIEW order_by_rep (who,how_many,total,low,high,average)
AS select rep_num,count(*), sum(quantity),min(quantity),max(quantity),avg(quantity)
FROM order_tbl group by rep_num;
CREATE VIEW customer_order3
AS select order_num,first_name
FROM customer_order,namereps;
CREATE VIEW exceed_quotas
AS select office_num, sum(quota) as sum_quota, sum(ytd_sales) as sum_ytd
FROM sales_rep_tbl
GROUP BY office_num
HAVING sum(ytd_sales) > sum(quota);
WITH CHECK OPTION This option uses the WHERE clause in the view’s
query_expression like a table constraint: all resultant
rows from an INSERT or UPDATE on the view must
satisfy the WHERE clause. If no levels_clause is
specified, CASCADED is implicit.
However, PointBase currently does not support
Updateable Views. That is, PointBase supports the
syntax for WITH CHECK OPTION, but currently
not the semantics.
levels_clause CASCADED indicates that all resultant rows from an
INSERT or UPDATE on the view must satisfy the its
own WHERE clause and the WHERE clause of any
views that are referenced.
LOCAL indicates that all resultant rows from an
INSERT or UPDATE on the view must only satisfy
its own WHERE clause.
If no levels_clause is specified, CASCADED is
implicit.

PointBase
Version 4.8 PointBase Developer 134
CREATE USER
The CREATE USER statement creates a user in a given PointBase database and can assign a
default role to that user. To successfully execute this command, the current user must be the
PBSYSADMIN or the database owner. [See "Predefined Users" on page 89.] Or, the current
role must be PBDBA. [See "Predefined Roles" on page 93.]
The user_name and password are SQL identifiers and behave like any other identifiers. They
will be converted to uppercase if not specified within double quotes and will be taken as it is
when specified within the double quotes.
The user names and passwords are used by JDBC methods, which create a connection. The
user names and passwords are specified as java strings in these methods and do not follow
same rules as SQL identifiers. This could lead to problems where connection will fail due to
invalid password. To avoid this problem the INI parameter
connection.convertUserInfoToUppercase will indicate the behavior of username and password
strings in the JDBC connection methods. This INI parameter will determine whether the
usernames and passwords in the JDBC connection methods will be converted to upper case or
taken as specified. The default value is to convert to uppercase i.e value of the INI parameter is
true. For enhanced security the value for this INI parameter can be set to false which means the
usernames and passwords have to be specified as created in the CREATE USER and ALTER
USER statements. Also note that the username and password for the default user PBPUBLIC
will always be treated as uppercase.
Syntax
CREATE USER user_name PASSWORD password [DEFAULT ROLE Role-Specification]
<user_name>: IDENTIFIER
<password>: IDENTIFIER
<Role-Specification> IDENTIFIER
Example
1. CREATE USER PoInT PASSWORD BaSE;
Creates a user POINT with password BASE.
2. CREATE USER "PoInT" PASSWORD "BaSE";
Creates a user PoInT with password BaSE.
CREATE USER The CREATE USER keyword are required as the first words in a
CREATE USER statement.
user_name The name of the new user. You cannot use the keyword
PUBLIC or an existing role name for the user name.
password The password associated with the user.
role_specification The default role_specification is NONE.

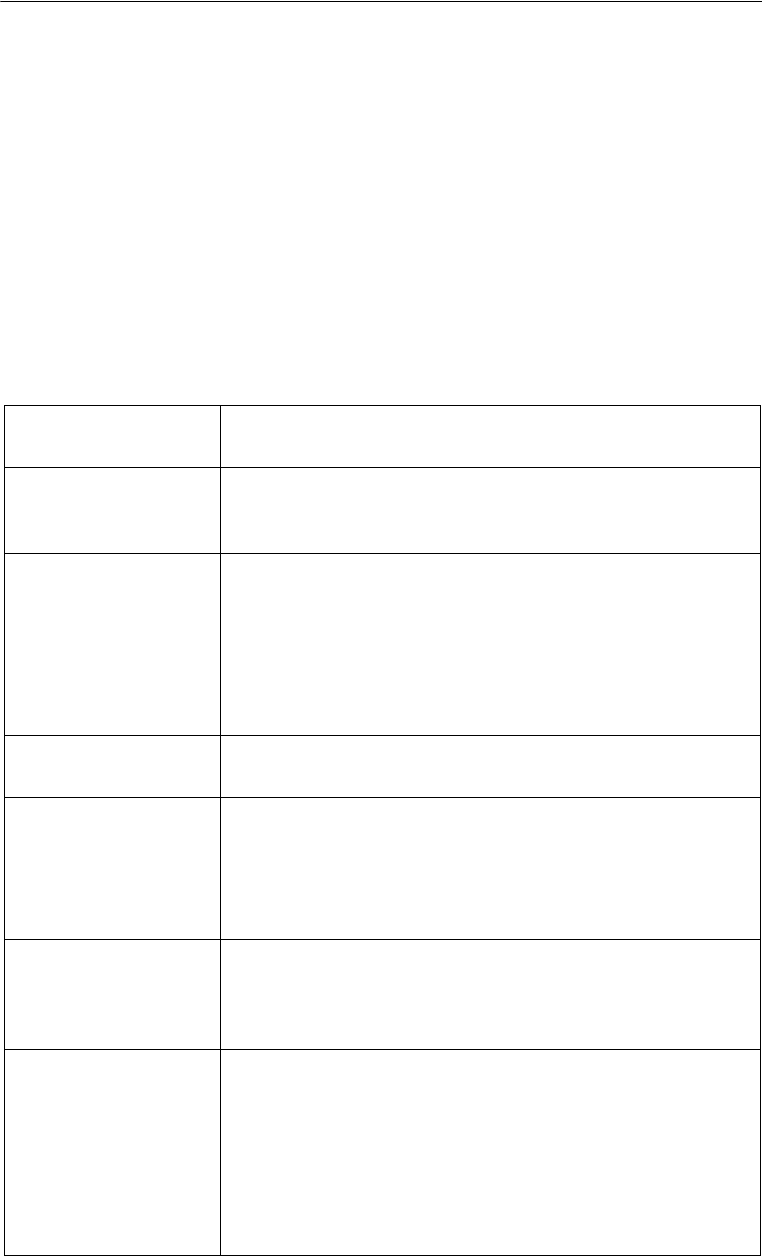
PointBase
Version 4.8 PointBase Developer 136
CREATE INDEX
CREATE [UNIQUE] INDEX index_name
ON table_name
(column_name [sort_order] {, column_name [sort_order]...})
[INDEX PAGESIZE size]
The CREATE INDEX statement creates the index structures.
Syntax
CREATE INDEX The CREATE INDEX keywords are required as the first words in
a CREATE INDEX statement.
[UNIQUE] If the UNIQUE keyword is specified, then the index will be
defined as a unique index where duplicate values of the keys are
not allowed.
index_name The index_name is the name of the index. Compose the index
name of alphanumeric characters or the equivalent in another
language, for example, a word in Japanese characters, which are
not the same as a PointBase keyword, unless the name is a
delimited identifier. The index name must be unique for its table.
Index names in the PointBase database are not case sensitive and
can be up to 128 characters in length.
ON Use the ON keyword between the index_name and the
table_name.
table_name The table_name refers to a table in the PointBase database. The
table_name must refer to a table that has already been created at
the time the CREATE INDEX statement executes.
Not allowed on a view. PointBase raises an error if you attempt
to use a view.
column_name The column_name identifies a column in the table named in the
table_name of the CREATE TABLE statement. There can be any
number of columns. Total maximum length of all columns in an
index must not exceed the pagesize.
[sort-order] This optional clause specifies the sorting order of the column or
columns in the index. The acceptable values for the ordering
keyword are ASC or ASCENDING for columns that sort from
the lowest value to the highest value in the column, and DESC or
DESCENDING for columns that sort from the highest value to
the lowest value in the column. Each column-name can only have
one ordering keyword. If you do not include an ordering
keyword, the sort order is ASCENDING.

PointBase
Version 4.8 PointBase Developer 137
Example1
This creates an index:
CREATE INDEX ORDER_IND
ON ORDER_TBL (ORDER_NUM DESC, CUSTOMER_NUM ASC);
Example2
This creates an index with a pagesize of 2K:
CREATE UNIQUE INDEX INDEX1
ON SALES_TBL
(CUSTOMER_NUM, SALES_DATE, PRODUCT_NUM)
INDEX PAGESIZE 2K;
CREATE FUNCTION
CREATE FUNCTION function_name([parameter_definition [{,parameter_definition}...]])
RETURNS return_clause
LANGUAGE JAVA
SPECIFIC specific_name
sql_data_access
EXTERNAL NAME external_function
PARAMETER STYLE SQL
Using a stored function, you can automatically convert data to be stored in a PointBase
database, without ever seeing the underlying conversion.
INDEX PAGESIZE Use the INDEX PAGESIZE keywords between the sort_order
and the size.
size The index size identifies the number of digits, KB, or MB
reserved for the index. Size can be:
• a number, such as 1024
• KiloBytes, such as 1K
The index page size should be less than or equal to 32KB and the
minimum is 1 KB. The default pagesize is 4KB unless a specific
size has been set in the pointbase.ini file.

PointBase
Version 4.8 PointBase Developer 138
Syntax
Function_name Function_name defines a stored function in a schema. The
following are usage rules.
• Including a schema name is optional. The following syntax
is for function_name:
[schema_name.]function_name
• It must be composed of alphanumeric characters or the
equivalent in another language, for example, Japanese
characters.
• It has a maximum limit of 128 characters long.
• It is not case sensitive.
• It cannot have the same name as a PointBase keyword.
• It must be unique in the schema specified.
Parameter_definition The parameter_definition specifies the parameter_mode,
parameter_name, and parameter_data_type. (The
parameter_name is optional.) The parameter_mode must be the
value, IN. The parameter_data_type must be one of the
PointBase data types. Separate multiple parameter_definitions
with a comma. The following syntax is for
parameter_definitions.
IN [parameter_name] PointBase_data_type
RETURNS
return_clause
This clause specifies the return data type in a stored function.
The data_type must be one of the PointBase data types.
The return_clause allows the following syntax: <PointBase data
types> or TABLE (pointbase_data_type
[{,pointbase_data_type}...]), or
<return_type> CAST FROM <original_return_type>, where you
cast the <original_return_type> from the Java function to the
new type, <return_type>.
NOTE: RETURNS return_clause is used with stored functions
only. Stored procedures do not use it.
LANGUAGE JAVA The clause specifies the language that the stored function uses to
call the external function. It can take the following value: JAVA.

PointBase
Version 4.8 PointBase Developer 139
Example
CREATE FUNCTION dateConvert( IN P1 VARCHAR(20) )
RETURNS Date
LANGUAGE Java
NO SQL
EXTERNAL NAME "SampleExternalMethods::dateConvert"
PARAMETER STYLE SQL;
NOTE: See the “PointBase JDBC Advanced Tutorial” chapter in this guide for more
information about functions in PointBase.
SPECIFIC
specific_name
The SPECIFIC specific_name clause specifies a name that you
can use instead of the function_name when invoking a stored
function. The specific_name must be unique within its schema. If
a specific_name is specified, then routine determination is not
used. Routine determination is the process that determines which
function to invoke based on the function_name, SQL argument
list, and the current path of schemas. Refer to the “Search
Conditions and Predicates” chapter for more information on
routine determination.
Sql_data_access This clause indicates the usage of SQL statements within the
external function of a stored function. Table 1 describes the
values that the sql_data_access clause allows.
EXTERNAL NAME
external function
The EXTERNAL NAME specifies an external function. The
external function must be static, or the class the function is in
must define a constructor that takes a “java.sql.Connection”
object. If it is static, it is called directly, no instance of the class
will be created hence no connection object will be established in
the procedure.
PARAMETER STYLE
SQL
This clause represents the parameters being passed according to
SQL rules rather than a host language.
Table 1: Sql_data_access Values
Value Description
NO SQL It signifies that the external function cannot contain any SQL
statements.
CONTAINS SQL It specifies that the external function can contain SQL statements
but none that read or modify data.
READS SQL DATA It specifies that the external function can contain any SQL statement
that does not modify SQL data.
MODIFIES SQL DATA It specifies that the external function can contain any SQL statement
that is not a DDL or Transaction Control statement

PointBase
Version 4.8 PointBase Developer 140

PointBase
Version 4.8 PointBase Developer 141
CREATE PROCEDURE
CREATE PROCEDURE procedure_name([parameter_definition [{,parameter_definition}...]])
LANGUAGE JAVA
SPECIFIC specific_name
sql_data_access
EXTERNAL NAME external_procedure
PARAMETER STYLE SQL
[REENTRANT|NON_REENTRANT]
Using a stored procedure you can return data from a database to a user interface. When the
database system returns the data, it is automatically converted from the original value into a
user-defined data type value.
Syntax
Procedure_name Procedure_name defines a stored procedure in a schema. The
following are usage rules.
• Including a schema name is optional. The following syntax
is for procedure_name:
[schema_name.]procedure_name
• It must be composed of alphanumeric characters or the
equivalent in another language, for example, Japanese
characters.
• It has a maximum limit of 128 characters long.
• It is not case sensitive.
• It cannot have the same name as a PointBase keyword.
• It must be unique in the schema specified.
Parameter_definition The parameter_definition specifies the parameter_mode,
parameter_name, and parameter_data_type. (The
parameter_name is optional.) The parameter_mode can be the
values, IN, OUT, or INOUT. The parameter_data_type must be
one of the PointBase data types. Separate multiple
parameter_definitions with a comma. The following syntax is for
parameter_definitions.
IN [parameter_name] PointBase_data_type
LANGUAGE JAVA The clause specifies the language that the stored procedure uses
to call the external procedure. It can take the following value:
JAVA.

PointBase
Version 4.8 PointBase Developer 142
SPECIFIC
specific_name
The SPECIFIC specific_name clause specifies a name that you
can use instead of the procedure_name when invoking a stored
procedure. The specific_name must be unique within its schema.
If a specific_name is specified, then routine determination is not
used. Routine determination is the process that determines which
procedure to invoke based on the procedure_name, SQL
argument list, and the current path of schemas. Refer to the
“Search Conditions and Predicates” chapter for more information
on routine determination.
Sql_data_access This clause indicates the usage of SQL statements within the
external procedure of a stored procedure. Table 2 describes the
values that the sql_data_access clause allows.
EXTERNAL NAME
external procedure
The EXTERNAL NAME specifies an external procedure. The
external procedure must be static, or the class the procedure is in
must define a constructor that takes a “java.sql.Connection”
object.
PARAMETER STYLE
SQL
This clause represents the parameters being passed according to
SQL rules rather than a host language.
REENTRANT |
NON_REENTRANT
This parameter specifies this procedure to be reentrant or non-
reentrant.
Default is non-reentrant.
Reentrant procedure allows user to reuse external procedure
instances without recreating instances every time the procedure
is called, hence it has better performance than non-reentrant
procedures. PointBase creates only one external procedure
instance for each external procedure called in each connection.
This procedure instance is reused next time the same procedure
is called in the same connection. Since the procedure instance is
reused, values of object members may remain the same value as
last run. User is responsible to re-initialize them if necessary.
Non-reentrant, the default, procedure will create external
procedure instance every time it is called. Members of this
instance will be their default value because this is a new instance
every time.
User may also make the procedure to be static. Static procedures
will be called without creating an external procedure instance.
But, for static procedure, user will not be able to associate
connection object with procedures, which mean it may not be
able to perform database operation in the same connection as
caller. But, if same connection is not a requirement for this
procedure, static procedure performs better than reentrant and
non-reentrant procedures.

PointBase
Version 4.8 PointBase Developer 143
Example 1
CREATE PROCEDURE getCost( IN P1 VARCHAR(20), IN P2 VARCHAR(2), INOUT P3 FLOAT )
LANGUAGE JAVA
SPECIFIC getCost
NO SQL
EXTERNAL NAME "SampleExternalMethods::getCost"
PARAMETER STYLE SQL;
Example 2
CREATE PROCEDURE getCost( IN P1 VARCHAR(20), IN P2 VARCHAR(2), INOUT P3 FLOAT )
LANGUAGE JAVA
SPECIFIC getCost
NO SQL
EXTERNAL NAME "SampleExternalMethods::getCost"
PARAMETER STYLE SQL
REENTRANT;
Example 3
This example shows a non-reentrant procedure. In this procedure, m_Timestamp is
initialized in constructor, reentrant procedure calls construct the first time it is
called, so m_Timestamp will not be reset every time it is called.
Public class Proc1 {
private Connection m_Con;
private longm_TimeStamp;
public Proc1 ( Connection p_Con ) {
m_Con = p_Con;
m_TimeStamp = System.currentTimeMillis();
}
public void log( String p_Msg ) {
PreparedStatement ps = m_Con.prepareStatement(
"insert into Log values (?,?)" );
ps.setLong( 1, m_TimeStamp );
ps.setString( 2, p_Msg );
ps.execute();
}
}
Table 2: Sql_data_access Values
Value Description
NO SQL It signifies that the external procedure cannot contain any SQL
statements.
CONTAINS SQL It specifies that the external procedure can contain SQL statements
but none that read or modify data.
READS SQL DATA It specifies that the external procedure can contain any SQL
statement that does not modify SQL data.
MODIFIES SQL DATA It specifies that the external procedure can contain any SQL
statement that is not a DDL or Transaction Control statement

PointBase
Version 4.8 PointBase Developer 144
Example 4
By moving m_Timestamp from example 3 to be a local variable in methd log(), this
procedure can be made to be reentrant.
Public class Proc1 {
private Connection m_Con;
public Proc1 ( Connection p_Con ) {
m_Con = p_Con;
}
public void log( String p_Msg ) {
long l_TimeStamp = System.currentTimeMillis();
PreparedStatement ps = m_Con.prepareStatement(
"insert into Log values (?,?)" );
ps.setLong( 1, l_TimeStamp );
ps.setString( 2, p_Msg );
ps.execute();
}
}
NOTE: See the “PointBase JDBC Advanced Tutorial” chapter in this guide for more
information about stored procedures in PointBase.
CREATE TRIGGER
CREATE TRIGGER <trigger name>
<trigger action time> <trigger event>
ON <table name>
[ REFERENCING <referencing clause> ]
<trigger action>
A trigger can specify additional constraints and business rules within the database to manage
the various executions of an application. A trigger operates automatically by executing or
firing a DELETE, INSERT, or UPDATE SQL statement on a table with which the trigger is
associated. The trigger definitions are saved in the SYSTRIGGERS and
SYSTRIGGERCOLUMNS system catalogs.
Please note that SQL triggers are not automatically upgraded to version 4.3 or later. If there are
triggers defined in your PointBase Embedded 4.2 database or prior to version 4.2, you must
drop all triggers manually, upgrade to version 4.3 or later, and then manually recreate the
triggers. The procedure is as follows:
1. Start the database using 4.2 JAR or earlier versions.
2. Drop all triggers by browsing through the table, POINTBASE.SYSTRIGGERS, and drop
all triggers in this table.
DROP trigger_name.
3. Stop the database.
4. Start the database using 4.3 JAR (or later).
5. Recreate triggers.

PointBase
Version 4.8 PointBase Developer 145
Syntax
CREATE TRIGGER
<trigger_name>
The CREATE TRIGGER keywords are required when creating a
trigger. <Trigger_name> defines a unique trigger in a database
schema. To drop a trigger from a table, you must use the
trigger_name.
Usage Rules for <trigger_names>:
• Including a schema name is optional. The following syntax
is for trigger_name:
[schema_name.]trigger_name
• It must be composed of alphanumeric characters or the
equivalent in a language other than English.
• It has a maximum limit of 128 characters long.
• It is not case sensitive.
• It cannot have the same name as a PointBase keyword.
• It must be unique in the schema specified.
<trigger action time> ::=
BEFORE | AFTER
<Trigger_action_time> signifies when the trigger can be fired or
executed relative to the <trigger event>. It takes one of the
following values: BEFORE or AFTER.
If you specify BEFORE as the <trigger_action_time>, the SQL
statements defined in the <triggered SQL statement> cannot
directly or indirectly modify SQL data by invoking a stored
function or procedure.
BEFORE trigger is executed prior to any change made to the
row. The BEFORE trigger will be executed once for every
change made to the row for ROW trigger and once for every
SQL statement for STATEMENT trigger.
If BEFORE is specified, <trigger SQL statement> should not
contain any data modification statements or statements that
invoke a procedure or function which is an SQL-invoked
procedure or function that possibly modifies SQL data. If this is
violated, the result is unknown.
PointBase does not support cascading BEFORE triggers.
If you specify AFTER for the <trigger action time>, PointBase
executes the trigger after changes have been made to the row.
The AFTER trigger will be executed once for every change made
to the row for ROW trigger and once for every SQL statement
for STATEMENT trigger.

PointBase
Version 4.8 PointBase Developer 146
<trigger_event> ::= INSERT |
DELETE | UPDATE [ OF
<trigger column list> ]
<trigger column list> ::=
<column name list>
It allows you to specify events which cause triggers to fire. These
events can be INSERT, UPDATE or DELETE. Only one event
can be defined in one trigger. If you specify INSERT, then only
an INSERT operation will cause the trigger to fire. The same is
true for UPDATE and DELETE. The trigger can be fired by an
INSERT, UPDATE or DELETE SQL statement or by a
referential integrity constraint.
If you specify UPDATE, you may also specify an optional
column list. If this column list is present, the trigger fires only
when one of those columns specified in the column list is
updated. Otherwise, if not column list is present, any column
updated will cause the trigger to be fired.
ON <table_name> <Table_name> specifies the name of the table to which the
trigger belongs. A table is allowed to have multiple triggers. If
more than one trigger is associated with a table, the triggers are
executed in ascending order of their creation timestamps.
Not allowed on a view. PointBase raises an error if you attempt
this on a view.

PointBase
Version 4.8 PointBase Developer 147
REFERENCING
<referencing_clause>
<referencing_clause> ::= <old
or new value aliases>...
<old or new value aliases> ::=
OLD [ ROW ] [ AS ] <old values
correlation name> | NEW [ ROW
] [ AS ] <new values correlation
name> | OLD TABLE [ AS ] <old
values table alias> | NEW
TABLE [ AS ] <new values table
alias>
<old values table alias> ::=
<identifier>
<new values table alias> ::=
<identifier>
<old values correlation name>
::= <correlation name>
<new values correlation name>
::= <correlation name>
This clause allows you to specify aliases for new or old rows and
new or old tables. NEW [ROW] [AS] are keywords that specify
the current row on which the triggering SQL statement is
modifying and the columns of the current row contains the
changes made by the triggering SQL statement. Conversely,
OLD [ROW] [AS] are keywords that specify the current row
whose columns contain the original value.
PointBase creates two transition tables during the execution of
triggers: one for new rows and another for old rows. A transition
table is a temporary table where the new values and old values of
the row are stored. PointBase destroys these new tables once the
triggering SQL statement is completed.
NEW or OLD TABLE aliases are the aliases referencing the two
transition tables. The NEW TABLE alias is referencing the
transition table containing new rows, and the OLD TABLE alias
is referencing the transition table containing old rows. OLD or
NEW TABLE will be supported only for STATEMENT triggers.
These aliases cannot be passed as parameters to call statements.
The scope of <referencing_clause> is the entire CREATE
TRIGGER statement.
If <trigger event> specifies INSERT, neither OLD ROW nor
OLD TABLE will be allowed.
If <trigger event> specifies DELETE, neither NEW ROW nor
NEW TABLE will be allowed.
If BEFORE is specified for the <trigger action time>, neither
OLD TABLE nor NEW TABLE will be allowed.
If FOR EACH STATEMENT is specified for the <trigger
action>, neither OLD ROW nor NEW ROW will be allowed.
If <trigger event> specifies UPDATE, NEW ROW values will
be null for those columns which do not have new values.
If no row or table alias is specified, you may not refer to the
current row or the transition table. There is no default alias.

PointBase
Version 4.8 PointBase Developer 148
<trigger action> ::=
[ FOR EACH { ROW |
STATEMENT } ]
[ WHEN (<search condition> )]
<triggered SQL statement>
<triggered SQL statement> ::=
<SQL procedure statement> |
BEGIN ATOMIC { <SQL
procedure
statement><semicolon> }...
END
<Trigger action> allows you to specify ROW trigger or
STATEMENT trigger. If you specify a ROW trigger, PointBase
fires the trigger once for each row on which the defined <trigger
event> occurs. A STATEMENT trigger will be fired once for
each SQL statement on which causes the defined trigger event to
occur.
ROW triggers may not work on self-referencing tables. In this
case, referential constraint may go into recursion and may lead to
a wrong row value while executing triggers.
If you do not specify a STATEMENT or ROW trigger, PointBase
uses the STATEMENT trigger for the default.
<Trigger action> allows you to specify a WHEN clause which
defines the search condition to evaluate if the trigger will fire.
You can define one or more predicates. If these predicates are
evaluated TRUE, then the trigger will be fired; otherwise, it will
not be fired.
<Triggered SQL statement> allows you to specify the action for
the trigger. You can specify one SQL statement or, a compound
SQL statement embraced by the BEGIN ATOMIC and END
keywords. The size of each SQL statement is limited to 900
bytes. See trigger-related SQL statements: SET assignment,
VALUE, and SIGNAL on page 182.
No transaction control statements are allowed for the <triggered
SQL statement>. (Transaction control statements include
commit, rollback, savepoint, etc. See section Transaction Control
in Appendix A in this guide for further details on transaction
control statements.) If you violate this rule, PointBase throws an
error. If an error occurs during the execution of <triggered SQL
statement>, PointBase throws an error and the execution of the
<triggering SQL statement> is interrupted, and all the changes
are rolled back.
Since <triggered SQL statement> can contain any SQL
statement, it is possible that an INSERT, UDPATE or DELETE
SQL statement could cause the same trigger to be executed
again. This is called a recursive trigger. PointBase allows
recursive triggers. But, you should avoid writing recursive
triggers, because they can lead to infinite loops.
It is possible for recursive triggers to modify the same row
multiple times. In this case, the latest row value or new row value
may be seen in the subsequent trigger execution.
PointBase sets a limit of 16 levels for recursive trigger execution
context. For example, if one trigger is fired, it is counted as level
one, if this trigger causes another trigger to be fired before it is
finished, the second trigger is counted as level two, and so on. An
exception will be thrown if trigger level exceeds the limit.

PointBase
Version 4.8 PointBase Developer 149
Security
PointBase checks authorization at the trigger creation time. If a trigger is successfully created,
security will not be checked again at trigger execution time. For example, User A must have
creation privilege on the schema to which the trigger belongs; that is, User A must have trigger
privilege on table (T1), and UDPATE privilege on table (T2). Then User A can create a trigger
(TR1) on T1, where TR1 is a ROW trigger specifying an UPDATE event and is updating rows
on T2. User B has UDPATE privilege on T1, but does not have UPDATE privilege on T2.
While User B is doing updates on T1, TR1 will be invoked and UPDATE rows on T2. User B’s
privilege will not be used to check against T2 while executing TR1.
Examples
To use all of the following trigger examples, you must complete the following:
• Include the SampleExternalMethods.class file in your CLASSPATH when you connect
to PointBase.
• Follow the prompts to create a new database called “sample.”
•Type run sample.sql; You must type the complete path to the “sample.sql” file
located in the directory “<install directory>\samples\server_embedded,” for example,
run c:/pointbase/samples/server_embedded/sample.sql;
Example 1
CREATE TRIGGER trigger2
BEFORE UPDATE ON product_tbl
REFERENCING NEW AS NEWROW
FOR EACH ROW
WHEN (NEWROW.qty_on_hand < 0)
SET NEWROW.qty_on_hand = 0;
CREATE TRIGGER trigger3
BEFORE UPDATE ON product_tbl
REFERENCING NEW AS NEWROW
FOR EACH ROW
WHEN (NEWROW.purchase_cost < 0)
SIGNAL ’Products prices cannot be negative’
CREATE TRIGGER trigger4
AFTER UPDATE ON product_tbl
REFERENCING NEW AS NEWROW
FOR EACH ROW
WHEN (NEWROW.qty_on_hand > 100)
VALUES(showQuantity(’You have increased the quantity above’, 100));

PointBase
Version 4.8 PointBase Developer 150
Example 2
Step 1.
CREATE PROCEDURE showTime (IN p1 VARCHAR(30), IN P2 TIMESTAMP)
LANGUAGE JAVA
NO SQL
EXTERNAL NAME "SampleExternalMethods::showTime";
Step 2.
CREATE TRIGGER trigger1
AFTER INSERT ON discount_code_tbl
FOR EACH ROW
CALL showTime(’New discount code inserted’ , CURRENT_TIMESTAMP);

PointBase
Version 4.8 PointBase Developer 151
ALTER TABLE
ALTER TABLE table_name alter_table_action [{,alter_table_action},...]
The ALTER TABLE statement modifies the structure of a table in the PointBase database.
With this statement, constraints or columns may be added or dropped. A table may also be
renamed with ALTER TABLE.
Syntax
Alter_Table_Action Syntax
ADD table_constraint_definition
| DROP CONSTRAINT constraint_name [CASCADE | RESTRICT]
| ADD [COLUMN] column_definition
| DROP [COLUMN] column_name [CASCADE | RESTRICT]
| RENAME TO <new_table_name>
ALTER TABLE The ALTER TABLE keywords are required as the first words in
an ALTER TABLE statement.
table_name The table_name variable must be the name of an existing table in
a PointBase database. The ALTER TABLE statement generates
an error if the value of the table_name does not exist.
alter_table_action The action allows adding or dropping a constraint or column. See
the following section for the alter_table_action syntax.
ADD
table_constraint_definition
Adds a table constraint definition to the table. Not allowed on a
view. PointBase raises an error if you attempt this on a view. If
the constraint is a referential constraint that references a view, an
error will be raised.
DROP CONSTRAINT
constraint_name
Drops an existing named constraint from the table. The system
automatically provides a name for the constraint if none was
specified when it was added. The constraint name can be found
in the table SysTableConstraint.
ADD [COLUMN]
column_definition
Adds a column to the end of the column_definition for the table.
(See column_definition on page 123.) The default value is NULL,
unless declared NOT NULL with an assigned default value. This
will only affect columns that you create after the default value is
assigned.
Not allowed on a view. PointBase raises an error if you attempt
this on a view.

PointBase
Version 4.8 PointBase Developer 152
DROP [COLUMN]
column_name
Drops one or multiple existing named column(s) from the table.
Not allowed on a view. PointBase raises an error if you attempt
this on a view. If the table_name + column_name is in the system
catalog, SysViewTables, then either an error will be raised (if
RESTRICT) or all dependent views will be dropped (if
CASCADE).
[CASCADE/RESTRICT] The optional RESTRICT qualifier to a DROP statement allows a
drop only if no objects are dependent on the column or constraint.
The optional CASCADE qualifier to a DROP statement drops all
related objects to the column or constraint.
RENAME TO
<new_table_name>
Renames the current table to the new_table_name. The following
are the restrictions for RENAME clause of ALTER TABLE.
- Only Schema owner or a user who has DBA level authority can
perform rename table operation.
- The rename table operation in ALTER TABLE can not be
combined with other operations in the ALTER TABLE statement.
- A table can only be renamed within same Schema and can not
be moved to another schema.
- If there are Views or Triggers defined on the table, then rename
table operation is not allowed.
- Pointbase automatically transfers all constraints, indexes and
grants on the old table to the new table.
- The behavior of objects such as Stored Procedures, Functions
etc. that depend on or refer to old table by name is undefined. If
the old table does not exist then they will get a syntax error. If a
new table with the old name is created then these objects will refer
to newly created table and if the new definition of the table is
compatible with the definition of these objects then they will
continue to work. If the new definition of the table is incompatible
with these objects then they will get errors.
- PointBase system generated constraint names and index names
will be changed to reflect the new table name. This allows the old
table name to be reused.
- Views can not be renamed using rename clause.
- Temp Tables can not be renamed using rename clause.
- When a table is renamed, already compiled PreparedStatements
and cached Statements that refer to the renamed table will detect
this when they are executed next time and throw an exception if
the table does not exist.

PointBase
Version 4.8 PointBase Developer 153
Examples
ALTER TABLE T2 ADD UNIQUE (C1);
ALTER TABLE T2 ADD ORDER_NUM INT;
ALTER TABLE T2 ADD CONSTRAINT constraint_0 FOREIGN KEY (C1) REFERENCES T1 (C1);
ALTER TABLE T2 ADD CONSTRAINT constraint_1 PRIMARY KEY (C1,C2);
ALTER TABLE T2 DROP ORDER_NUM CASCADE;
ALTER TABLE T2 RENAME TO T1;
ALTER USER
ALTER USER user_name {PASSWORD password | DEFAULT ROLE role_name}
To change the password or default role of a database user, you must use the non-standard SQL
command, ALTER USER. It can only be used by the following types of users:
•PBSYSADMIN
• Any user whose current role is the PBDBA role
• Owner of database (i.e. the user who created the database)
You may also use ALTER USER to change your own password or default role.
Note: See the description for CREATE USER for information about the behavior of usernames
and passwords.
Syntax
ALTER USER
user_name
The user_name specifies the name of the user, for whom you will
change the password or default role.
PASSWORD password The password defines the new password for the specified user.
DEFAULT ROLE
role_name
The role_name defines the new default role for the specified user.

PointBase
Version 4.8 PointBase Developer 154
Examples
ALTER USER Scott PASSWORD lion;
ALTER USER Scott DEFAULT ROLE CEO;

PointBase
Version 4.8 PointBase Developer 155
Dropping SQL Objects
The following sections describes how to drop SQL objects in PointBase:
• “DROP INDEX”
• “DROP FUNCTION or DROP PROCEDURE”
• “DROP SCHEMA”
• “DROP TABLE”
• “DROP VIEW”
• “DROP TRIGGER”
• “DROP USER”
Drop Behavior (Optional)
Side effects can occur when an SQL object is dropped. For example, if a table is dropped, what
becomes of an index that is based on that table? SQL allows you to specify the drop behavior.
To do this, specify either: CASCADE or RESTRICT. The syntax for drop_behavior is as
follows:
CASCADE | RESTRICT
You may specify one or the other. CASCADE has the effect of dropping all SQL objects that
are dependent on that object. RESTRICT is the default for the drop behavior. RESTRICT
looks to see what objects are dependent on the object being dropped. If there are dependent
objects, then the dropping of the object does not occur.
DROP INDEX
DROP INDEX table_name.index_name
The DROP INDEX statement deletes an index structure of a table from the PointBase
database.
Syntax
DROP INDEX The DROP INDEX keyword is required at the beginning of a
DROP INDEX statement.
table_name.index_name The index_name must be the name of an existing index in a
PointBase database. The index_name must be qualified with the
name of the table that the index is on, as in
table_name.index_name. The DROP INDEX statement raises an
error if the value of the index_name does not exist.

PointBase
Version 4.8 PointBase Developer 156
Examples
DROP INDEX ORDER_TBL.ORDER;
DROP FUNCTION or DROP PROCEDURE
DROP { SPECIFIC routine_type specific_routine_name}
| {routine_type routine_name [parameter_data_type_list])}
[drop_behavior]
The DROP ROUTINE statement destroys a routine in a schema of a PointBase database.
Syntax
Examples
DROP FUNCTION ORDERS_TOTAL (char(10), int) CASCADE;
DROP The DROP keyword is required as the first word in a DROP
ROUTINE statement. The SPECIFIC clause refers to a specific
function that shares the same name with other functions.
specific_routine_name must be unique in the database.
specific_routine_name The specific_routine_name that was specified when the function
or procedure was defined.
routine_type FUNCTION | PROCEDURE | ROUTINE
routine_name The name of the SQL function or procedure.
parameter_data_type_list The optional parameter_list clause specifies selection criteria for
a DROP statement. Only SQL data types are specified. No
parameter mode or name is allowed.
drop_behavior If RESTRICT is specified, then if there are any other SQL
routines, or constraints, then the routine is not dropped and
neither are the other SQL routines, triggers, nor constraints.
With CASCADE, all SQL objects (other SQL routines, and
constraints) that use the SQL routine are dropped as well as the
SQL routine. RESTRICT is the default.

PointBase
Version 4.8 PointBase Developer 157
DROP SCHEMA
DROP SCHEMA schema_name [drop_behavior]
The DROP schema statement destroys a schema in the PointBase database.
Syntax
Examples
DROP SCHEMA ORDERS CASCADE;
DROP TABLE
DROP TABLE table_name [drop_behavior]
The DROP TABLE statement destroys a table in the PointBase database.
DROP SCHEMA The DROP SCHEMA keywords are required as the first words in
a DROP SCHEMA statement.
schema_name The name of the schema. If the schema contains any views, than
either PointBase raises an error (if RESTRICT) or drops all
views (if CASCADE).
drop_behavior If RESTRICT is specified, then if there are any tables or SQL
routines in schema_name, then the schema is not dropped and
neither are the tables, nor the SQL routines.
With CASCADE, all tables, indexes, columns, constraints,
triggers, and SQL routines that are associated with schema_name
are dropped as well as the schema. RESTRICT is the default.

PointBase
Version 4.8 PointBase Developer 158
Syntax
Examples
DROP TABLE ORDER_TBL CASCADE;
DROP VIEW
DROP VIEW <view name> [ RESTRICT | CASCADE ]
This statement removes a specified view or viewed table from the PointBase database.
Notes
• The only objects that can be dependent on a view are other views.
DROP TABLE The DROP TABLE keywords are required as the first words in a
DROP TABLE statement.
table_name The table_name variable must be the name of an existing table in
a PointBase database. The DROP TABLE statement generates an
error if the value of the table_name does not exist.
If the table is in the system catalog, SysViewTables, then either
PointBase raises an error (if RESTRICT) or drops all dependent
views (if CASCADE).
drop_behavior If RESTRICT is specified, then if there are any table constraints,
or SQL routines that use table_name, then the table is not
dropped and neither are the table constraints nor the SQL
routines.
With CASCADE, all indexes, columns, constraints, triggers, and
SQL routines that are associated with table_name are dropped as
well as the table. RESTRICT is the default.

PointBase
Version 4.8 PointBase Developer 159
Syntax
Examples
DROP VIEW customer_order cascade;
DROP VIEW customer_order restrict;
DROP TRIGGER
DROP TRIGGER trigger_name
The DROP TRIGGER statement deletes a trigger structure from the PointBase database.
Syntax
DROP VIEW The DROP VIEW keywords are required as the first words in a
DROP VIEW statement.
view name The view name variable must be the name of an existing view in
the PointBase database.
RESTRICT |
CASCADE
RESTRICT verifies if there are any dependent views. If other
views depend on this view, an error is raised and this view is not
dropped.
CASCADE does not verify if there are any dependent views.
This view is dropped as well as all dependent views.
DROP TRIGGER The DROP TRIGGER keywords are required as the first words
in a DROP TRIGGER statement.
trigger_name The trigger_name is a two-part name which includes the name of
the schema. The trigger name must be composed of
alphanumeric characters or the equivalent in another language,
for example, a word in Japanese characters and cannot be the
same as a PointBase keyword. Trigger names in the PointBase
database are not case sensitive and can be up to 128 characters
long. They must be unique in their schema.

PointBase
Version 4.8 PointBase Developer 160
Examples
DROP TRIGGER TRG1;
DROP USER
DROP USER user_name [drop_behavior]
The DROP USER statement deletes a user object from the PointBase database. To successfully
execute this command, the current user must be the PBSYSADMIN or the database owner.
[See "Predefined Users" on page 103.] Or, the current role must be PBDBA. [See "Predefined
Roles" on page 107.] You cannot drop the predefined users: PBPUBLIC or
PBSYSADMIN. Additionally, you cannot create nor drop the user PUBLIC.
Syntax
Examples
DROP USER ENGINEERING_MANAGER CASCADE;
DROP ROLE
PointBase supports this statement. Please refer to the section, "DROP ROLE Syntax" on page
110.
DROP USER The DROP USER keyword is required at the beginning of a
DROP USER statement.
user_name The user_name must be the name of an existing user in
PointBase database. The DROP USER statement raises an error
if the value of the user_name does not exist.
drop_behavior If RESTRICT is specified and if any schemas have user_name
specified, the system does not drop the user and the schema.
With CASCADE, the system drops all schemas that have
user_name as the owner, in addition to dropping the user_name.
RESTRICT is the default.

PointBase
Version 4.8 PointBase Developer 161
Data Query Language and
Data Manipulation Language
To retrieve, INSERT, DELETE and modify data in PointBase, use the Data Query Language
(DQL) and Data Manipulation Language (DML). DQL and DML allows an application to do
the following:
• SELECT: Retrieve rows of data.
• INSERT: Place new rows of data in the database.
• UPDATE: Replace existing values in the database with new values.
• DELETE: Delete rows of data in the database.

PointBase
Version 4.8 PointBase Developer 162
SELECT
SELECT [ DISTINCT ] column_list [ AS alias_name ]
FROM table_expression
[WHERE search conditions]
[GROUP BY column_list ]
[HAVING search_condition ]
[ORDER BY {column_name | value} [sort_order]]
[FOR UPDATE [OF column-list] [WAIT|NOWAIT]]
The SELECT statement retrieves data from the PointBase database.
Syntax
SELECT [DISTINCT] The SELECT keyword is required as the first word in a SELECT
statement.
The DISTINCT keyword is optional. When specified, the
distinct function eliminates duplicate occurrences of the same
row (not columns) and returns only distinct values. The
DISTINCT keyword can only be used once in a query.
column_list The column_list can be a string of comma-separated column
names or expressions, or the wild card character (*). If a column
name exists in more than one of the tables in the SELECT
statement, a table name or correlation name must be used to
qualify the column name. You can use a function that returns a
single value for each row in the column listing of a SELECT
statement.
AS alias_name An alias_name is a means of giving a different name to an
element in a column_list that applies individually to the item for
which it serves as an alias. Each item in the column_list may
have its own alias_name.
FROM The FROM keyword is required in a SELECT statement between
the select-expression and the table-expression.

PointBase
Version 4.8 PointBase Developer 163
table_expression The table_expression contains all the information needed to
specify the tables in a SELECT statement and the relationship
between multiple tables in the statement. The table_expression
takes the syntax of:
table_expression::=
table_name_exp
| derived_table
| table_name joined_table_exp
[join_table_exp...]
where:
table_name_exp::= table_name [ [AS]
correlation_name]
derived_table::= subquery
subquery::= <left paren><query expression>right
paren>
joined_table_exp::= join_type table_name_exp
[ON_clause | USING_clause]
and the ON_clause or USING_clause are known as the join
specification:
ON_clause::= ON search_condition
USING_clause::= USING (column_name_list)
The table_expression can contain any number of table_names. It
does not require you to give any specific ordering of the
table_names. The optimizer will determine the appropriate
ordering of execution. For more on the optimizer, see
“Optimizing Query Expressions” in the PointBase System Guide.
table_name The names represented by table_name are the names of the
tables that should be accessed. If you join more than one table in
the SELECT statement, separate the table names with commas.
NOTE: If more than one table is specified in the table list, then it
is known as a join. PointBase supports CROSS, INNER,
and LEFT and RIGHT OUTER joins.
[AS]
correlation_name
A correlation name is a means of giving a different name to a
table that qualifies the names of columns in the SELECT
statement. A correlation name is sometimes used to document
the source of columns even when there are not duplicate column
names. It is not required to provide a correlation name for every
table in a SELECT statement.
derived_table The derived table is a temporary table generated dynamically
from a subquery.. If derived table is used, correlation name for
the derived table must be supplied. If column list contains
expressions or duplicate column names, correlation names for
those columns must be supplied.
ON_clause With the ON_clause, you can specify a search_condition when
joining two tables. The effect of the ON_clause is the Cartesian
product of the two tables that meet the search_condition criteria.

PointBase
Version 4.8 PointBase Developer 164
USING The USING_clause can only be used if each joining table has the
same column names as the other joining table. For example, if
we have:
USING (C1, C2)
the effect of the USING_clause is an ON_clause of the following
(if we are joining tables T1 and T2):
ON T1.C1=T2.C1 AND T1.C2=T2.C2
WHERE search
conditions
The WHERE clause is an optional clause that specifies selection
criteria for a query. The search condition(s) that follow the
WHERE keyword evaluates each row that could be included in
the result set. [You may use a subquery as part of the search
condition. See “Subqueries” in this section for more
information.]
If the search conditions returns false for a row, the row is not
included in the result set; if the search conditions returns true, the
row is included in the result set. If a WHERE clause is not
specified, then all rows of the table(s) are included in the result
set.
For more information on search conditions, see the chapter,
“Search Conditions and Predicates.”
GROUP BY
column_list
The format of the Group-By clause is:
GROUP BY grouping column [ , grouping-column
]...
Grouping-column is a column-reference.
The result of a group-by-clause is a virtual table, but that result is
called a grouped table. The input table is partitioned into one or
more groups; the number of groups is the minimum such that, for
each grouping -column, no two rows of any group have different
values for that grouping – column. For any group in the resulting
grouped table, every row in the group has the same value for the
grouping - column. Otherwise, the group- by - clause produces
an output table that is identical to the input table.
HAVING
search_condition
The having-clause is a filter. The filtering operation is applied to
the grouped table resulting from the preceding clause. If there is
a group-by-clause, the grouped table resulting from it is the input
to the having-clause. If there is no group-by-clause, the entire
table resulting from the where-clause is treated as a grouped
table with exactly one group. In this case, there is no grouping-
column. The format of the having-clause is:
HAVING search-condition
The search-condition is applied to each group of the grouped
table. That's because the only columns of the input table that the
having-clause can reference are the grouping columns, unless the
columns are used in a set function.

PointBase
Version 4.8 PointBase Developer 165
NOTE: The SELECT statement returns the qualified result set to the calling application. For
more information on how PointBase optimizes SELECT statements and the joins they
contain, see the chapter, “Optimizing Query Expressions” in the PointBase System
Guide.
ORDER BY
ORDER BY {column_name | value} [sort_order]
[{, column_name | value} [sort_order]...}]
The optional ORDER BY clause specifies the ordering of the
rows returned from a SELECT statement. An ORDER BY clause
can contain one or more column values, separated with commas;
functions are not allowed. If a column_name is specified in the
ORDER BY clause, then that column_name must also be
specified in the column_list.
Each column or value in the ORDER BY clause can include an
optional sort_order qualifier. Acceptable sort order qualifiers are
ASC, for ascending sort order, and DESC, for descending sort
order. If no sort order is specified, the default is ascending. If the
ORDER BY clause contains multiple columns, the order of the
columns designates the order of the grouping.
If a query contains any UNION operators, the ORDER BY clause
must be specified last after all the unions are specified.
FOR UPDATE The optional FOR UPDATE clause allows user to change
PointBase's default locking mechanism.
PointBase, by default, places share locks on rows returned from
select statement. SELECT FOR UPDATE will place exclusive
locks on rows returned from select statement. This guarantees the
subsequent modification on those rows without being blocked by
other users.
This option may cause deadlock situation, and should be used
with care and in short transaction only to avoid deadlock.
This clause can't be used in read uncommitted transactions.
FOR UPDATE can only be used in main select statement (not in
any subquery select statement.)
FOR UPDATE cannot be used conjunction with order by clause,
sort by clause, aggregation functions, views and temporary
tables.
OF column_list This clause specifies what table to be affected. Only tables
containing columns in column_list will be affected. If this clause
is not specified, all tables are affected.
WAIT | NOWAIT This clause specifies wait or no wait locks. In the case of rows
are locked by other user, select statement will return immediately
with lock wait timeout exception if nowait is specified, otherwise
it will wait until lock timeout specified in .ini parameter.

PointBase
Version 4.8 PointBase Developer 166
Examples
All of the following examples were created using the sample database that comes with every
database product.
Example 1
When querying a column that is not unique, the keyword DISTINCT will allow you eliminate
duplicate rows. The ORDER BY clause will sort one or more columns based on ascending or
descending sequences. By default the sort order is set to ascending sequence.
SELECT DISTINCT name FROM manufacture_tbl ORDER BY name DESC;
Results:
Note the use of a column alias for a similar query. (The result is deliberately truncated for
brevity in this example, but would be the same as the above.)
SELECT DISTINCT name AS company FROM manufacture_tbl ORDER BY name DESC;
Results:
NAME
Zetsoft
World Savings
Wells Fargo
Toshiba
Sony
SoftClip
Sams Publishing
Rico Enterprises
MicroSoft
Matrox
COMPANY
Zetsoft
World Savings
(etc....)

PointBase
Version 4.8 PointBase Developer 167
Example 2
It is possible to use an SQL constant that will help produce results that are easier to interpret.
The example below illustrates two variations of SQL constants. The first example ’Shipping
Cost' demonstrates a fixed column type and the second example ‘$’ is concatenated to a select
list. Also notice the comparison test that finds the all records that were charged over $300 in
shipping costs and not shipped to Florida.
SELECT order_num, sales_tax_st_cd, ’Shipping Cost’, ’$’ || shipping_cost FROM order_tbl
WHERE shipping_cost > 300 AND UPPER(sales_tax_st_cd) NOT LIKE ’%FL’ ORDER BY order_num
ASC;
Results:
Joins
Relational join operations are implemented through the basic SELECT...WHERE statement.
See SELECT for additional information. PointBase supports the following join operations:
•CROSS JOIN
• INNER JOIN
• OUTER JOIN
CROSS JOIN
The cross join operation performs a cross product on the joining tables.
SELECT *
FROM t1 CROSS JOIN t2
The cross join is the same type of join found in earlier versions of SQL. Those versions of SQL
that did not use the JOIN keyword, used a comma instead.
INNER JOIN
In inner joins, columns with the same names have compatible data types and the rows will be
selected only when every matching column has the same value as its data type.
SELECT *
FROM t1 INNER JOIN t2
ON t1.c1 = t2.c3;
ORDER_NUM SALES_TAX Shipping Cost '$' || shipping
10398002 TX Shipping Cost $359.99
10398009 CA Shipping Cost $700
20598101 MI Shipping Cost $2500
30198001 NY Shipping Cost $2000.99
30298004 NY Shipping Cost $700

PointBase
Version 4.8 PointBase Developer 168
INNER JOIN Example:
This example is joining common values from the sales_rep table and sales tax code table based
on a common type ‘decimal rate’. As you can see, it is returning all rows that have a common
rate and commission values. Also notice that the data is being filtered base on a tax code rate
that is over 7.0.
SELECT last_name, commission_rate, sales_tax_code_tbl.rate from sales_rep_tbl INNER JOIN
sales_tax_code_tbl ON (sales_rep_tbl.commission_rate = sales_tax_code_tbl.rate) AND
(sales_tax_code_tbl.rate > 7.0);
The SELECT statement returns the following:
OUTER JOIN
Outer join operations preserve unmatched rows from one or both tables, depending on the
keyword used. PointBase supports the following:
• LEFT OUTER JOIN
• RIGHT OUTER JOIN
LAST_NAME COMMISSION RATE
Longer 8 8
Hillerger 9 9
Smith 7.75 7.75
Smith 7.75 7.75
Smith 7.75 7.75
Smith 7.75 7.75
Donohue 7.75 7.75
Donohue 7.75 7.75
Donohue 7.75 7.75
Donohue 7.75 7.75

PointBase
Version 4.8 PointBase Developer 169
LEFT OUTER JOIN
The LEFT OUTER JOIN preserves unmatched rows from the left table, the one that precedes
the keyword JOIN
SELECT *
FROM t1 LEFT OUTER JOIN t2
ON t1.c1=t2.c3;
LEFT OUTER JOIN Example:
The example below is performing a Left Outer Join based on where the sales representative
commission rate and the sales tax code table’s rate are equal. Notice that all of the values in the
left table (sales_rep_tbl ) are preserved.
SELECT last_name, ytd_sales, commission_rate, sales_tax_code_tbl.rate FROM sales_rep_tbl
LEFT
OUTER JOIN sales_tax_code_tbl ON (sales_rep_tbl.commission_rate =
sales_tax_code_tbl.rate) AND (sales_tax_code_tbl.rate > 6.0) AND
(sales_rep_tbl.commission_rate >= 8);
The SELECT statement returns the following:
RIGHT OUTER JOIN
The RIGHT OUTER JOIN operates similarly to a LEFT OUTER JOIN except the RIGHT or
second named table of unmatched rows are preserved.
SELECT *
FROM t1 RIGHT OUTER JOIN t2
ON t1.c1=t2.c3;
Right Outer Join Example:
This example is using a right outer join to display all distinct unmatched records from the sales
tax code table based the sales_rep table.
SELECT DISTINCT sales_tax_code_tbl.rate from sales_rep_tbl RIGHT OUTER JOIN
sales_tax_code_tbl ON (sales_rep_tbl.commission_rate = sales_tax_code_tbl.rate) AND
(sales_tax_code_tbl.rate > 8.0);
LAST_NAME YTD_SALES COMMISSION RATE
Longer 80000 8 8
Hillerger 675000 9.5 9.5
Valentine 857000 9 NULL
Smith 950000 8.75 NULL

PointBase
Version 4.8 PointBase Developer 170
The SELECT statement returns the following:
UNION operator
SELECT a,b
FROM t1
UNION
SELECT a,b
FROM t2
One of the core SQL operators in conjunction with the SELECT statement is the UNION
operator. It is a relational operator that combines the output of two SELECT statements; that is,
they combine two or more result tables whose respective column data types are of the same
family data type. For example, a UNION on a CHARACTER and VARCHAR will work
because they are part of the String data type family. A SMALLINT and an INTEGER UNION
will also work, because they are part of the exact NUMERIC data type family.
The UNION operator has two forms: the first, UNION DISTINCT, returns only unique rows
from a query and discards any duplicate rows; the second, UNION ALL, does not discard
duplicate rows; it returns all rows from the first SELECT statement followed by all rows from
the second SELECT statement. You may specify any number of UNION operators, however
you may not mix UNION ALL and UNION DISTINCT in the same query scope. However,
you may have UNION ALL in the main query and UNION DISTINCT in a subquery, for
example. You will receive an error if you mix two different forms of the UNION operator in a
the same query scope.
The output column names resulting from a UNION will have the same column names that the
expressions in the very first SELECT statement had. If the UNION query uses the ORDER BY
clause, PointBase will order the final results after evaluating all UNIONs. The ORDER BY
clause must be last in the query—after specifying all of the UNIONs. Any column names in
the ORDER BY clause must refer to the column names in the very first SELECT statement in
the query, as the ORDER BY clause sorts the final results by the output column names.
RATE
8.25
8.5
9.5
9.75
10.25
11.5
13

PointBase
Version 4.8 PointBase Developer 171
Union Examples:
This example is combining two character columns from the office table and product table. The
results will include all of the rows of data from each table.
SELECT type_code FROM office_tbl UNION ALL SELECT prod_code FROM product_code_tbl;

PointBase
Version 4.8 PointBase Developer 172
The SELECT statement returns the following:
type_code
----------
A
R
R
R
R
R
R
R
W
BK
CB
FW
HW
MS
SW
This example uses the columns as in the previous example; however, it uses UNION
DISTINCT and orders the results by “type_code.” The result will not return any duplicate
rows.
SELECT type_code FROM office_tbl UNION DISTINCT SELECT prod_code FROM product_code_tbl
order by type_code;
type_code
----------
A
BK
CB
FW
HW
MS
R
SW
W

PointBase
Version 4.8 PointBase Developer 173
Subqueries
Subqueries can be either a SELECT statement or an expression that you can use in any DML
statement, for example, SELECT, INSERT, DELETE, UPDATE. The following describes
different types of subqueries that PointBase supports.
Notes on PointBase Subqueries
• PointBase allows a subquery to return multiple values using the quantified operators,
EXITS, NOT EXISTS, IN, or NOT IN only. See "Predicates" on page 82 for more
information about IN, NOT IN, EXISTS, or NOT EXISTS.
• Currently, PointBase does not support row subqueries.
Scalar Subquery (Non-correlated) Example
This example retrieves the names of all sales people in the Miami office.
SELECT a.first_name, a.last_name
FROM sales_rep_tbl a
WHERE a.office_num =
( SELECT b.office_num
FROM office_tbl b
WHERE city = ’Miami’ );
Subquery Type Description
Scalar Subquery A subquery that returns at most one row and one column.
Table Subquery
(with one column)
A subquery that may return any number of rows within
one column. A table subquery may only appear on the
right hand side of a quantified comparison predicate. This
type of predicate compares a single row value of a table to
potentially multiple result row values from a subquery.
PointBase supports table subqueries only in a quantified
comparison predicate that uses the quantified operators,
IN, NOT IN, EXISTS, or NOT EXISTS. Also see
"Predicates" on page 82 for more information about these
quantified operators.
Non-correlated Subquery A subquery that does not use a correlated (outer)
reference. It references a column, which an enclosing
(outer) query block does not define.
Correlated Subquery A subquery that uses a correlated reference, sometimes
referred to as an “outer reference”. It references a column,
which an enclosing (outer) query block defines.
Nested Subqueries A subquery located within another subquery. PointBase
supports any level of nested subqueries.

PointBase
Version 4.8 PointBase Developer 174
Results:
Scalar Subquery (Correlated) Example
This example retrieves the cities of all the offices whose target sales exceed all the sales
representative’s quotas working in them.
SELECT a.city
FROM office_tbl a
WHERE a.target_sales >
( SELECT sum(b.quota)
FROM sales_rep_tbl b
WHERE b.office_num = a.office_num);
Results:
Table Subquery (Non-correlated) Example
This example retrieves the names of all sales reps working in the western region.
SELECT a.first_name, a.last_name
FROM sales_rep_tbl a
WHERE a.office_num IN
( SELECT b.office_num
FROM office_tbl b
WHERE b.region = ’Western’);
FIRST_NAME LAST_NAME
John Longer
CITY
Miami
Atlanta
San Mateo
San Francisco
San Diego
Oakland
Detroit
New York

PointBase
Version 4.8 PointBase Developer 175
Results:
Table Subquery (Correlated) Example
This example retrieves all cities, in which at least one sales representative works.
SELECT a.city
FROM office_tbl a
WHERE EXISTS
( SELECT *
FROM sales_rep_tbl b
WHERE a.office_num = b.office_num);
Results:
FIRST_NAME LAST_NAME
Heather Smith
George Valentine
Raymond Brown
Jack Smith
CITY
Miami
Atlanta
San Mateo
San Francisco
San Diego
Oakland
Detroit
New York

PointBase
Version 4.8 PointBase Developer 176
INSERT
INSERT INTO table_name [(insert_column_list)]
query_expression
The INSERT statement adds new rows to a table in a PointBase database.
NOTE: To insert, you must have privileges on the entire table. Partial privilege on some
columns will not work because you have to insert some data (null) into other columns.
Syntax
Query_Expression
The query_expression can take one of the following forms:
NOTE: PointBase effectively ignores any spaces that trail after a string when using the
INSERT statement. This behavior supports the ANSI standard; however, it may vary
with other database vendors.
INSERT INTO The INSERT INTO keywords are required as the first words in
an INSERT statement.
table_name table_name identifies the table that will receive the new data
specified in the INSERT statement.
(insert_column_list) The optional list of columns that receive values in an INSERT
statement are indicated between parentheses and separated by
commas. The order of the list of columns is important, since the
first value following the VALUES clause inserts into the first
column in the list of columns. Each subsequent column matches
with its counterpart in the query_expression. The
insert_column_list is optional. If it is not specified, then an
implicit column list is assumed.
Please note: when inserting a specific value into an IDENTITY
column, every row value that follows in that column will
continue to have an incremental value based on the highest value
assigned for that column—even if the highest value was deleted
or rolled back. (See "IDENTITY Property for Autoincrement" on
page 44.)]
query_expression The query_expression indicates the values that insert into the
table in the INSERT statement.

PointBase
Version 4.8 PointBase Developer 177
Form 1: Table_values_constructor
The table_values_constructor can be lists of values to be inserted into the columns in the
insert_column_list. The keyword VALUES, as in VALUES(value1, value2, value3), precede
the list of table constructor values.
Another variation of the table_values_constructor allows more than one row at a time with a
single INSERT statement. Each row of data must contain a value for each column in the list of
columns that matches the data type of the column. Enclose each row of data in its own set of
parentheses.
Examples
The following INSERT statement inserts a row of data with discrete values:
INSERT INTO OFFICE_TYPE_CODE_TBL (TYPE_CODE, DESCRIPTION, MISC)
VALUES (’C’, ’Caller’, NULL);
This example inserts into a table where one of the columns has the IDENTITY property. This
column will have the ability to autoincrement the values for each row. Note that you can insert
values explicitly for the IDENTITY column or allow values to be automatically generated by
not explicitly inserting them. Remember that, PointBase will continue to generate incremental
values based on the highest value assigned for the column—even if the highest value was
deleted or rolled back.
CREATE TABLE TAB1(ID INT IDENTITY, NAME VARCHAR(30));
INSERT INTO TAB1(ID,NAME) VALUES(100, ’Palo Alto’);
INSERT INTO TAB1(ID,NAME) VALUES(101, ’Menlo Park’);
INSERT INTO TAB1(NAME) VALUES(’Cupertino’);
Unicode data values use the “\u” delimiter for each character with PointBase Commander. For
example, unicode representation of the French alphabet is the following:
\u05d0 through \u05ea
such as:
INSERT INTO OFFICE_TYPE_CODE_TBL VALUES (’F’, ’French’, ’gar_on’);
From a JAVA program, unicode characters are treated like others and may be expressed
through their escape literal representation, such as the following:
INSERT INTO OFFICE_TYPE_CODE_TBL VALUES (’X’, ’French’, ’\u00f4’);
Inserting Multiple Rows
A single INSERT statement can use discrete values to insert more than one row of data by
nesting the values for rows enclosed in parentheses, such as the following:
INSERT INTO OFFICE_TYPE_CODE_TBL VALUES (’B’, ’ ‘Buyer’, ’Decision Maker’), (’S’,
’Seller’, ’ Sales Rep’), (’T’, ’Talker’, ’ Not a Programmer’);

PointBase
Version 4.8 PointBase Developer 178
In the PointBase Commander or Console, this example uses dynamic SQL where the value is
supplied at runtime.
INSERT INTO ORDER_TBL(ORDER_NUM, CUSTOMER_NUM, REP_NUM, PRODUCT_NUM, SALES_TAX_ST_CD,
QUANTITY, SHIPPING_COST, SALES_DATE, SHIPPING_DATE, DELIVERY_DATETIME,
FREIGHT_COMPANY)VALUES(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?);
{
010398552, 1, 5001, 980001, ’FL’, 000010, 449.00, ’1998-01-02’, ’1998-01-02’, ’1998-01-15
15:00:00’, ’Southern Freight’
010398967, 1, 5001, 980001, ’CA’, 000010, 449.00, ’1998-01-02’, ’1998-01-02’, ’1998-01-15
15:00:00’, ’California Freight’
};
Form 2: DEFAULT VALUES
Default values can be the list of values that are created to be inserted into the table. It will
contain the default values as specified in the CREATE TABLE statement. If the default value
of a column is the NULL value and null values are not allowed (NOT NULL), then an error is
raised.
DEFAULT and NULL can be used to represent values to be inserted into the table. If
DEFAULT is specified, then the default value specified (explicitly or implicitly) is inserted
into the column. If NULL is specified, then the NULL value is inserted into the column. Note:
If an attempt to insert a NULL value in a column and nulls are not allowed (NOT NULL), then
an error is raised.
Examples
INSERT INTO T2 VALUES (DEFAULT);
or
INSERT INTO T2 VALUES (DEFAULT VALUES);
Form 3: Query Specification
Query specification is the list of values that you create from an SQL SELECT query. The result
set returned from the query must have the same number of column values, with the same data
types, as the list of columns in the INSERT statement.
If you duplicate column names between the source table and the target table in a query
specification, each table name must have a correlation name and you must qualify the column
names with the correlation name.
Example
INSERT INTO LOCAL_SALES_TAX_CODE_TBL SELECT * FROM SALES_TAX_CODE_TBL WHERE STATE_CODE =
’FL’;

PointBase
Version 4.8 PointBase Developer 179
UPDATE
UPDATE table_name
SET set_clause_list
[WHERE search_condition]
The UPDATE statement changes the values of data in the table(s) contained in the PointBase
database.
Syntax
The set_clause_list has two possible forms:
column_name = value [{, column_name = value}...]
or
(column_name [{, column_name}...]) = VALUES(value [{,value}...])
The list of value expressions sets the value of the columns in the target table. Each value
expression includes the name of a column in the table, the equal sign (=), and the new value for
the column. The new value for the column can be a constant, a column in the table, DEFAULT
keyword, NULL keyword, or a value computed with either one of these value types using an
SQL Scalar function.
A single UPDATE statement can update one or more columns in the designated table. If you
update more than one column, separate the value expressions with commas.
If DEFAULT is specified, then the default value of the column on the CREATE TABLE is
inserted into the column. If NULL is specified, then the NULL value is inserted into the
column. If an attempt to insert null value into a column and the column does not allow this
(NOT NULL) then an error is raised.
An alternative syntax for the set_clause_list is SET (column list) = VALUES (value list).
UPDATE The UPDATE key word is required as the first word in an
UPDATE statement.
table_name Table_name identifies the table that contains the columns to
update.
SET The SET clause is required in an UPDATE statement between
the table_name identifier and the list of columns to be updated.
WHERE
search_condition
The WHERE clause specifies selection criteria for an UPDATE
statement. The search_condition that follows the WHERE
keyword evaluates for each row in the indicated table. If the
search_condition returns true for a row, the columns in the row
update with the new values indicated in the UPDATE statement;
if the search_condition returns false or unknown, the row is
ignored by the UPDATE statement.

PointBase
Version 4.8 PointBase Developer 180
NOTE: If an UPDATE statement does not contain a WHERE clause, all rows in the target
table update with the new values. The UPDATE statement writes new values to rows in
a PointBase database, but the changes become permanent only when a COMMIT
statement executes following an UPDATE statement, which finalizes changes to the
database.
If the UPDATE of a row causes the row to expand past the limits of the page or pages
that contained it originally, PointBase will automatically allow the row to span pages.
The JDBC calls that execute the UPDATE statement return the number of rows
updated.
Examples
UPDATE ORDER_TBL SET FREIGHT_COMPANY=’Shipping Express’,customer_num=25 WHERE
order_num=10398001;

PointBase
Version 4.8 PointBase Developer 181
DELETE
DELETE FROM table_name
[WHERE search_condition]
The DELETE statement deletes a row in a table in a PointBase database.
Syntax
The DELETE statement marks rows in the database for deletion. The rows are actually
removed when a commit occurs after the statement executes, which completes any changes to
the database. For more information on COMMIT, see “Transaction Control.”
The JDBC calls that execute the DELETE statement return the number of rows to be deleted.
Examples
DELETE FROM ORDER_TBL
WHERE SHIPPING_COST <= 275.00;
DELETE FROM ORDER_TBL
WHERE SHIPPING_COST =?
{
1.00
2.00
3.00
};
DELETE FROM The DELETE FROM keyword is required in a DELETE
statement.
table_name The table_name is the name of the table from which the selected
rows are to be deleted.
WHERE
search_condition
The optional WHERE clause specifies selection criteria for a
DELETE statement. The conditional expression that follows the
WHERE keyword is evaluated for each row in the identified
table. If the search_condition returns true for a row, the row is
deleted; if the search_condition returns false, the row is not
deleted. If no WHERE clause is specified, all rows are deleted
from the table. See “Search Conditions and Predicates,” for more
information.

PointBase
Version 4.8 PointBase Developer 182
Data Control Language
To manipulate data, use the Data Control Language (DCL). With DCL, you can perform the
following:
• CALL: Execute an SQL procedure.
• RETURN: Return a value from an SQL function.
• SET assignment: Assign a value to an SQL variable.
• SET PATH: Set or change the current path being used to locate the SQL objects in
various schemas.
• SIGNAL: Raise an SQLState exception.
• VALUES: Invoke an SQL routine.
CALL
CALL procedure_name([argument_list])
The CALL statement executes an SQL routine that is a procedure.
Syntax
Examples
CALL PROC1();
CALL PROC2(‘abc’);
CALL The CALL keyword is required in a CALL statement.
procedure_name The procedure_name is the name of the procedure which is
executed. No results are returned.
argument_list The optional argument_list clause specifies values for the CALL
statement.
NOTE: Only constants can be used. You cannot use new or old
row values.

PointBase
Version 4.8 PointBase Developer 183
RETURN
RETURN routine_invocation
The Return statement returns a scalar value from a Java stored procedure that is a function, in
the form a result set.
Syntax
Examples
RETURN PROC1();
RETURN PROC2(‘abc’);
RETURN The RETURN keyword is required as the first word in a
RETURN statement.
routine_invocation The routine_invocation must be an SQL routine invocation,

PointBase
Version 4.8 PointBase Developer 184
SET assignment
SET assignment_target = assignment_source
You may use SET assignment statements for BEFORE triggers only. The SET assignment
statement assigns a value to an SQL Trigger row correlation variable. The SET assignment
statement is much like the set_clause of an SQL UPDATE statement.
Syntax
Examples
SET newrow.inventory = getnewvalue ( );
SET newrow.selldate = CURRENT_DATE;
SET my_newalias.fruitname = ‘apples’;
SET The SET keyword is required as the first word in a SET
assignment statement.
assignment_target The assignment_target consists of both, an SQL correlation
variable of an SQL Trigger and a column_name. The
column_name refers the column of the SQL correlation variable.
You may use new or old row values.
assignment_source The assignment_source is one or more SQL expressions that can
be a constant, an SQL routine invocation, one of the SQL Scalar
functions, an SQL Cast functions, or an SQL Special Register.
You may not use an SQL correlation variable; however, you can
reference new or old row values in the WHEN search_condition.
Assignment_source values are assigned to the assignment_target.

PointBase
Version 4.8 PointBase Developer 185
SET PATH
SET PATH schema_name [{,schema_name}...]
With the SET PATH statement, you can use it to set or change the current path that you are
using to locate the SQL objects in various schemas. This results in the setting of the
CURRENT_PATH of a SQL session. To find the correct system tables, the schema
POINTBASE must be included in the path.
Syntax
Examples
SET PATH Employees, Engineering, Sales, PointBase;
This sets the CURRENT_PATH to the following schemas in the order specified: Employees,
Engineering, Sales, and PointBase. If you wish to append the Marketing schema to the
CURRENT_PATH so that the order becomes Employees, Engineering, Sales, PointBase, and
Marketing, enter:
SET PATH CURRENT_PATH, Marketing;
If you never execute a SET PATH statement, then the CURRENT_PATH consists of the
schema POINTBASE, followed by your existing schema. When a SET PATH statement is
issued, it completely replaces the existing CURRENT_PATH, unless CURRENT_PATH is part
of the schemas being set in the path.
The order of the schemas in the path is generally crucial. When the database system is looking
for SQL objects, it looks for them in each schema (unless explicitly referenced otherwise),
starting with the first schema in the path, then the next, etc...., until an SQL object is found that
meets the criteria. One way to override the CURRENT_PATH is to explicitly reference the
SQL object. For example, to reference a table, you can specify schema_name.table_name. In
the above examples, the SQL object of table_name would be searched in the schema of name
schema_name.
SET PATH The SET PATH keywords are required as the first words in a SET
PATH statement.
schema_name Required keywords to begin the statement.

PointBase
Version 4.8 PointBase Developer 186
SIGNAL
SIGNAL ‘sqlstate_message’
With the SIGNAL statement, you can use it to raise an SQLSTATE exception. This statement
can only be used within a trigger_body or within the body of an SQL routine, whose language
type is SQL. This statement will cause an SQLSTATE exception to be thrown and propagated
back to your program. You provide the text of the message.
NOTE: The SIGNAL statement rolls back the specific event that activated its trigger and all
the changes caused by the trigger, as well as the original SQL statement of the user,
which includes all the triggers and cascading actions that it invoked.
Syntax
Examples
SIGNAL‘The oranges inventory is empty’;
SIGNAL ‘The salary of an employee would have been higher than the salary of his/her Man-
ager’;
SIGNAL The SIGNAL keyword is required as the first word in a SIGNAL
statement.
sqlstate_message The sqlstate_message is an SQL string literal value. You can
specify any text they would like. The actual SQLSTATE code
will be ZG014 and the SQL error code is 25014.

PointBase
Version 4.8 PointBase Developer 187
VALUES
VALUES ( SQL_expression [ { , SQL_expression } ... ] )
The VALUES statement is an SQL stand alone SQL statement. It should not be confused with
the values_clause of an INSERT statement or with the from_clause of an SQL Select
statement.
Typically, the VALUES statement is used to invoke SQL routines. The VALUES statement
discards all SQL expression values returned by either a constant, an SQL routine invocation,
one of the SQL Scalar functions, one of the SQL Cast functions, or an SQL Special Register.
Syntax
Examples
VALUES (addnewfruit( ‘apple’) );
VALUES (increaseorders(200) );
VALUES (CURENT_DATE );
SET CONSTRAINTS
SET CONSTRAINTS <constraint name list> { DEFERRED | IMMEDIATE }
<constraint name list> ::= ALL
| <constraint name> [ { <comma> <constraint name> }... ]
You may use SET CONSTRAINTS statements to change when the constraint checking will be
performed. The scope of this statement is for the current transaction only. If no active
transaction exists while executing this statement, this setting will be effective on the next
transaction. Only constraint which is defined deferrable can be specified in the constraint name
list, otherwise an exception will be thrown.
If constraint mode is set to immediate from deferred, constraint checking will be performed on
all deferred rows of this constraint. This only gives the current status of deferred rows of this
constraint. All deferred rows will be effectively checked at the end of the transaction again.
VALUES The VALUES keyword is required as the first word in a
VALUES statement.
SQL_expression The SQL_expression can be a constant, an SQL routine
invocation, one of the SQL Scalar functions, an SQL Cast
functions, or an SQL Special Register.

PointBase
Version 4.8 PointBase Developer 188
Syntax
Examples
SET CONSTRAINTS all deferred;
SET CONSTRAINTS con1, con2 immediate;
SET CONSTRAINTS SET CONSTRAINTS keyword is required as the first
two words in a SET CONSTRAINTS statement.
All | constraint_name_list The constraint_name_list contains those constraints to
be set. You can either give ALL or a list of constraint
names separated by comma. Only deferrable
constraints can be specified in the list.
DEFERRED | IMMEDIATE Set to DEFERRED or IMMEDIATE.

PointBase
Version 4.8 PointBase Developer 189
Transaction Control
In this section you can find the following transaction control statements:
• “SAVEPOINT”
• “COMMIT”
• “RELEASE SAVEPOINT”
• “ROLLBACK”
• “SET DATALOG”
• “START TRANSACTION ISOLATION LEVEL”
SAVEPOINT
SAVEPOINT savepoint_name
The PointBase transaction model supports savepoints. Savepoints allow transactions to be
partially rolled back by establishing a point within a transaction. Savepoints are destroyed
automatically when a transaction commits.
NOTE: Make sure that auto commit is turned off when using savepoint.
Syntax
Examples
SAVEPOINT SVP1;
SAVEPOINT 2;
SAVEPOINT
savepoint_name
The savepoint_name can either be an SQL identifier or a numeric
value with a scale of zero.

PointBase
Version 4.8 PointBase Developer 190
COMMIT
COMMIT [WORK]
The COMMIT statement successfully terminates a PointBase transaction.
Syntax
Issuing a COMMIT statement ends the current PointBase transaction. The COMMIT causes
three basic actions in the PointBase database:
1. Writes any and all changes that have occurred to the data during the current
transaction to the database.
2. Releases any locks that have been placed on data in the PointBase database.
3. Destroys any result sets that have been returned from a query.
Examples
COMMIT WORK;
COMMIT [WORK] The COMMIT statement takes no qualifiers. The keyword
WORK is optional.

PointBase
Version 4.8 PointBase Developer 191
RELEASE SAVEPOINT
RELEASE SAVEPOINT savepoint_name
The RELEASE SAVEPOINT statement destroys a savepoint within a transaction and all the
savepoints created after the specified savepoint. The savepoint is automatically released when
a COMMIT or ROLLBACK occurs.
The savepoint name specified in this command should have been created earlier by a savepoint
command in the current transaction. If the savepoint name is not found, an exception is raised
for the invalid savepoint name.
NOTE: Make sure that autocommit is turned off when using savepoint.
Syntax
Example 1
RELEASE SAVEPOINT SVP1;
RELEASE SAVEPOINT 2;
Example 2
CREATE TABLE T1 (c1 int);
Savepoint sp1;
INSERT INTO T1 values (1);
Savepoint sp2;
INSERT INTO T1 values (2);
Savepoint sp3;
INSERT INTO T3 values (3);
RELEASE savepoint sp2;
NOTE: In the last statement of Example 2, the savepoint sp2 is destroyed.
RELEASE
SAVEPOINT
savepoint_name
The savepoint_name can either be an alphanumeric SQL
identifier or an integer number.

PointBase
Version 4.8 PointBase Developer 192
ROLLBACK
ROLLBACK [WORK] [TO SAVEPOINT savepoint_name]
The ROLLBACK statement rolls back any changes that have taken place in a PointBase
transaction to the beginning of the transaction or to a savepoint.
A ROLLBACK TO SAVEPOINT statement allows you to undo all changes to the database
back to the savepoint. This action does not terminate a transaction. If a ROLLBACK
statement references a savepoint, then the transaction rolls back to where the savepoint was
specified.
NOTE: Make sure that auto commit is turned off when using savepoint.
Syntax
Examples
ROLLBACK WORK;
ROLLBACK WORK TO SAVEPOINT SVP1;
Issuing a ROLLBACK statement restores the data changed in a transaction to the values that
existed before the PointBase transaction began. If you specify a savepoint_name, then all
changes made to data in the transaction, after the SAVEPOINT savepoint_name statement was
executed, rolls back. The specified savepoint and all savepoints issued subsequent to this
savepoint are destroyed. The transaction resumes after the savepoint statement.
A ROLLBACK statement without any qualifier ends the current transaction, which causes
two actions in the PointBase database:
1. Releases any locks that have been placed on data in the PointBase database.
2. Destroys any result sets that have been returned from a query.
ROLLBACK TO
SAVEPOINT
savepoint_name
The savepoint_name can either be an SQL identifier or a numeric
value with a scale of zero.

PointBase
Version 4.8 PointBase Developer 193
SET DATALOG
SET DATALOG OFF | ON FOR TABLE table_name
The SET DATALOG command allows administrators to turn OFF or ON data logging for a
specific table. By default, data logging is set to ON for all tables. When set to OFF, deletions or
updates are not allowed on the specified tables. You should turn DATALOG to OFF for
insertions only. If the specified table has one or more indexes, during insertions its indexes
will automatically be updated and the index will be logged.
No transaction should be active while executing a SET DATALOG command. PointBase
recommends that you execute this command just after a ROLLBACK or a COMMIT statement
and before a START TRANSACTION ISOLATION LEVEL statement (or any statement that
starts a transaction.) Any transaction that starts after the SET DATALOG statement will turn
OFF logging for the specified table. At the end of the transaction, logging is automatically
turned back ON. Optionally, before the end of the transaction, you can turn logging ON by
setting the ON option in the SET DATALOG statement.
The main purpose of the SET DATALOG statement is to increase performance by turning off
data logging while inserting a lot of data (via bulk loading) into a table. The table is locked
exclusively by the first insert into the specified table in this transaction. This exclusive lock is
then released at the end of the transaction.
Example 1
In the following example, after the COMMIT statement, the data logging is turned OFF for the
table T1. The INSERT statement starts a transaction, turns off the data logging for table T1 and
inserts all the data from the file ‘data.tab’ into table T1. The final COMMIT commits all the
inserted data and turns data logging ON for table T1.
commit work;
set datalog off for table T1;
SET BULK ON;
insert into T1 values (?,?,?) use c:\data.tab delimiter tab;
commit work;
Example 2
In this example, data logging is turned OFF and one row is inserted into table T2. Although
this is allowed, there is no advantage to turning OFF data logging for only a few row inserts.
commit work;
set datalog off for table T2;
SET BULK ON;
insert into T2 values (10,20,30);
commit work;

PointBase
Version 4.8 PointBase Developer 194
START TRANSACTION ISOLATION LEVEL
START TRANSACTION ISOLATION LEVEL
isolation_level [access_mode], [DIAGNOSTICS SIZE diagnostics_size]
The START TRANSACTION ISOLATION LEVEL statement is an explicit way to start a
transaction.
Syntax
READ UNCOMMITTED
This mode does not permit Read and Write access mode. It is also known as a ‘dirty read.’ In
this mode, all rows, including uncommitted rows are retrieved. For example, if transaction T1
performs one row insert, transaction T2 retrieves that row before T1 ends.
READ COMMITTED
This mode retrieves committed rows only. However, if the same SELECT statement is
executed again, the results may differ due to update from other transaction. For example, a
transaction T1 retrieves a row, another transaction T2 then updates that row and commits, and
T1 then retrieves the same row again. Transaction T1 has retrieved the same row twice, but
produced two different values.
Read and Write are permitted with more concurrency. For most users, this mode may satisfy
their needs. If a transaction isolation level is not specified in the pointbase.ini file, the
default is the transaction isolation level, READ_COMMITTED.
isolation_level PointBase supports the following transaction isolation levels:
• READ UNCOMMITTED
• READ COMMITTED
• REPEATABLE READ
• SERIALIZABLE
access_mode PointBase supports READ ONLY and READ WRITE access
modes. The default mode is READ WRITE. It can only be
specified once. If the access_mode is not specified, then it is
implicitly READ WRITE. In the READ ONLY mode, no
modification to date can be made.
DIAGNOSTICS SIZE
number_of_conditions
The diagnostics_size represents the maximum
number_of_conditions or SQL exceptions that are saved for each
statement that executes. This number lists the number of
conditions that can be held at any given time in the diagnostic
area. The value must be greater than 0. A default value is defined
at implementation time. The number_of_conditions can specified
only once.

PointBase
Version 4.8 PointBase Developer 195
REPEATABLE READ
In this mode, only committed rows are retrieved (as in the READ_COMMITTED) but without
the problem seen in the READ_COMMITTED isolation level: if the same row is retrieved
again in the same transaction, the exact same value is retrieved. However, if a new row is
added by another transaction and commits the insert (also delete or update), a second time
retrieval for the same select statement may include the newly inserted (also deleted or updated)
row. This phenomenon is know as a phantom read.
SERIALIZABLE
This mode is the highest level possible, superior in functionality to a REPEATABLE_READ as
no phantom occurs. If a SELECT statement retrieves a collection of rows to satisfy a condition,
and the same SELECT statement is executed again in the same transaction, then it is
guaranteed to retrieve the same set of rows with the same values.
In this mode, concurrency is reduced compared to other modes. If the number of rows retrieved
or affected by the transaction exceeds the number of locks specified in the pointbase.ini
file, the row level locks are converted to table level locks, further reducing the concurrency.
The default number of locks is 2000.
Example
START TRANSACTION ISOLATION LEVEL SERIALIZABLE, READ WRITE;
START TRANSACTION ISOLATION LEVEL READ UNCOMMITTED READ ONLY

PointBase
Version 4.8 PointBase Developer 196
PointBase-Specific SQL
This section describes non-standard SQL statements that PointBase supports. PointBase has
provided these statements to supply additional functionality for your application. Each section
represents its own SQL statement. For each of them, the section will summarize the purpose,
describe the syntax, explain the usage, and give examples of the statement. You may browse
the PointBase-specific SQL statements to discover useful commands.
SHUTDOWN
SHUTDOWN [FORCE]
To shut down your PointBase Embedded databases, you can use the SHUTDOWN statement.
It can shut down either PointBase Embedded or PointBase Embedded - Server Option.
However, you must be the database owner or the PBSYSADMIN user, or you must have the
PBDBA role for your current role to perform the shut down.
Syntax
Examples
SHUTDOWN;
SHUTDOW FORCE;
BACKUP
BACKUP DATABASE [ROLLFORWARD | CLASS=<user class name >] [PARAM=<user param>]
This SQL statement initiates online backup. Online backup functionality facilitates database
backup while the database application is running. To use this statement, the application must
first implement the PointBase interface, “com.pointbase.tools.toolsBackup.” The example in
this section describes the PointBase default implementation of this interface.
Online backup has many uses. You can use online backup, when you do not want to bring
down the database while taking a backup or when some critical event is recorded in the
database, and you want to backup the database immediately. Additionally, having the online
backup facility, an application has the flexibility to copy the database to any type of storage it
wants, for example, Flash memory.
FORCE It shuts down the database regardless of open client connections.

PointBase
Version 4.8 PointBase Developer 197
Online backup also allows you to start rollforward backup by specifying the ROLLFORWARD
parameter. Rollforward backup allows you to use the backup log statement for subsequent
backups. The backup log statement will only back up logs, which contain changes since the
last backup, instead of backing up all database files. Rollforward backup can only use our
default backup implementation, which copies all files to a directory specified in the <user
param>. Once rollforward backup is enabled, logs will not be freed until they are backed up or
rollforward is disabled. To disable rollforward backup, You may backup the database again
with rollforward disabled or use the set rollforward off statement.
Important Notes
• You may initiate this statement using PointBase Embedded.
• Only the database owner, PBSYSADMIN user, or users with READALL or PBDBA
roles are allowed to backup the database
• During online backup, all transactions, including the one that requests write operations,
are active— but the write operation will wait for the return from copyDatabaseFiles()—
which the application must implement; whereas, the read operations continue without any
interruption if they can proceed.
• While online backup is in progress the SQL statements will not get lock time-out even if
they exceed the regular lock time-out time.
• If CREATE INDEX is in progress then online backup will wait for it to complete.
Syntax
Example
To accomplish the online backup functionality, you must first implement the interface
“com.pointbase.tools.toolsBackup.” Once the interface is implemented, it must be in the
classpath with the embedded database JAR when you launch the application. After launching
the application, you can initiate online backup by executing the BACKUP SQL statement.
PointBase recommends using online backup when the load on the database is light.
Implement toolsBackup Interface
The application needs to implement the toolsBackup interface and the code for copying the
database files. The class that implements this interface needs to have a default constructor, for
example:
interface toolsBackup
{
public void
copyDatabaseFiles(String databaseFiles[], String userParam)
ROLLFORWARD Enable rollforward backup.
<user class name> :=
CLASS= <identifier>
<identifier> is the name of the class which implements the
interface, “com.pointbase.tools.toolsBackup.” If this is not given
in the statement then the default implementation will be used.
(See Example.)
<user param> :=
PARAM= <identifier>
<identifier> is the user parameter(s). This can be a quoted
identifier in which case it can have comma separated values. If
this is not given in the statement then NULL will be passed to the
“copyDatabaseFiles()” method.

PointBase
Version 4.8 PointBase Developer 198
throws Exception;
}
• databaseFiles[] is the absolute filenames of all the files for this database.
• userParam is a String which the application can specify in the online backup SQL
statement that will be passed to this method. This can contain such information as the
destination directory.
Default Implementation
The class, “toolsBackupDefault,” is the PointBase default implementation for the interface,
“com.pointbase.tools.toolsBackup.” In this default implementation, you must write the code
that copies the data files to some destination directory. This implementation does not overwrite
any files. If the destination directory contains files with the same name of the backup database
file then an Exception is raised. If the userParam is NULL, then the destination directory is
“<database directory>/backup.” <database directory> is the directory of the original database
file. If you specify the userParam, then it should be a valid existing directory. The file copy is
done in blocks of data and the block size is 4096.
The following code describes the PointBase default implementation, “toolsBackupDefault.”
package com.pointbase.tools;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.IOException;
import java.io.OutputStream;
public class toolsBackupDefault implements toolsBackup
{
static int COPY_BLOCK_SIZE = 4*1024;
public toolsBackupDefault()
{
}
public void copyDatabaseFiles( String[] p_databaseFileNames,
String p_userParams)
throws Exception
{
File l_databaseFiles[] = new File[p_databaseFileNames.length];
for(inti=0;i<p_databaseFileNames.length;i++)
l_databaseFiles[i] = new File(p_databaseFileNames[i]);
String destinationDir;
if (p_userParams == null)
{
destinationDir = l_databaseFiles[0].getParent()+ "/backup";
}
else
destinationDir = p_userParams;
File fDirectory = new File(destinationDir);
if (p_userParams == null)
{
if (!fDirectory.exists())
fDirectory.mkdir();
}
if (!fDirectory.exists())
throw new Exception("The destination directory "+ destinationDir + "
does not exist");

PointBase
Version 4.8 PointBase Developer 199
if (!fDirectory.isDirectory())
throw new Exception("The destination is not a directory");
// Check if any of the files with the given database file names exist
// in the destination
for( int i=0; i<l_databaseFiles.length; i++ )
{
File l_destination = new File( destinationDir,
l_databaseFiles[i].getName());
if (l_destination.exists())
throw new Exception("The destination directory already contains
file"+l_destination);
}
// Copy the database files
for( int i=0; i<l_databaseFiles.length; i++ )
{
File l_destination = new File( destinationDir,
l_databaseFiles[i].getName());
l_destination.createNewFile();
copyFile( l_databaseFiles[i], l_destination );
}
}
private void
copyFile( File fSource, File fDest )
throws IOException
{
InputStream fis = new BufferedInputStream(new FileInputStream(fSource));
OutputStream fos = new BufferedOutputStream(new
FileOutputStream(fDest));
int iLen = (int) fSource.length();
// read the input byte array...
byte[] buf = new byte[ COPY_BLOCK_SIZE ];
int toGo = iLen;
int dataRead;
while(toGo>0)
{
toGo -= (dataRead = fis.read( buf));
fos.write(buf, 0, dataRead);
}
fos.close();
fis.close();
}
}
Include Implementation in Classpath
Whatever the user implementation of the toolsBackup interface is, the class must be in the
classpath with the PointBase Embedded JAR files, when launching the application, for
example:
java -classpath c:\pbembedded45.jar;c:\pbtools45.jar;c:\<userimplementation.class>;
The PointBase default implementation is located in the “pbtools” JAR.
Execute BACKUP Statement
The following example executes the BACKUP statement using the PointBase default
implementation of the “toolsBackup” interface and specifies the destination directory, “c:/
backup/databases.”
BACKUP DATABASE PARAM=”c:/backup/databases”;

PointBase
Version 4.8 PointBase Developer 200
The next example does not specify a destination directory, so the PointBase default
implementation copies the backup database file to, “<database directory>/backup.” <database
directory> is the directory of the original database file.
BACKUP DATABASE CLASS="com.pointbase.tools.toolsBackupDefault";
The following example does not specify an implementation class of “toolsBackup” nor does it
specify a destination directory. If this is the case, the PointBase default implementation,
“toolsBackupDefault” is used, and the destination directory is “<database directory>/backup.”
BACKUP DATABASE;
The following example specifies rollforward parameter with a backup directory. If this is the
case, the PointBase backs up all file to the destination direcory "c:/backup/databases" and
enables rollforward.
BACKUP DATABASE ROLLFORWARD PARAM="c:/backup/databases";
BACKUP TABLE
BACKUP TABLE PARAM='TABLES=<table name>[[,<table name>]…] SCHEMA=<schema name>
[FILENAME=<backup file name>] [PATH=<backup directory>]'
This SQL statement is an addition to the PointBase online backup statement. Table backup
copies tables to an external file in binary format instead of the text format used by the unload
command. A corresponding restore statement is provided for restoring tables. This statement
backs up only tables and not indexes or constraints. You may need to recreate indexes after a
restore. This backup works much faster than the unload command since it is doing a page level
backup instead of row level. During backup, only tables being backed up are locked. DML is
prevented during backup, but DQL is still allowed.
Table backup may create multiple files in <database.home>/backup directory if data exceeds
the maximum file size that the file system supports. File names start with the <database name>
+ <first table name>, the default backup name, with extension ".bak". For example, a backup
from database "sample" of table "tab1" may create sample_tab1.bak and sample_tab1$[n].bak
and so on. You may specify different <backup name> or backup directory. Before backing up
tables, all files starting with this <backup name> in backup directory will be deleted, so you
should use different <backup name> to avoid confusion.
Important Notes
• All PointBase online backup semantics also apply to the backup table statement.
• Backups can only be restored to a database which has the same internal database version.
• Only tables being backed up are locked. For those tables being backed up, shared locks
are placed on the tables and locks are released after the transaction is committed or rolled
back.

PointBase
Version 4.8 PointBase Developer 201
Syntax
Example
The following example backs up tables tab1 and tab2 to an external file "test.bak" in directory
"test".
BACKUP TABLE PARAM=’TABLES=tab1,tab2 SCHEMA=pbpublic FILENAME=test PATH=test’
RESTORE TABLE
RESTORE TABLE PARAM=’FILENAME=<backup file name> [SCHEMA=<schema name>]
[PATH=<backup directory>]’
This SQL statement is a corresponding statement to the table backup statement. Table restore
restores backup files into the current database. Tables being restored have the same name as
the original tables, but tables can be restored to a different schema. In case you need to restore
to a different table name, the "alter table … rename" statement may be used to change the table
name after restoring it. The RESTORE TABLE command restores only tables. Since indexes
are not backed up, indexes will not be automatically created in the target database. Constraints
are also not backed up or restored, but can be added with ALTER TABLE...ADD
CONSTRAINT.
Two scenarios in the target database may occur as follows:
• If the table does not exist in the target database, the table will be created and populated
automatically. If the restore fails, the operations undertaken to create the table will be
rolled back.
• If tables exist in the target database, a semantic checking which compares the schema of
existing table and restored table, will be performed. If the semantic check failed, an
exception is raised. Otherwise, tables will be locked exclusively and pages from the
backup file will be restored to the current table. If indexes exist, the indexes will be re-
TABLES
TABLES specifies one or more table names, table
name has no prefix with schema name
SCHEMA
SCHEMA specifies the schema to which the table
belongs. Only tables from the same schema can be
backed up together.
FILENAME
FILENAME specifies the filename of the backup file.
The default is <database name>_<first table name>.
An external file with <FILENAME>.bak will be created
and used as the backup file. If more external files are
needed, <FILENAME>$[N] is used for subsequent
files.
PATH
PATH specifies the directory where backup files will be
created. The default is <database.home>/backup.

PointBase
Version 4.8 PointBase Developer 202
built. Any data in the original table will be lost after the restore. Note that constraints, for
example referential constraint, may not be guaranteed since RESTORE won’t perform
row level checking after restore.
In both cases, if the restore fails, this statement will be automatically rolled back. To ensure
rollback works efficiently, twice the number of pages of the table are required since the
original pages of the table are saved and new pages are allocated for new rows. If autocommit
is not on, you may choose commit to make the restore permanent or rollback to rollback the
restore.
Important Notes
• All PointBase online backup semantics also apply to the restore table statement.
• If the schema name does not exist in the database, an exception will be thrown.
• The logged in user needs to have administrator privilege (same as BACKUP).
Syntax
Example
The following example restores tables tab1 and tab2 to schema pbnew from an external file
"test.bak" in directory "test".
BACKUP TABLE PARAM=’FILENAME=test SCHEMA=pbnew PATH=test’
BACKUP/RESTORE TABLE API
Backup/Restore can also be done through streams. You may create an output stream for backup
or an input stream for restore. With this, you may be able to use special devices or third party
tools. This functionality is supported through API calls.
FILENAME
FILENAME specifies the filename of the restore file. It
will be the same FILENAME parameter given in the
backup statement. Extension ".bak" will be appended
to the FILENAME.
SCHEMA
SCHEMA specifies the schema to which tables will be
restored. All tables will be restored to the same
schema. If not specified, the original schema name
from backup database is used.
PATH
PATH specifies the directory where backup files are
located. The default is <database.home>/backup.

PointBase
Version 4.8 PointBase Developer 203
toolsBackupTable class is provided for performing backup and restore operations through Java
methods. toolsBackupTable implements Runnable interface, so it can be run directly or from a
new thread. You may call the backup() or restore() methods in toolsBackupTable to construct a
toolsBackupTable object and it also indicates the operation to perform. These two methods
return a toolsBackupTable object, and you may call the run() method to start a new thread to
begin the operation.
An event listener interface, toolsBackupEventListener, is also provided. You may implement
this interface to get notification of the progression and completion of this operation. An event,
toolsBackupEvent, will be sent to the event listener to indicate the status of the operation,
which can be progress, completed, failed or canceled. For progress event, it will be sent for
every 100 pages processed on both backup and restore. The total number of page processed
can be obtained from the event as well by calling getPageCount method. If no event listener is
implemented, pass null as event listener, and events won’t be sent. For more detail, please refer
to toolsBackupTable javadoc.
Example
The following code snippet creates a pipe for doing backup and restore.
// import necessary classes
import com.pintbase.toolsBackupTable;
import com.pintbase.toolsBackup
import com.pintbase.toolsBackupEventListener;
// create a pipe for backup and restore
PipeInputStream is = new PipeInputStream();
PipeOutputStream os = new PipeOutputStream( is );
// create two connections connecting to two databases
Connection Con1 = DriverManager.getConnection( "jdbc:pointbase:embedded:db1" );
Connection Con2 = DriverManager.getConnection( "jdbc:pointbase:embedded:db2" );
// initialize backup on table pbpublic.tab1 through output stream
toolsBackupTable backupObj =
toolsBackuptable.backup( Con1, "pbpublic", "tab1", os, new testEventListener() );
// start a thread for doing backup
Thread backupThread = new Thread( backupObj );
backupThread.start();
// initialize restore on table pbpublic.tab1 through output stream
toolsBackupTable restoreObj =
toolsBackuptable.restore( Con2, null, is, new testEventListener() );
// start a thread for doing restore
Thread restoreThread = new Thread( restoreObj );
restoreThread.start();
// wait for threads to complete
backupThread.join();
restoreThread.join();
// close all streams and conections
is.close();
os.close();
Con1.close();
Con2.close();
class testEventListener implements toolsBackupEventListener
{
public void processEvent( toolsBackupEvent event )
{
System.out.println(
"Got event with status: " + event.getStatus() +

PointBase
Version 4.8 PointBase Developer 204
" sql exception: " + ((event.getSQLException() == null) ?
null : event.getSQLException().getMessage() ));
}
}
BACKUP LOG
BACKUP LOG [<user param>]
This SQL statement can only be used when rollforward is enabled. backup log statement backs
up log files and a description file with .rfd extention to the directory specified in <user param>.
This is useful when the database is too large but does not have much update transactions. In
this case, backup logs will be a lot faster than backup the entire database everytime. A
sequence number is used in the rollforward backup to indicate the order of backups. This
sequence number is added as part of the backed up filename. When the rollforward is enabled,
the sequence number is initialized to 0 and is incremented by 1 for every log backup. For
example, you may see a backup file, sample$0.rfd, as the description file of database backup
with rollforward enabled of database sample and sample$1.rfd for the first log backup.
Important Note
All PointBase online backup semantics also apply to the backup log statement.
Syntax
Example
The following example backs up logs in the directory c:/pointbas/backup.
BACKUP LOG PARAM="c:/pointbase/backup"
SET ROLLFORWARD
SET ROLLFORWARD OFF
<user param> :=
PARAM= <identifier>
<identifier> is the
user parameter(s)
This is used to set the backup directory only. If
not set, the default backup directory is
<database.home>/backup.

PointBase
Version 4.8 PointBase Developer 205
This SQL statement disables rollforward backup. If rollforward is not enabled, this statement is
no-op. Once the rollforward is disabled, you have to enable it through backup database
statement again.
ROLLFORWARD RESTORE UTILITY
java com.pointbase.tools.toolsRestore
-url url [-user user] [-password password] [-backupdir dir] [-numlogs num] [-
logdir dir]
Restore will be a utility instead of a SQL statement because the database will be created or
completely overwritten if one exists. User and password are used to connect to the existing
database. If the database exists, user needs to be the DBA or owner of the database to delete the
database. If the database is partially damaged and cannot be started, this verification is
skipped. The database will be restored in the directory specified by PointBase database.home.
This parameter can be set in the URL or in the file pointbase.ini. User may put database
backups in one directory and log backups in another directory by specifying -backupdir and -
logdir parameters, or in the same directory by specifying only -backupdir parameter. All log
backups need to be located in the same directory. Restore will not run if any backup is missing.
-url url
Specify the url. User must use embedded option.
User may use database name instead of url if no
database parameter is given.
-user user
Specify user name used to connect to existing
database. The default is PBPUBLIC.
-password password
Specify password used to connect to existing
database. The default is PBPUBLIC.
-backupdir dir
Specify the directory where the database backup is
located. If this directory is the same as
database.home, it is assumed that user has pre-
copied all files to this directory, so these files will
be used directly without copying. The .dbn files
will be used directly and .wal files will be renamed
to their original names and used for recovery.
-numlogs num
Specify the number of log backups. If -numlogs
parameter is not given, restore utility automatically
detects all log backups in the backup directory and
restores all of them.
-logdir dir
Specify the directory where all log backup files are
located. If not specified, it is assumed to be the
same as -backupdir.

PointBase
Version 4.8 PointBase Developer 206
User may not need to restore all log backups. Depending on the -numlogs parameter in the
restore utility, user may specify number of logs to be restored.
Example
The following example shows the sequence of events in restoring a database from directory c:/
pointbase/backup.
java com.pointbase.tools.toolsRestore -url testmut16 -backupdir "c:/pointbase/backup"
Restore Sequence:
Restored directory: \pointbase\databases
Backup directory: c:\pointbase\backup
Found 3 log backups, restoring 3 log backups
Deleting database files
Restoring database backup
Restoring log backups
Restoring log backup 1
Restoring log backup 2
Restoring log backup 3
Recovery
Restore completed successfully

Version 4.8 PointBase Developer 207
Appendix B: Unsupported JDBC
Methods in PointBase
Table 1 describes the unsupported JDBC methods from the java.sql package.
Table 1: Unsupported JDBC Methods From Java.sql Package
Java.sql Class Unsupported Methods
Blob setBytes(long pos, byte[] bytes)
setBytes(long pos, byte[] bytes, int offset, int len)
setBinaryStream(long pos)
truncate(long len)
CallableStatement getArray(int p_parameterIndex)
getObject(int p_parameterIndex,java.util.Map p_map)
getRef(int p_parameterIndex)
setArray(int p_parameterIndex,Array p_value)
setRef(int p_parameterIndex,Ref p_value)
Connection getTypeMap()
setTypeMap(java.util.Map p_map)
getHoldability()
setHoldability(int holdability)
DatabaseMetaData getUDTs(String p_catalog,String p_schemaPattern,String p_typeNamePattern,int[]
p_types)
public boolean locatorsUpdateCopy()

PointBase
Version 4.8 PointBase Developer 208
PreparedStatement setArray(int p_parameterIndex,Array p_value)
setRef(int p_parameterIndex,Ref p_value)
setURL(int parameterIndex, URL x)
ResultSet getArray(int p_ColumnIndex)
getArray(String p_ColumnName)
getObject(int p_ColumnIndex,java.util.Map p_Map)
getObject(String p_ColumnName,java.util.Map p_Map)
getRef(int p_ColumnIndex)
getRef(String p_ColumnName)
public URL getURL(int columnIndex)
public URL getURL(String columnName)
public void updateRef(int columnIndex, Ref x)
public void updateRef(String columnName, Ref x)
public void updateBlob(int columnIndex, Blob x)
public void updateBlob(String columnName, Blob x)
public void updateClob(int columnIndex, Clob x)
public void updateClob(String columnName, Clob x)
public void updateArray(int columnIndex, Array x)
public void updateArray(String columnName, Array x)
Statement public void setCursorName(String unused)
public boolean getMoreResults(int current)
public int executeUpdate(String sql, int[] columnIndexes)
public int exectueUpdate(String sql, String[] columnNames)
public boolean execute(String sql, int[] columnIndexes)
public boolean execute(String sql, String[] columnNames)
Table 1: Unsupported JDBC Methods From Java.sql Package
Java.sql Class Unsupported Methods

Version 4.8 PointBase Developer 209
Appendix C: Reserved Words
PointBase reserves certain words as keywords. Reserved words cannot be used, by themselves,
as an identifier for a table, column, or index, or as a correlation name defined in a SELECT
statement, unless you delimit them. A delimited identifier is an identifier in double quotes.
Any word, including keywords, can be a delimited identifier. A reserved word can be part of an
identifier, such as DEFAULT_TABLE, as long as it is not exactly the same as the keyword by
itself.
Although CREATE TABLE (VARCHAR VARCHAR(10)) is not a legal PointBase syntax
because of the illegal use of the reserved words, “TABLE” and “VARCHAR.” The same
identifiers, however, can be legally used if they are delimited, as in CREATE TABLE
"TABLE" ("VARCHAR" VARCHAR(10)).
NOTE: The words listed here are SQL reserved words and should not be used. Some of these
keywords may not be supported in this release, but are reserved for future releases of
PointBase.
Reserved words in the PointBase database are:
ACTION
ADD
AFTER
ALL
ALTER
AND
AS
ASC
ASCENDING
AT
ATOMIC
AUTHORIZATION
AVG
BEFORE
BEGIN
BETWEEN
BINARY

PointBase
Version 4.8 PointBase Developer 210
BIT
BLOB
BOOLEAN
BOTH
BY
CALL
CASCADE
CASE
CAST
CHAR
CHARACTER
CHAR_LENGTH
CHARACTER_LENGTH
CHECK
CLOB
COLUMN
COMMIT
COMMITTED
CONSTRAINT
CONTAINS
COUNT
COUNTRY
CREATE
CROSS
CURRENT
CURRENT_DATABASE
CURRENT_DATE
CURRENT_LSN
CURRENT_PATH
CURRENT_SCHEMA
CURRENT_SESSION
CURRENT_TIME
CURRENT_TIMESTAMP
CURRENT_USER
DATA
DATABASE
DATALOG
DATE
DAY
DEC
DECIMAL
DEFAULT
DEFERRABLE

PointBase
Version 4.8 PointBase Developer 211
DELETE
DESC
DESCENDING
DETERMINISTIC
DIAGNOSTICS
DISCONNECT
DISTINCT
DOUBLE
DROP
EACH
END
EXCEPT
EXECUTE
EXTERNAL
EXTRACT
FALSE
FILTER_COLUMN
FILTER_ROW
FLOAT
FOR
FOREIGN
FROM
FULL
FUNCTION
G
GETLASTLSN
GRANT
GROUP
K
HAVING
HOUR
IMAGE
IMMEDIATE
IN
INDEX
INDEXONLY
INITIALLY
INNER
INOUT
INSERT
INT
INTEGER

PointBase
Version 4.8 PointBase Developer 212
INTO
IS
ISOLATION
JAVA
JOIN
KEY
LANGUAGE
LARGE
LEADING
LEFT
LENGTH
LEVEL
LIKE
LOB
LONG
LONGRAW
LOWER
LSN_CURRENT_ID
LSN_CURRENT_OFFSET
LSN_SKIP_ID
LSN_SKIP_OFFSET
LSN_START_ID
LSN_START_OFFSET
M
MATCH
MAX
METHOD
MIN
MINUTE
MODIFIES
MONTH
NAME
NATURAL
NEW
NO
NOT
NUMBER
NUMERIC
NULL
OBJECT
OCTET_LENGTH
OF

PointBase
Version 4.8 PointBase Developer 213
OFF
OLD
ON
ONLY
OPTION
OR
ORDER
OUT
OUTER
PAGESIZE
PARAMETER
PASSWORD
PATH
PLANONLY
POSITION
PRECISION
PRIMARY
PRIVILEGES
PROCEDURE
PUBLICATION
RAW
READ
READS
REAL
REFERENCES
REFERENCING
RELEASE
REPEATABLE
RESTRICT
RETURN
RETURNS
REVOKE
RIGHT
ROLLBACK
ROUTINE
ROW
SAVEPOINT
SCALAR
SCHEMA
SECOND
SELECT
SERIALIZABLE

PointBase
Version 4.8 PointBase Developer 214
SESSION_USER
SET
SIGNAL
SIZE
SMALLINT
SNAPSHOT
SPECIFIC
SQLSTATE
STARTSTATEMENT
STYLE
SUBSCRIPTION
SUBSTRING
SUM
SWITCHLOGFILE
SYSDATE
SYSTIME
SYSTIMESTAMP
TABLE
TEXT
TIME
TIMESTAMP
TINYINT
TO
TRAILING
TRANSACTION
TRIGGER
TRIM
TRUE
UNCOMMITTED
UNION
UNIQUE
UNISYNC
UNKNOWN
UPDATE
UPPER
USER
USING
VALUES
VARBINARY
VARCHAR
VARCHAR2
WHEN

PointBase
Version 4.8 PointBase Developer 215
WHERE
WITH
WRITE
WORK
YEAR

Version 4.8 PointBase Developer 216
Appendix D: SQL Data Type Code
This section contains a mapping of SQL data types and their corresponding type code. These
code values are based on the ANSI and ISO SQL standard.
SQL Data Type
Type Code
BLOB 30
BOOLEAN 16
CHARACTER 1
CHARACTER VARYING 12
CLOB 40
DATE 91
TIME 92
TIMESTAMP 93
BIGINT 9
DECIMAL 3
DOUBLE PRECISION 8
FLOAT 6
INTEGER 4
NUMERIC 2
REAL 7
SMALLINT 5
BINARY 121
VARBINARY 122
LONGVARBINARY 123

PointBase
Version 4.8 PointBase Developer 217
LONGVARCHAR 124
SQL Data Type
Type Code
